打造万物识别之利器——微信扫一扫植物识别篇

导语
背景介绍
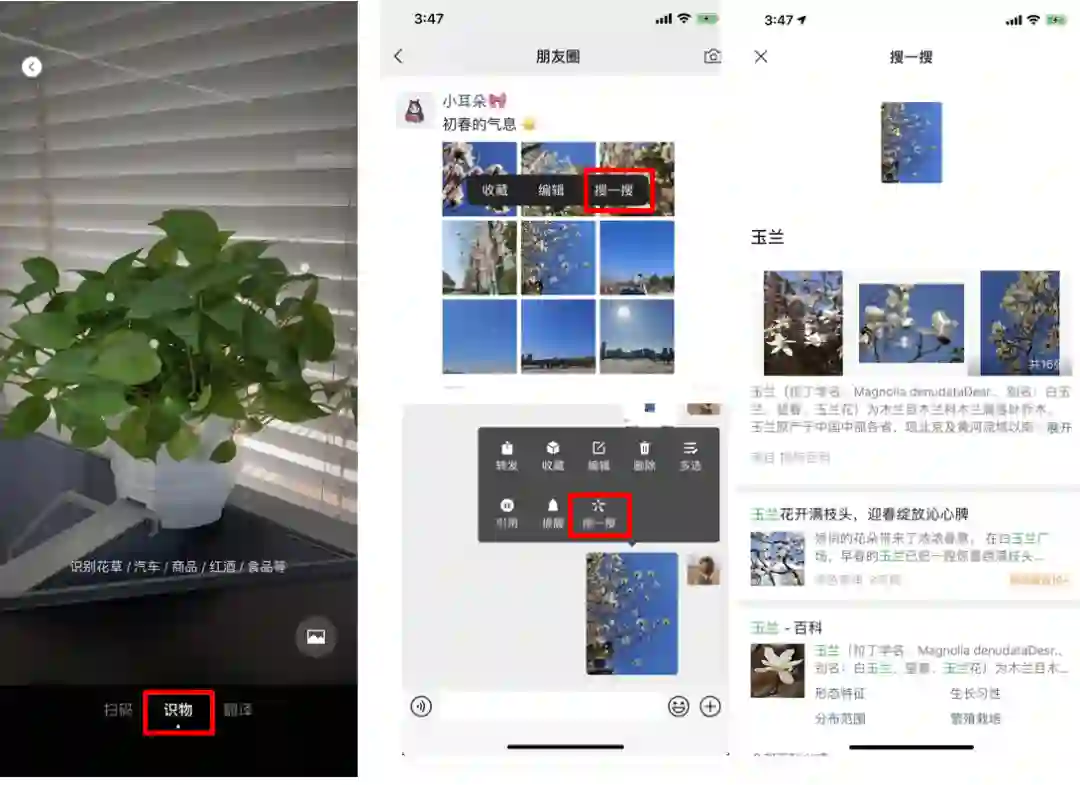
扫一扫识花难点与挑战

■ 类内差异大;
■ 类间混淆度高;
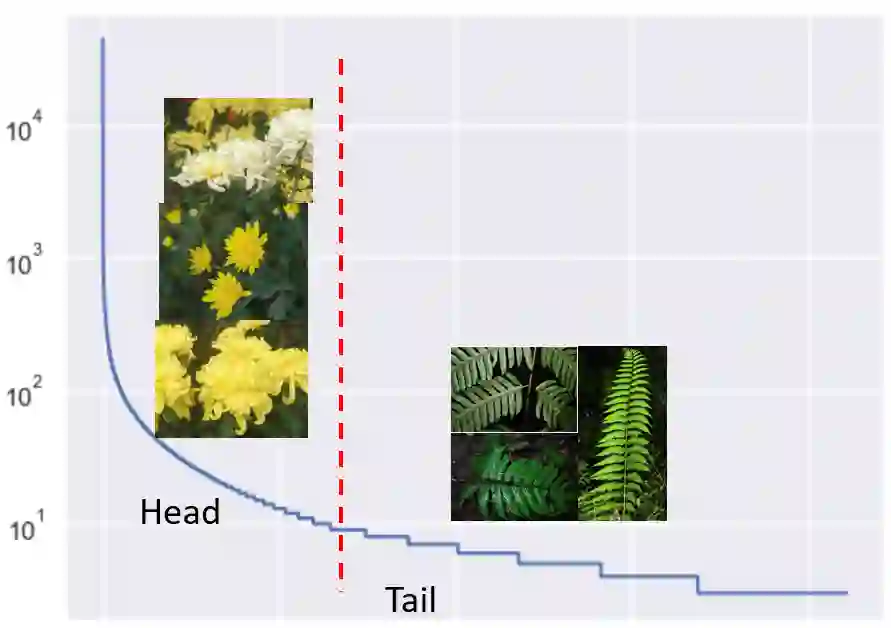
■ 数据分布不均衡,长尾分布严重。
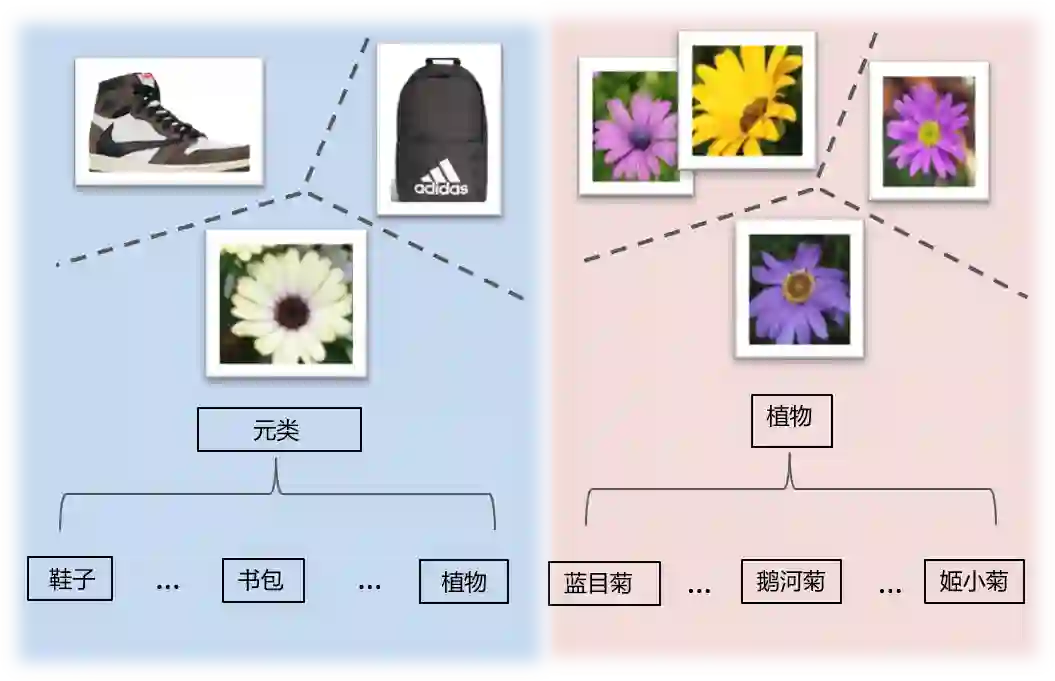
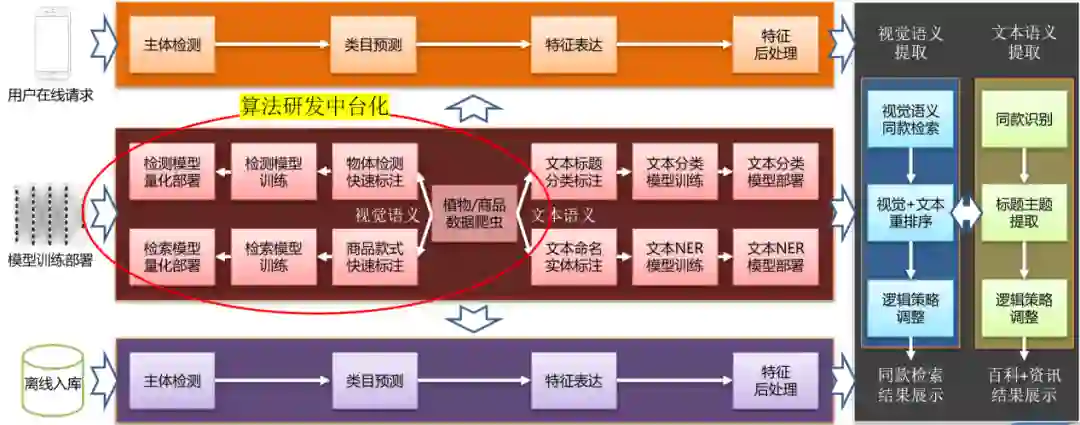
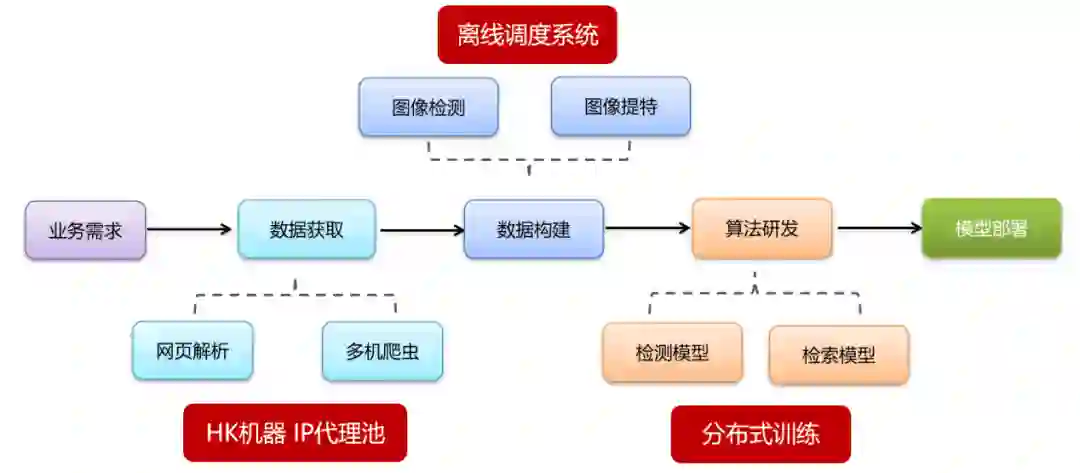
扫一扫识花解决方案
■ 基于图像分类网络微调的方法,如AlexNet、GoogleNet、ResNet以及DenseNet等;
■ 基于细粒度特征学习(fine-grained feature learning)的方法, 如Bilinear CNN等;
■ 基于目标块的检测(part detecetion) 和对齐(alignement)的方法, 如Part-RCNN等;
■ 基于视觉注意机制(visual attention)的方法, 如 RA-CNN等。


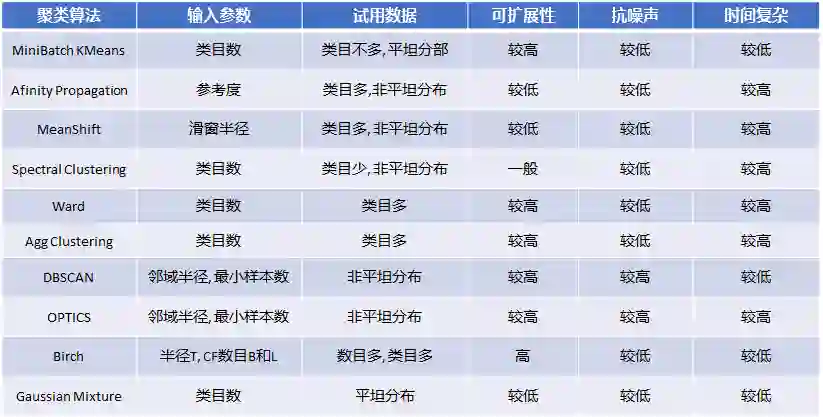

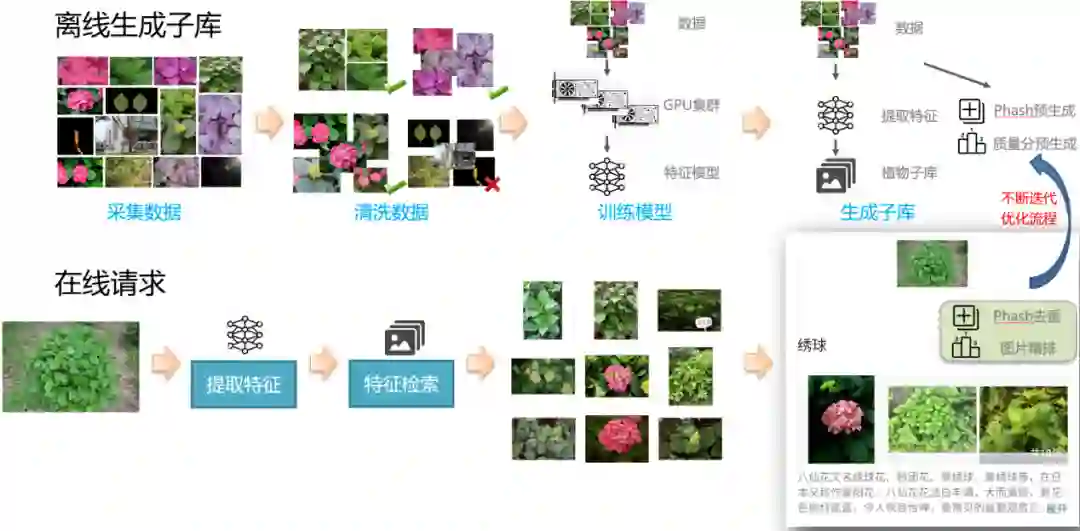
■ 基于上面的聚类去噪方法对所有类进行类内进行去噪。
■ 从去噪之后的类目里面,按照2:1的比例划分query/gallery集和噪声集。
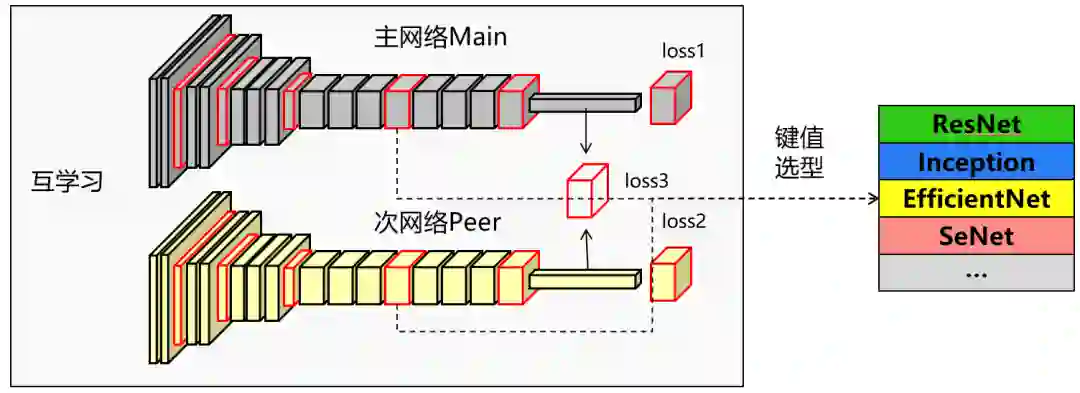
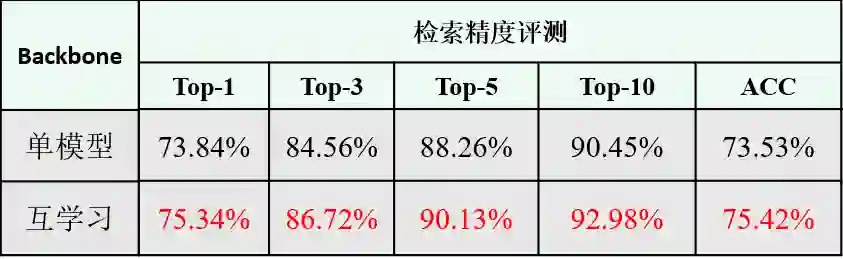
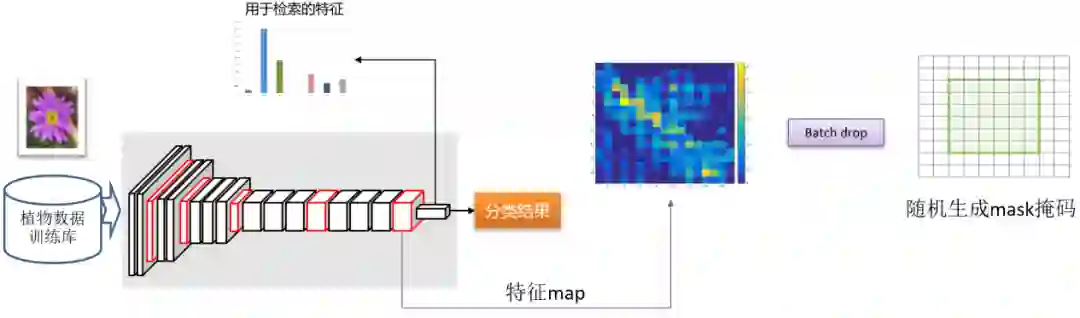
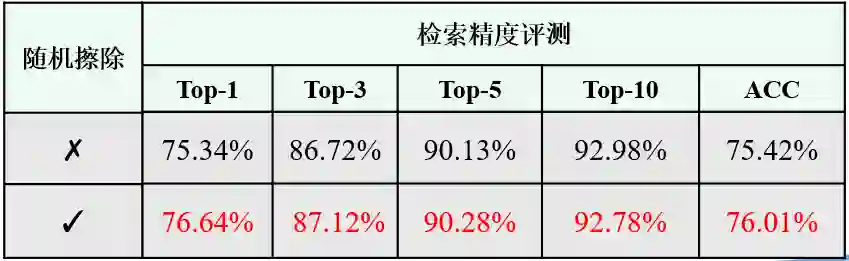



总结与展望
微信AI
不描摹技术的酷炫,不依赖拟人的形态,微信AI是什么?是悄无声息却无处不在,是用技术创造更高效率,是更懂你。
微信AI关注语音识别与合成、自然语言处理、计算机视觉、工业级推荐系统等领域,成果对内应用于微信翻译、微信视频号、微信看一看等业务,对外服务王者荣耀、QQ音乐等产品。
登录查看更多
相关内容
Arxiv
0+阅读 · 2022年4月16日
Arxiv
0+阅读 · 2022年4月15日




相关VIP内容
相关资讯