微信看一看如何过滤广告文章?

导语
本文对看一看中广告识别工作进行了介绍,从问题定义出发,划分成文字,图片以及文章结构等多个维度来完成对问题拆解。在文字和图片部分,分别介绍了如何通过模型有效的对广告区域进行识别和定位。然后是如何融入文章结构特征可视化输出,最终实现一个基于多模态的广告文章识别系统框架。
背景介绍
在微信生态体系下每天都会产生大量的文章数据,个别垃圾文章掺杂其中。这些垃圾文章如果出现在看一看中会影响用户的阅读体验,而广告文章作为其中一个占比最大的垃圾子类型值得重点关注。对此我们构建了一套完整的广告识别系统来对严重广告垃圾文章进行过滤。
问题挑战
■ 2.1 广告文章的定义
先来认识一下什么是广告文章,广告的类型是多种多样的,具体可以划分为以下几种类型(该分类依据系统策略,而并非法律或严格意义上的广告文章):
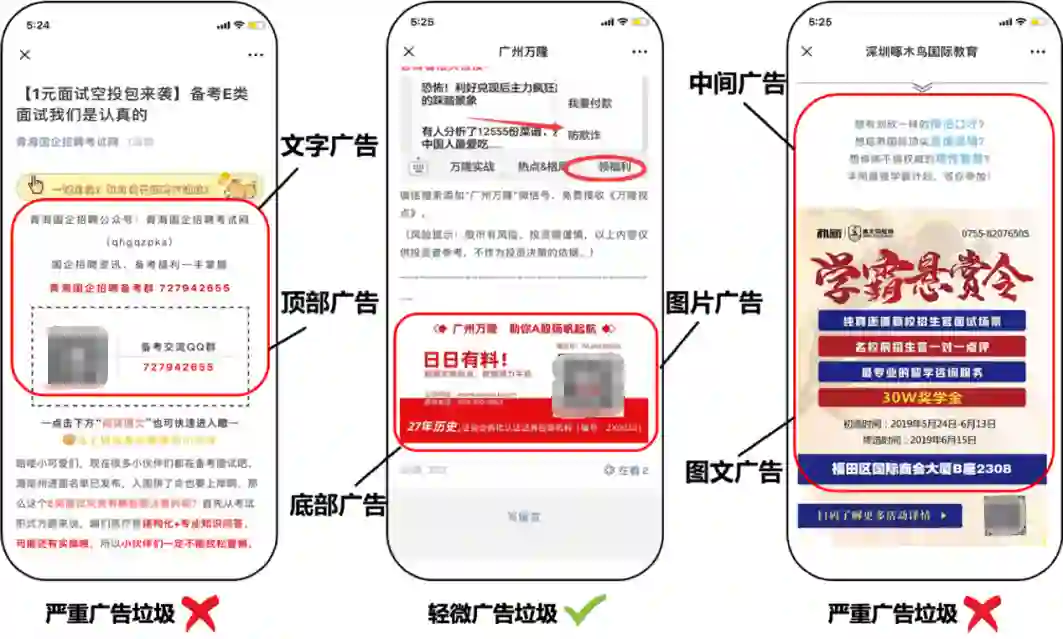
· 多模态,不仅有文字广告和图片广告,还有图文并茂的图文广告。
· 位置不固定,根据相应的位置可以划分为顶部广告,中间广告和底部广告。不同位置出现的广告对用户阅读体验影响也存在很大差别,比如对于顶部广告,用户点击文章后马上就会看到,很容易引起反感,而文章出现底部广告则更容易被接受。
· 广告区域占比,如果文章大部分都是广告我们会认为是主体广告,与之相反就存在仅由2,3句话组成占比很小的插播广告。
· 出现次数不固定,在一篇文章中可能出现多个广告区域,比如同时出现顶部和底部广告。
■ 2.2 广告识别的挑战
从业务上,首先不仅要识别广告文字和广告图片,还需要定位广告区域的位置。其次并不是文章中出现广告就需要过滤,还需要考虑整体文章的结构和占比。比如中间这篇文章,它的广告出现在底部且占比小,对用户阅读体验影响不大是可以放过的。而最右边这篇文章中间出现了大片图文广告属于严重广告垃圾需要过滤。
从模型方法上,广告垃圾文章的识别显然是一个经典的多模态二分类问题,如果直接采用端到端的深度模型就会产生组合爆炸,而且需要大量的标注样本,最终模型的可解释性也会很差,出现问题难以定位。如果是基于规则策略,虽然比较直观明了,但是广告识别涉及的特征维度众多,单纯规则难以适应,后期很难维护。
广告识别系统框架
针对这些问题和挑战,我们构建了基于多模态的文章广告识别系统,结合了文本、图片和文章结构特征,可以有效的综合多个角度对文章中的广告区域进行细粒度的刻画,并且支持相应的可视化展示,从而实现对严重广告垃圾文章过滤。它的主体思想就是首先通过广告文字检测模型和广告图片识别模型完成对广告区域的识别和定位,然后再结合文章结构特征通过广告文章序列模型进行整体判断。具体框架如下图所示,下面分三个部分来分别阐述:
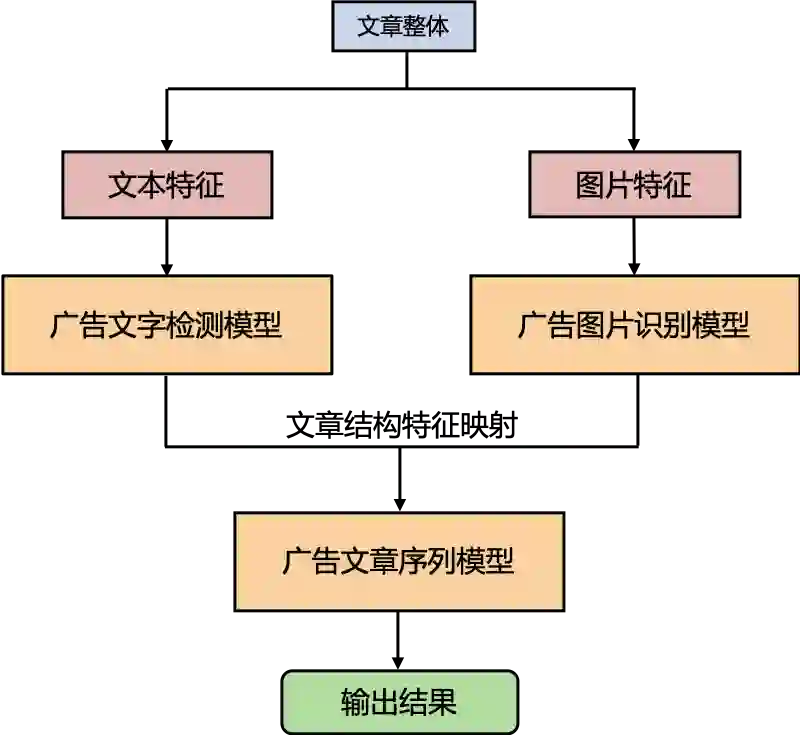
广告识别系统整体框架
■ 3.1 广告文字的检测
我们发现线上问题只有小部分是主体广告,这类文章的绝大部分都是广告文字,用一般的文本分类方法就可以很好解决,比如LR+TFIDF。但剩下大部分的问题都是插播广告。它们平均广告占比甚至不到全文十分之一,传统的文本分类方法很难识别出隐藏在大段正常文本中的小段广告文字。此外在我们场景下,还需要对每一段广告文字进行定位。这两个任务综合在一起就使问题变得更加复杂。
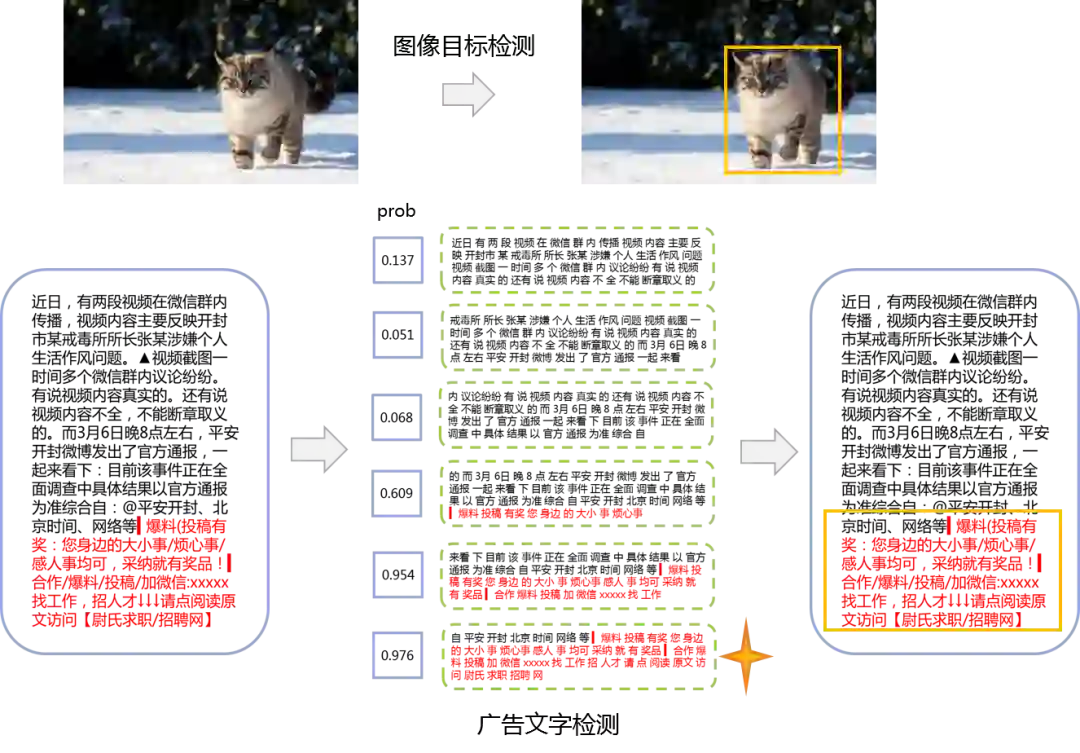
然而我们任务其实和图像中的目标检测相似,都是需要识别相应的目标和它对应的位置,只不过广告识别相当于从二维变到了一维。受到其中的启发,我们提出了一个全新的模型TADL,大体思想是通过滑动窗口的检测方法将大段文本切分成多个小片段,并对每个小片段进行广告概率打分和反推定位,从而在一个模型框架内同时实现了广告文字的识别和定位,并且只需要文章级别的标注就能完成训练。具体模型框架如下图所示,在模型迭代过程中我们主要解决了以下3个挑战:
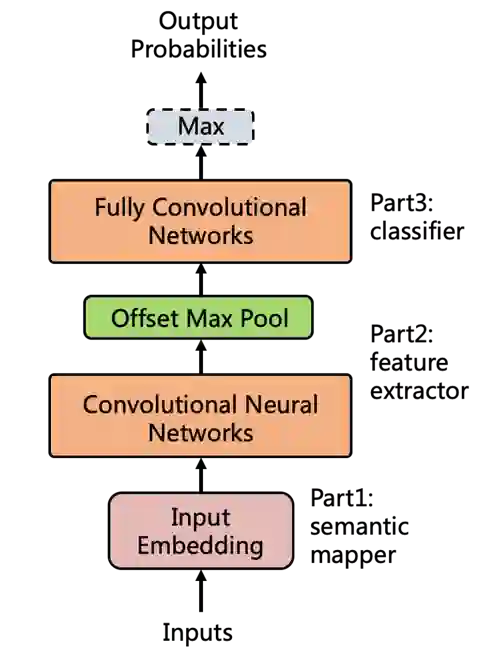
TADL模型
▍挑战一:如何在文章级别标注下实现广告文字检测?
(a)局部特征提取:CNN & Offset Max Pool
在模型中我们以CNN为主体架构,利用CNN强大的局部特征提取能力抓取文章不同区域下窗口的局部特征,但是传统cnn的窗口切分方式是固定单一的,而我们的文本片段是连续的有多种切分方式,所以我们引入了offset max-pool来获取更多的不同窗口切分方式的组合, 这不仅增强了特征表达,还实现了相邻窗口平滑过渡。
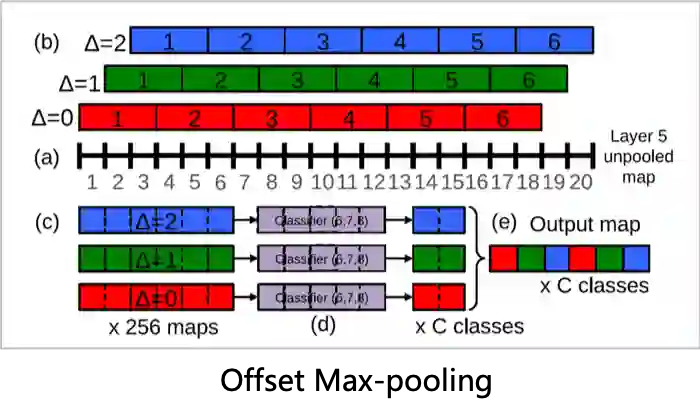
(b)滑动窗口检测:FCN
提取完各个窗口片段特征后,如果我们使用全链接层来对每个片段进行广告概率打分,计算量会很大,为了简化计算,我们利用CNN共享参数的机制将全链接层都替换为卷积核为1的全卷积层实现分类,在这种情况下只需要经过一次正向的CNN就能同时获得所有片段的概率得分 ,避免了全链接层的重复计算,同时使得模型能支持变长的输入输出。

(c)文章级别输出:Max
得到所有片段的广告概率之后,由于标注人力的限制 我们不可能去标注所有的片段是不是广告文字,所以在训练的时候当作是文章级别的二分类任务,通过取max表示文章是否包含广告文字,模型就能自动学习对广告文字识别和定位,而在模型使用阶段,我们不再做文章级别的判断,只需要max之前的各片段的广告概率即可。
最后,我们可以根据CNN的参数反推概率得分在文章中所对应的片段位置。
▍挑战二:如何平衡局部信息和全局信息到最优?
(a)全局信息的引入:Transformer
在分类任务训练的时候我们发现模型的召回很高而精度较低,对于那种小编推荐类的文章,很容易出现某几个关键词就会引起误召回,但从全文来看文章并没有包含明显的广告信息。这是因为CNN只关注了局部信息而忽略了全局信息的作用,但是由于需要从模型计算的结果中反推出原始片段的区域位置,所以在引入全局信息的时候最好不要打乱原来的输入和输出的对应关系。于是我们选择从最开始的词向量中引入全局信息。比如position embedding和tranformer引入都使模型取得显著提升。值得注意的是如果引入的全局信息过多,就会使得局部信息作用非常有限,召回就会降低。具体如下图所示:
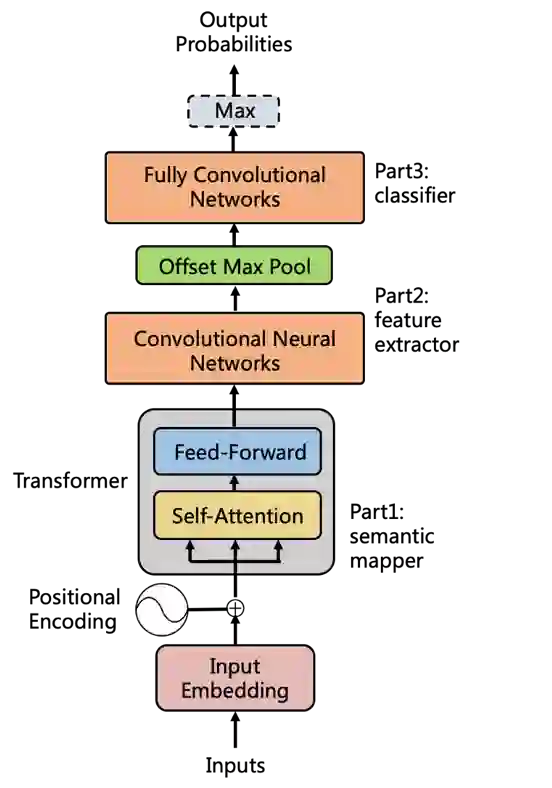
TADL模型全局信息引入
(b)局部信息的调整
另一方面还可以通过调整滑动窗口大小和步长来调节局部信息的获取,如果窗口过大,全局信息变多,就难以识别小段广告,窗口过小,局部信息则会过于敏感而引起误召回。
通过这一系列的参数调整使得全局信息和局部信息产生博弈,最终达到效果最优。
▍挑战三:如何加速优化模型并支持超长文本输入?
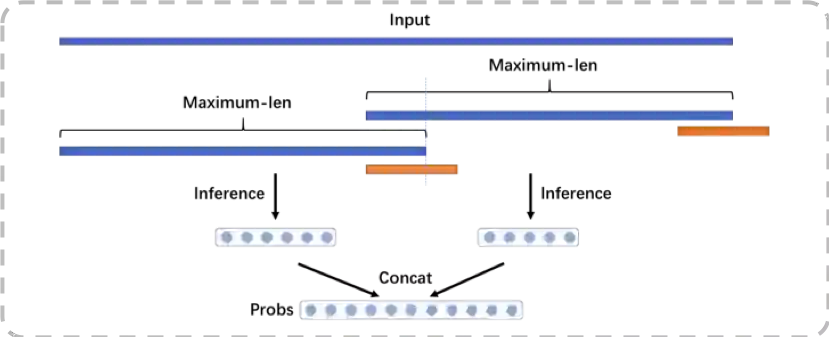
(a)超长序列预测:Multiple Segments Inference
Transformer内部矩阵的计算是有长度限制的,测试发现序列输入超过一定长度就会内存溢出,而我们文章的输入长度range是非常大的,如果直接截断会丢失大量信息。所以在工程上我们也做了很多优化,在预测的时候采用了分段预测的方法,如下图所示。通过这个方法我们的模型可以支持任意长度的输入。
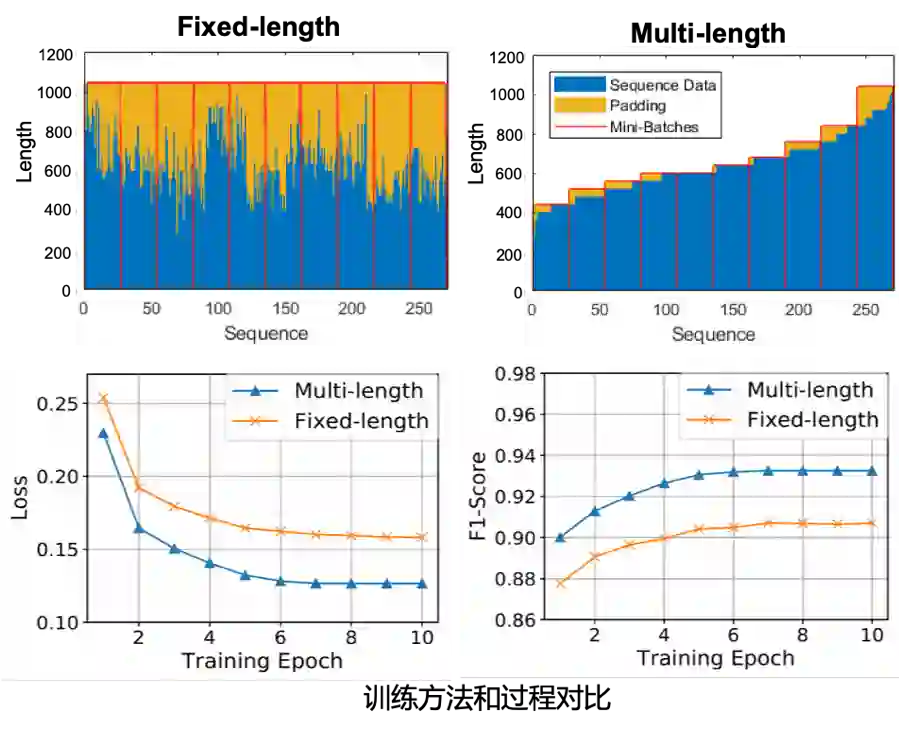
(b)训练加速:Batch Sequence Padding
输入Range过大给训练阶段也带来了困难,一开始我们采取的是定长训练,需要补齐大量的padding来计算,训练时间较长。为了减少不相关padding的干扰,我们采用了Batch Sequence Padding的方法,即让相同长度的序列尽可能的放在同一个batch中实现变长训练。这种做法不仅大幅度减少输入长度,缩短训练时间,还显著提升了模型效果。
■ 3.2 广告图片的识别
广告图片的定义是非常宽泛的,像穿衣模特和商品特拍,甚至是广告文字和二维码都有可能被认定为广告图片。并且图片的特征维度众多,比如下面的例子,在同一张图片中同时出现了多个维度的特征。另外文字大小和位置和文本语义也存在关联,比如业务热线只要出现在图片中不管大小都会被认为是广告图片,而右边的价格,只有在占比很大的情况下才会被认为是广告图片。这一块是和优图一起合作的,一开始的方案是将广告图片识别作为了一个端到端的图片分类问题,采用了依赖大规模标注的深度模型,这种方法可解释性较差,并且实际使用上效果有限。

针对这些问题和挑战,我们在优图的基础之上结合业务特点进行了优化,采用基于wide&deep模型分而治之。如下图所示:
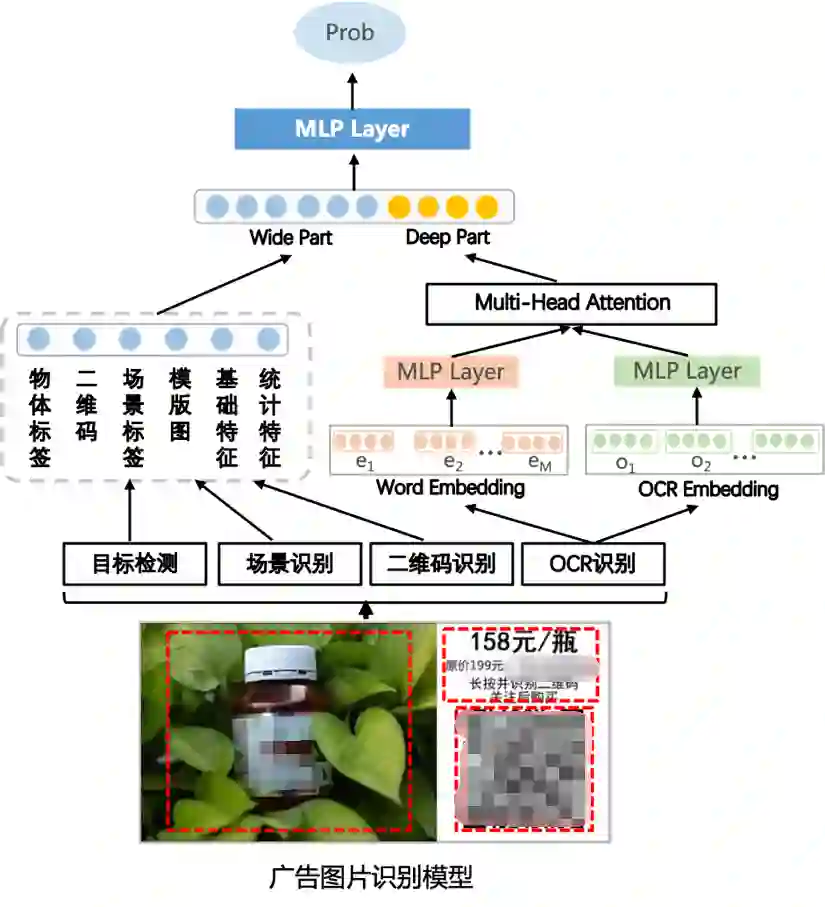
a) Feature Engineering
首先对图片的多个维度进行拆解,划分成多个不同特征提取模块,包括目标检测,场景识别,二维码和OCR识别,并不断完善丰富各个维度下的标签种类。这样就能获得各种数值型特征和文本Embedding特征。
b) Wide & Deep
这两种类型的特征非常适合wide&deep模型联合学习,并且在我们的业务场景下,性能上有一定要求,而wide&deep模型结构简单非常适合大规模样本预测的场景。
c) Multi-Head Attention
通过多头注意力机制来学习文字块大小和文本语义组合之后的语义关系,进一步提升效果。
■ 3.3 广告文章序列分类
▍3.3.1 文章多模态分类转化成序列分类问题
通过广告文字检测模型我们可以获取不同区域文本片段对应的广告概率,通过广告图片识别模型我们可以得到图片的广告概率,将二者的结果按文章排版顺序组合起来就可以将每一篇文章都转化成一条广告概率序列。我们将文章位置做横坐标广告概率为纵坐标作图对广告序列进行可视化展示,在下面图中可以直观的看到不同广告文章中有哪些广告区域以及占比,并呈现出不同的序列模式。这相当于我们将一个复杂的多模态文章分类问题转化成序列分类问题,通过前两个模型提取出高层次的广告概率特征来进行特征降维。我们通过观察可以发现严重广告文章主要集中在顶部区域或者比例过大等有限的几种序列模式。这就大大降低了问题的复杂度,避免了多模态端到端分类的组合爆炸,并且模型的可视化具有很高可解释性。
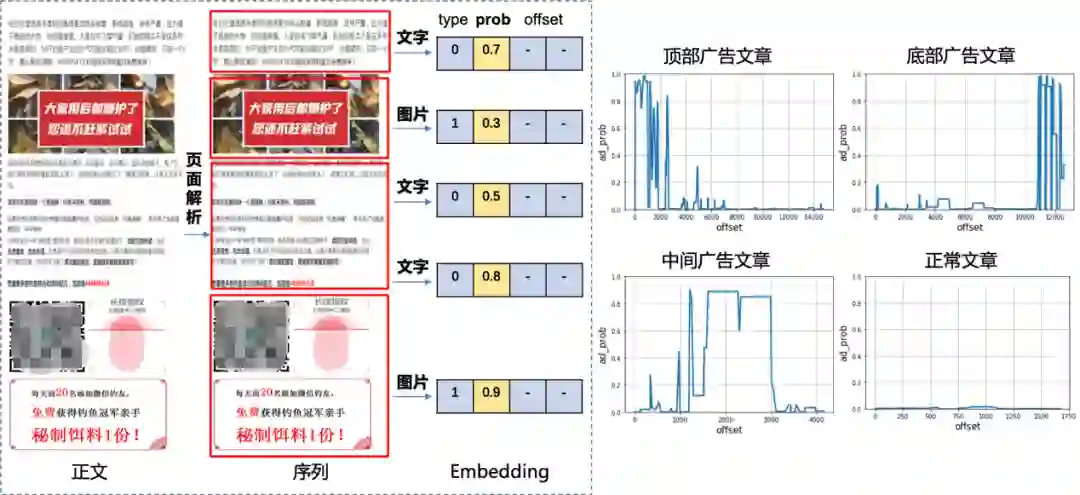
文章序列可视化
▍3.3.2 如何识别广告序列模式?
针对这个问题我们采用了LSTM+CNN组合的方式进行建模,如下图所示:
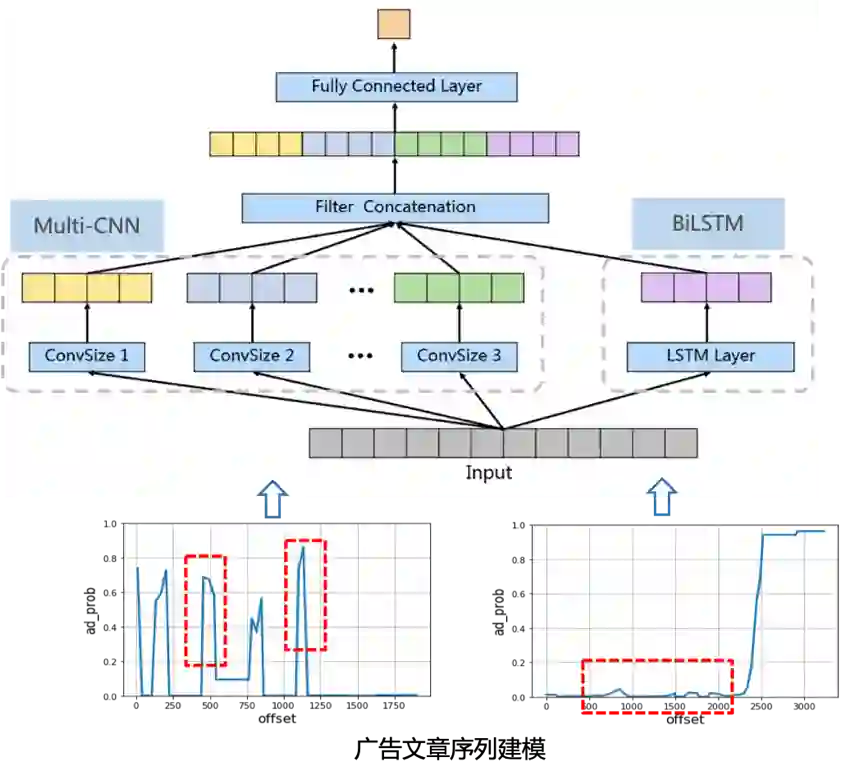
a) BiLSTM: 拟合广告序列的连续变化趋势,比如文章中间一般很少出现广告
b) Multi-CNN: 利用其强大的局部特征提取能力来捕捉广告区域的异常突起,并且通过不同卷积核大小来捕捉不同宽度和高度的突起,从而识别各种不同的广告区域类型。
最后我们将二者提取的特征向量拼接进行分类判断文章是否是严重广告垃圾文章。
■ 新的挑战:模型的效果和性能存在瓶颈
▍挑战1:模型无法有效判断广告区域位置
看下面的case,前面是两张图片占比很大,底部文字广告文字可以放过,但模型还是将它误召回了,分析后发现我们输入的序列位置特征不是等间距的,这违背了RNN/LSTM的使用前提,像一句话为什么能用这些序列模型建模,首先一个前提就是一句话的每个词显然是等间距的。后来我们将多模态位置特征统一,图片打散之后有效的解决这问题,模型效果取得了显著提升。
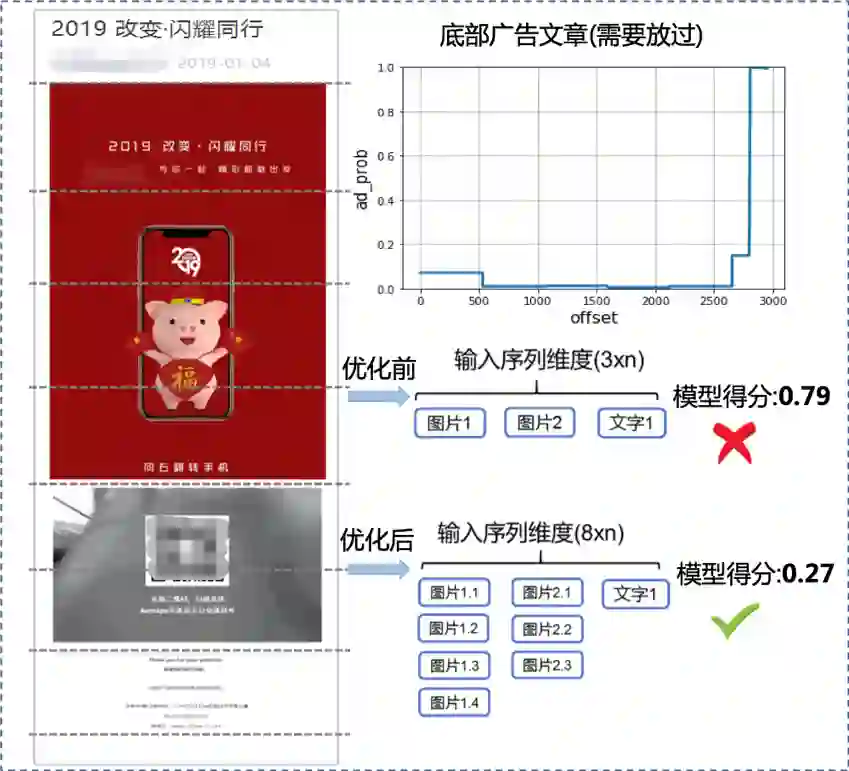
▍挑战2:文章序列过长导致模型性能较差
紧接着图片打散又大幅度增加了序列输入的长度,双向LSTM预测2000长度的序列非常慢,如何在兼顾效果和速度?我们观察后发现现在的单点输入其实就是文章固定位置上的广告特征,本质上只需要模型学习到从文章顶部到底部权重是不断降低就行了,可以直接用dense来替换双向LSTM,实验结果也表明我们在效果不变的情况下,单篇耗时极大幅度缩短。
总结与思考
■ 算法模型的更新迭代很大程度依赖于特征工程
整个系统框架不是一蹴而就的,在一开始的阶段,由于提取特征有限,我们也是采取基于规则策略的方法先解决业务问题。而随着业务理解的不断深入,解决问题所需要的特征维度也越来越多,单纯规则已经难以适应,这时候才开始用模型来拟合这些特征,并且通过进一步的特征分析来确定模型方案。每当出新问题时,首先都是分析是否有特征能区分,然后挖掘新特征,最后根据特征选择技术方案,形成闭环循环迭代,不断优化完善整个系统。
■ 复杂问题需要分而治之
有的问题并不是能通过单个维度的特征来解决,比如广告文章和广告图片的识别都是很多特征维度组合形成的复杂问题。如果直接采用端到端的深度模型,最终在效果和性能上都不一定适用。所以尽可能的先对问题进行拆解,划分成多个子问题来各个击破,反而能取得意想不到的效果。
■ 图像和NLP之间相互借鉴
现如今已经不少图像领域中的trick在nlp中得到应用,比如focal loss等。广告文字检测的方法也是从图像中滑动窗口检测算法中衍化出来的。但是领域之间还是有一定差别的,不能直接照搬。比如图像中可以通过放缩得到同样大小的样本输入,而文本却不行。所以在这个过程中我们也做了很多适配和创新。
■ 模型效果和性能之间的平衡
模型的效果决定解决问题的多少,而模型的性能直接决定能不能上线。这里涉及到很多工程优化方面的工作,包括模型架构调整,特征工程优化,实现负载均衡等。毕竟我们的算力不是无限的,而是需要在有限资源的情况下解决业务问题。通过解决这些问题不仅能加深我们对模型框架的认识和理解,还能扩展对整个系统架构的认知。
微信AI
不描摹技术的酷炫,不依赖拟人的形态,微信AI是什么?是悄无声息却无处不在,是用技术创造更高效率,是更懂你。
微信AI关注语音识别与合成、自然语言处理、计算机视觉、工业级推荐系统等领域,成果对内应用于微信翻译、微信视频号、微信看一看等业务,对外服务王者荣耀、QQ音乐等产品。