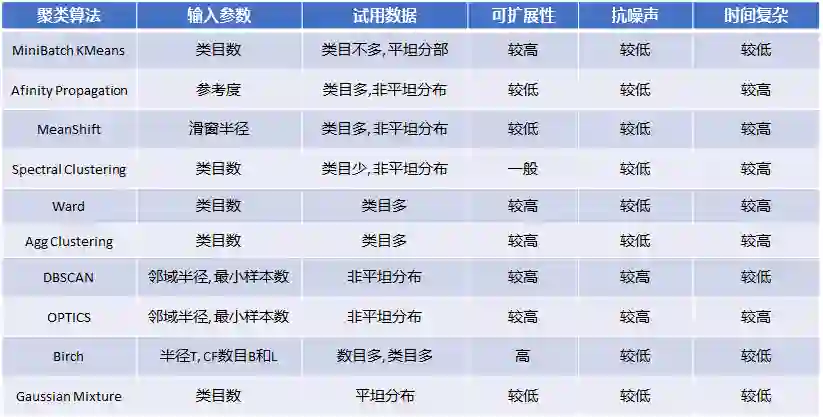
微信扫一扫识物技术的从0到1

前不久的首届广州直播节,用户只需打开手机微信的“扫一扫识物”扫描广州塔,即可进入广州直播节的小程序,直达一个72小时不打烊的“云购物天堂”。
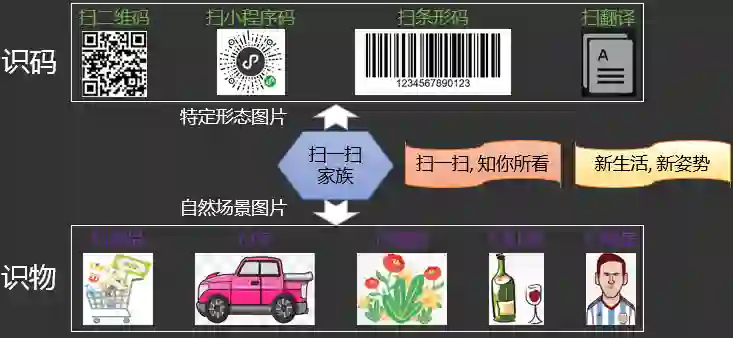
在这背后,是微信扫一扫识物技术从识别特定编码形态的图片如二维码/小程序码到精准识别自然场景中商品图片的巨大技术进步。它是如何实现的?过程中又有哪些难点需要克服?在未来又会催生哪些新的落地场景?我们用1万多字告诉你答案。
扫一扫识物概述
1.1 扫一扫识物是做什么的?

1.2 扫一扫识物落地哪些场景?
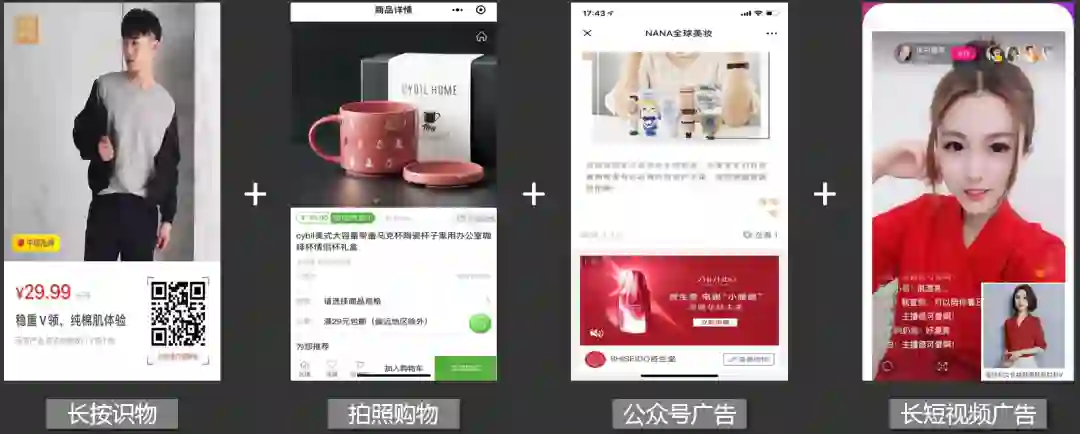
1.3 扫一扫识物给扫一扫家族
带来哪些新科技?
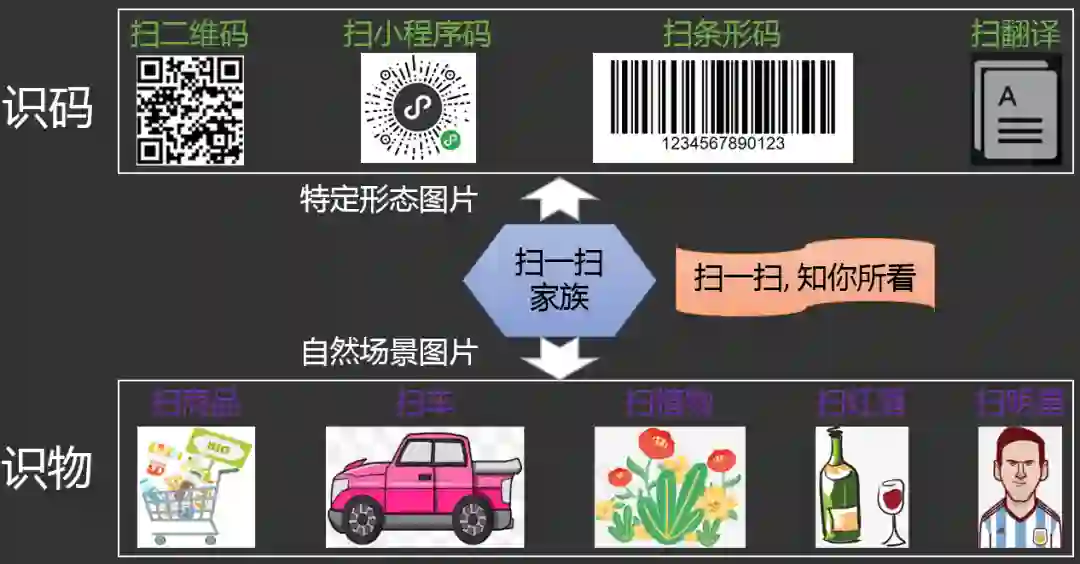
扫一扫识物技术解析
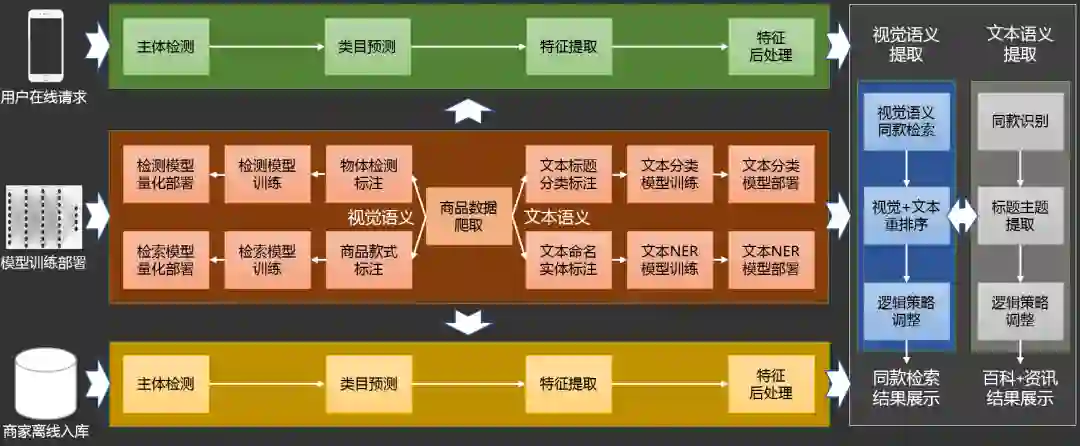
2.1 扫一扫识物整体框架
1)用户请求环节;
2)商检离线入库环节;
3)同款检索+资讯百科获取环节;
4)模型训练部署环节。
2.2 扫一扫识物数据建设
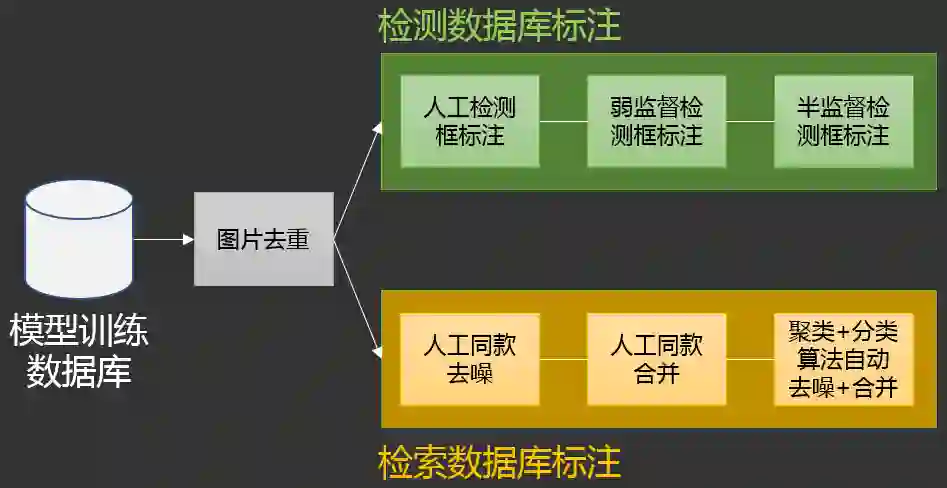
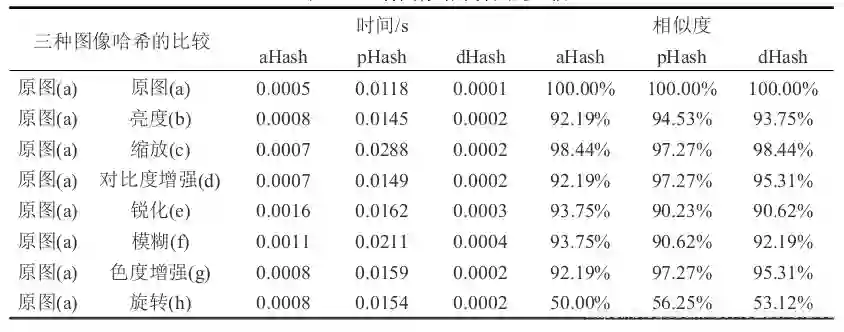
2.2.1 图片去重
2.2.2 检测数据库构建


2.2.3 检索数据库构建

2.2.3.1 同款去噪
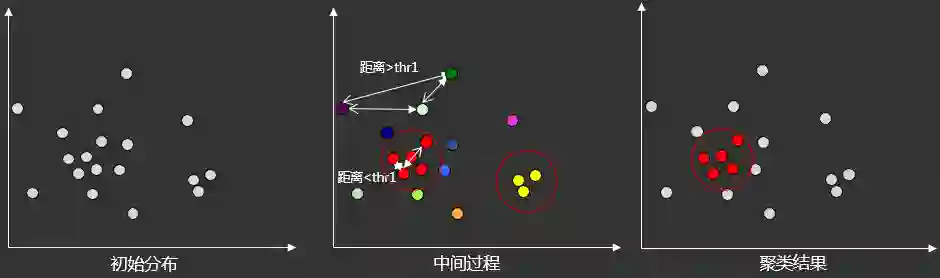

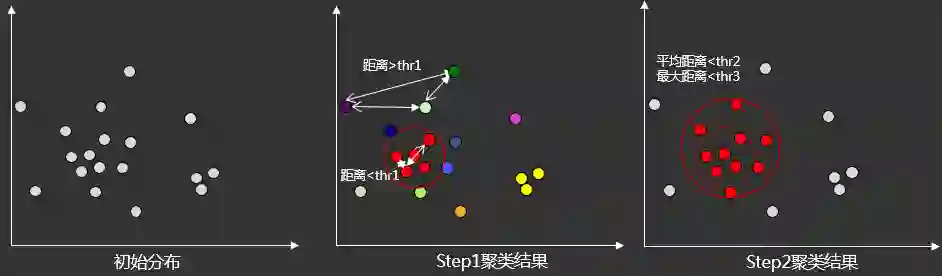
2.2.3.2 同款合并
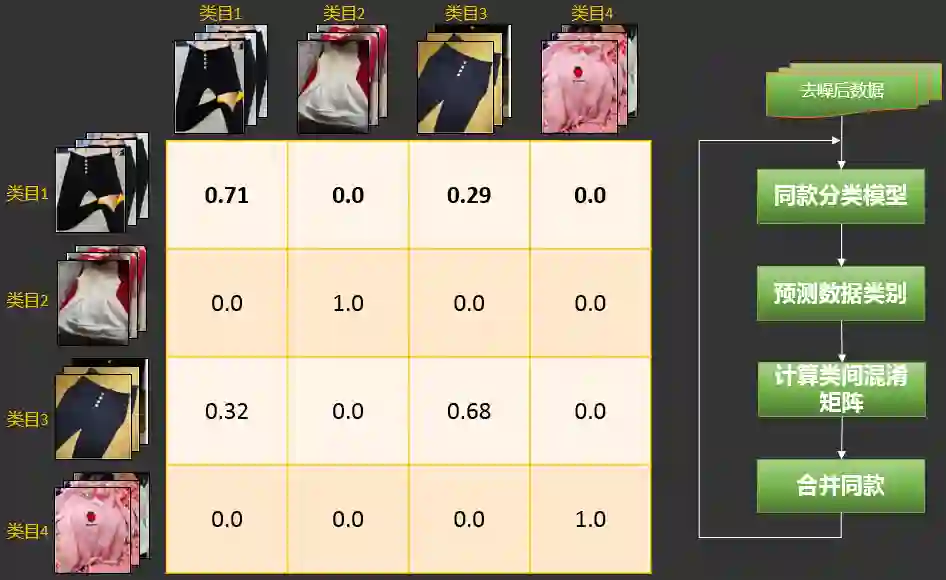
2.2.3.3 成本收益
2.3 扫一扫识物算法研发
2.3.1 物体检测
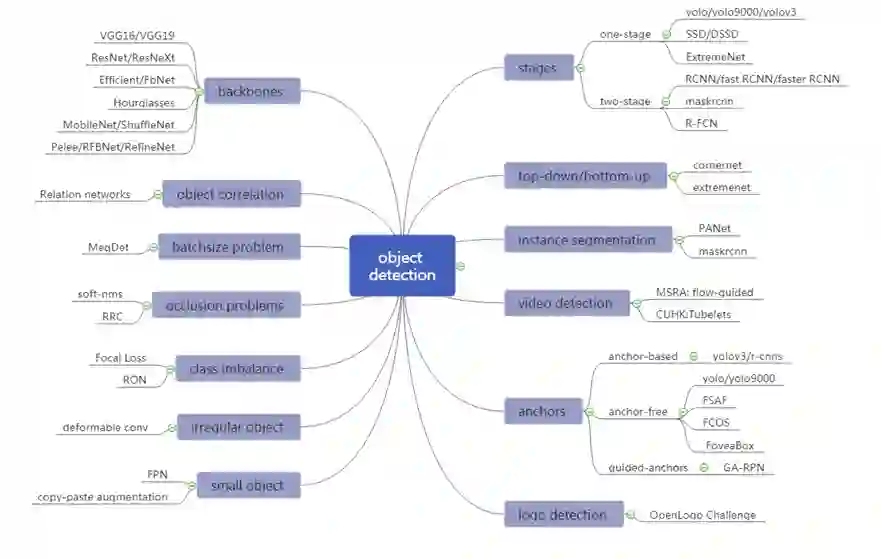
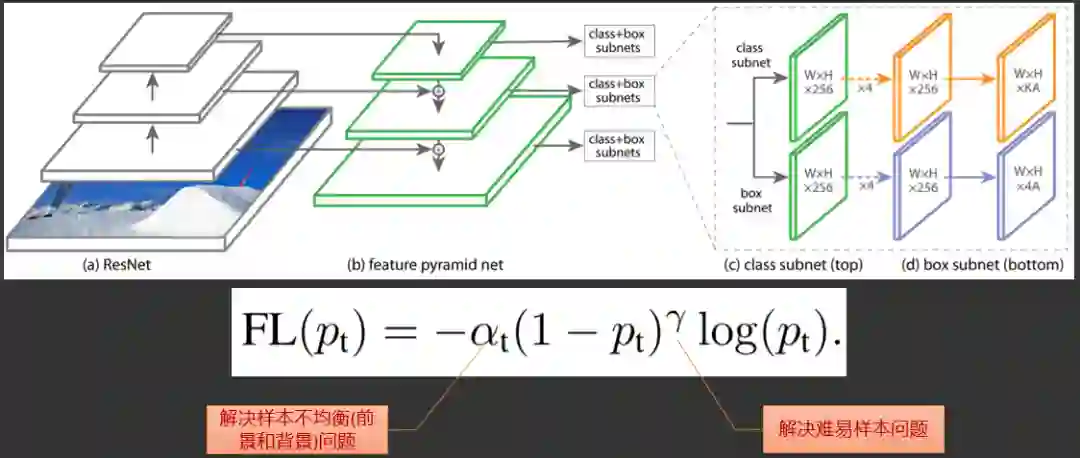
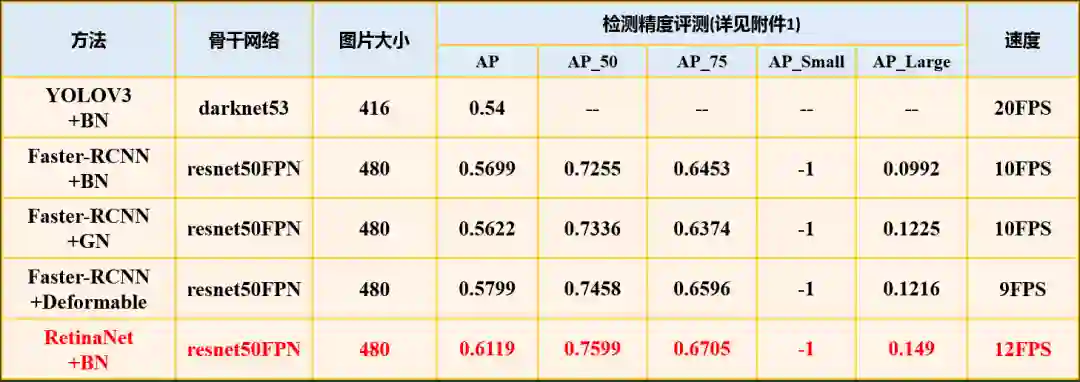
2.3.2 类目预测
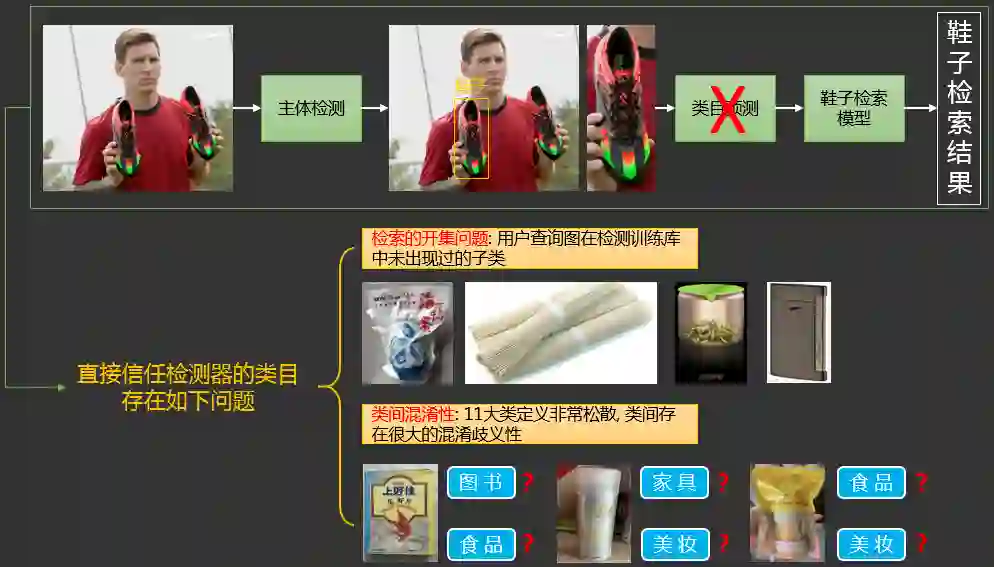
2.3.3 同款检索

2.3.3.1 同款检索之分类模型
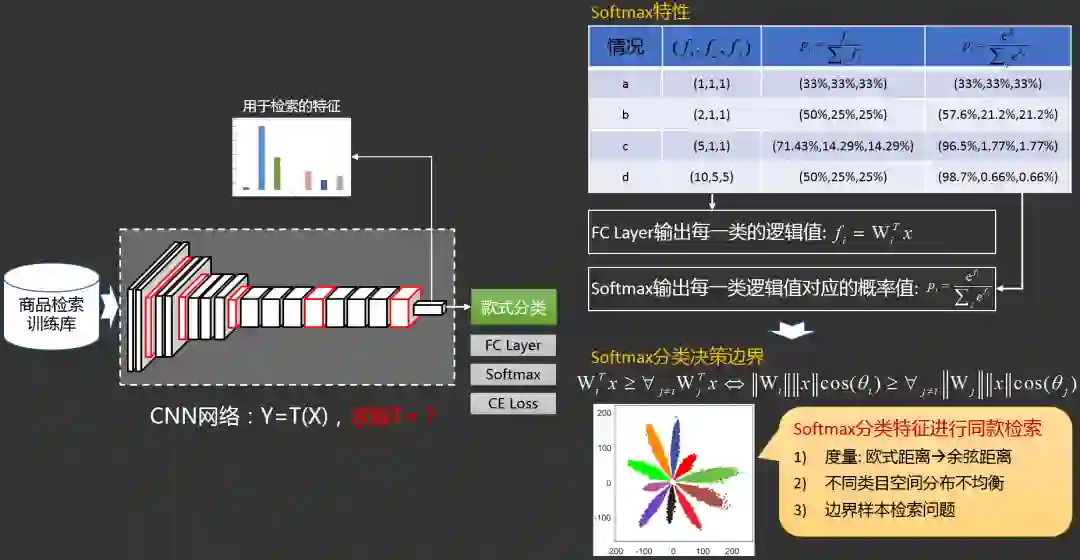
2.3.3.2 同款检索之
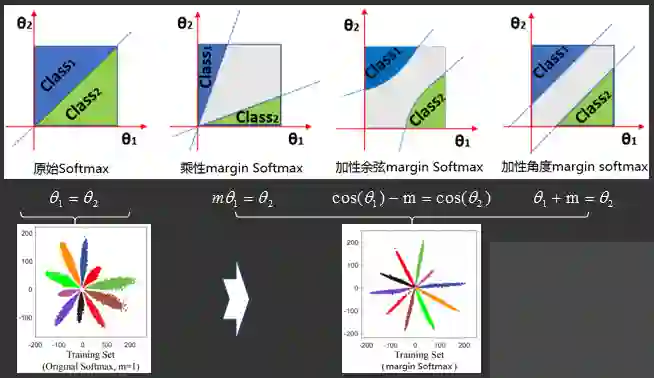
分类模型改进1归一化操作
 :
:
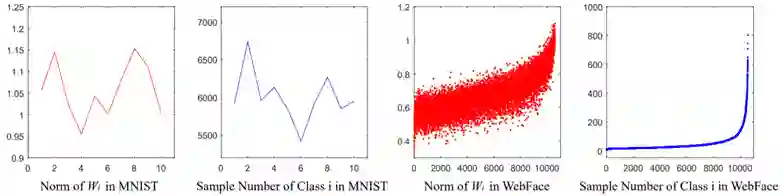
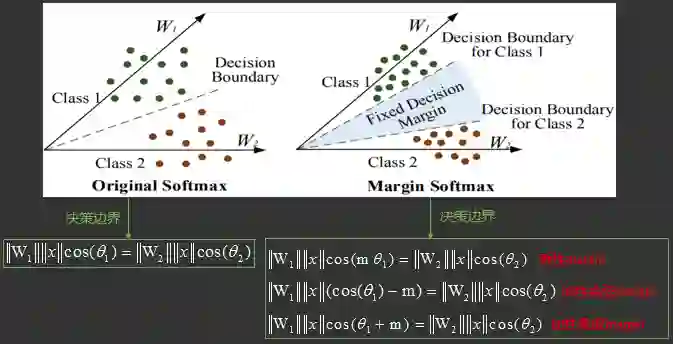
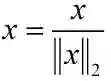 ,回顾softmax分类的决策边界:
,回顾softmax分类的决策边界:
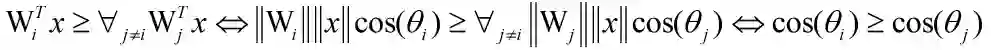
2.3.3.3 同款检索之
分类模型改进2角度Margin
2.3.3.4 同款检索之
分类模型改进3排序损失
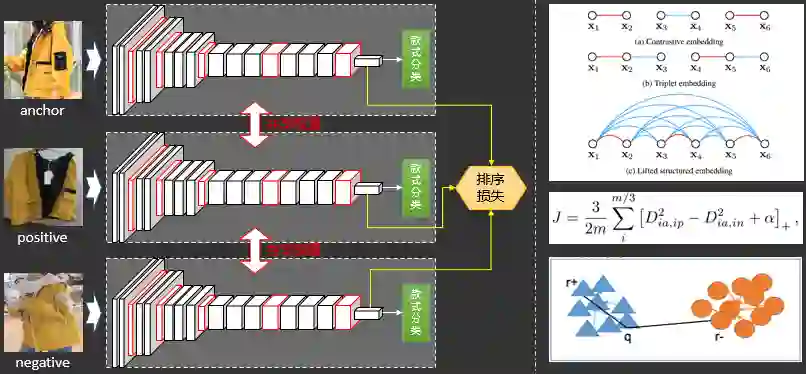
2.3.3.5 同款检索之
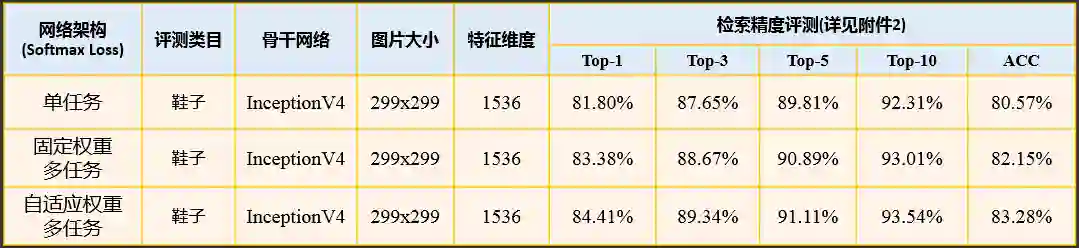
分类模型及其改进后性能对比

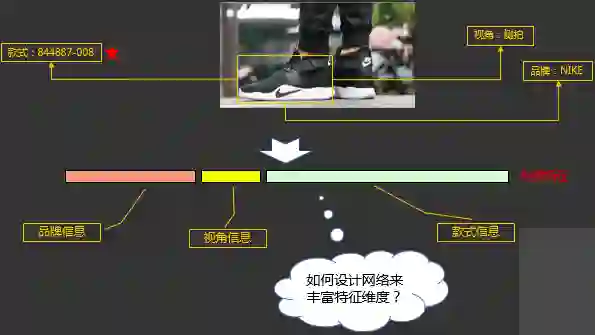
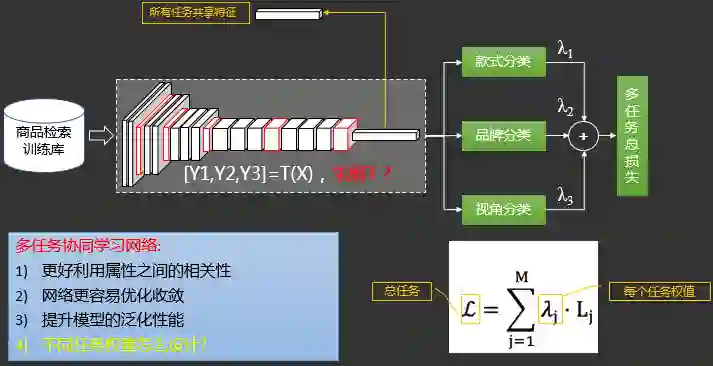
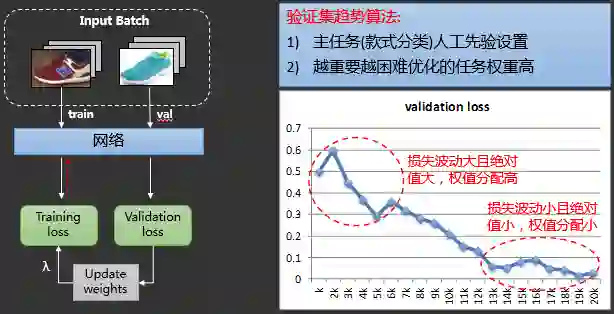
2.3.3.6 同款检索之多任务模型
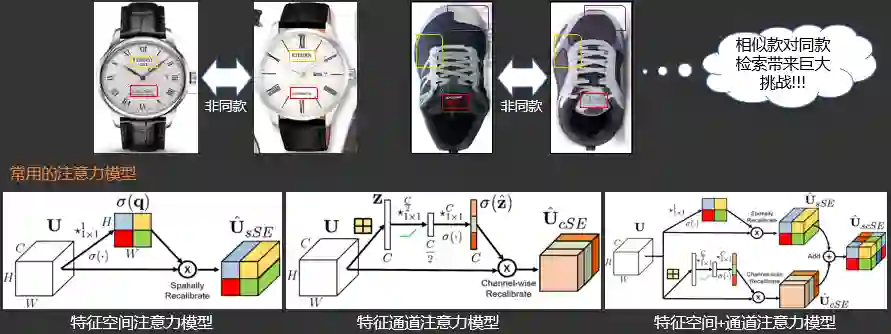
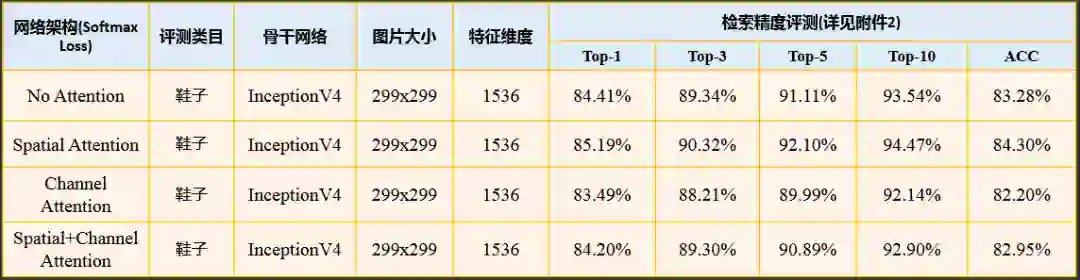
2.3.3.7 同款检索之注意力模型
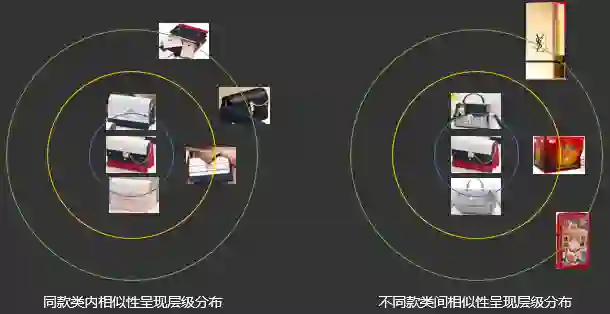
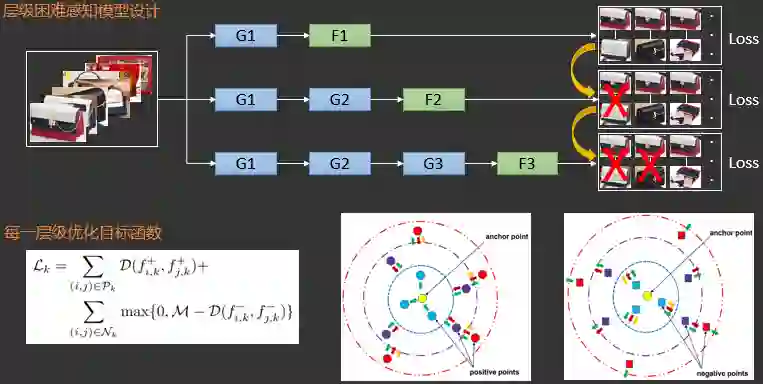
2.3.3.8 同款检索之层级困难感知模型

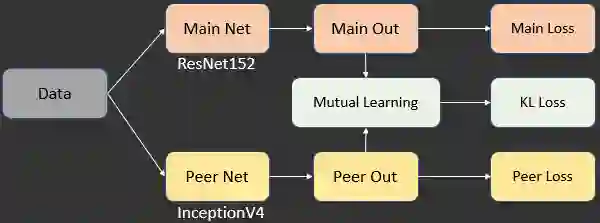
2.3.3.9 同款检索之互学习模型

2.3.3.10 同款检索之局部显著性擦除
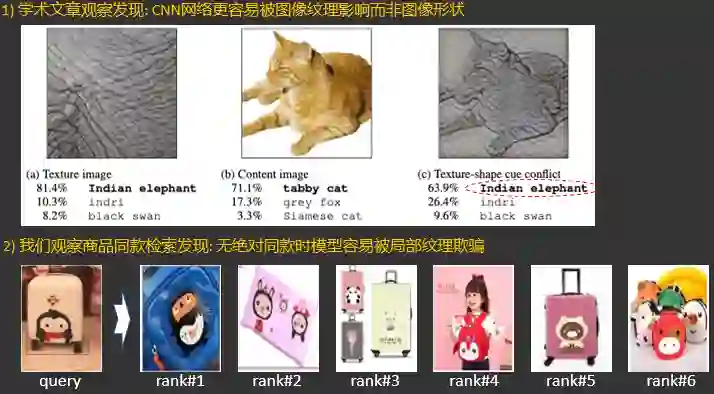
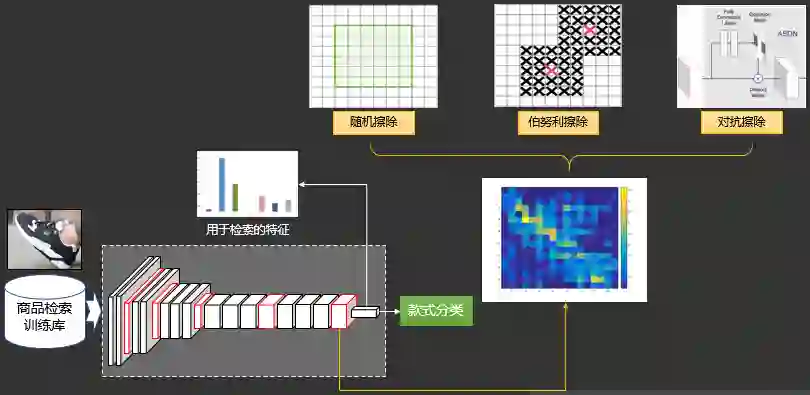
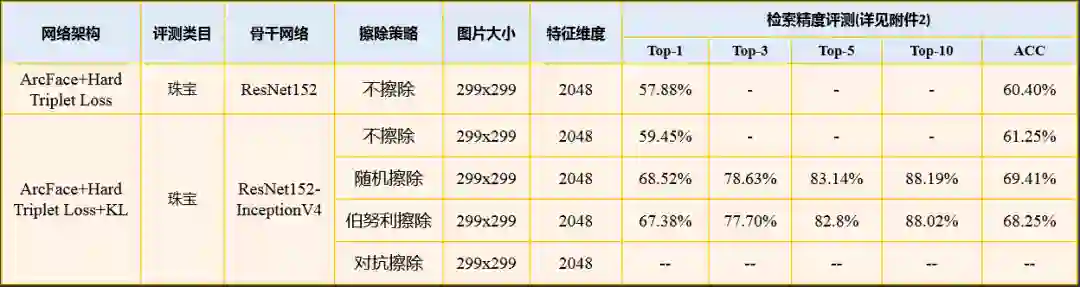
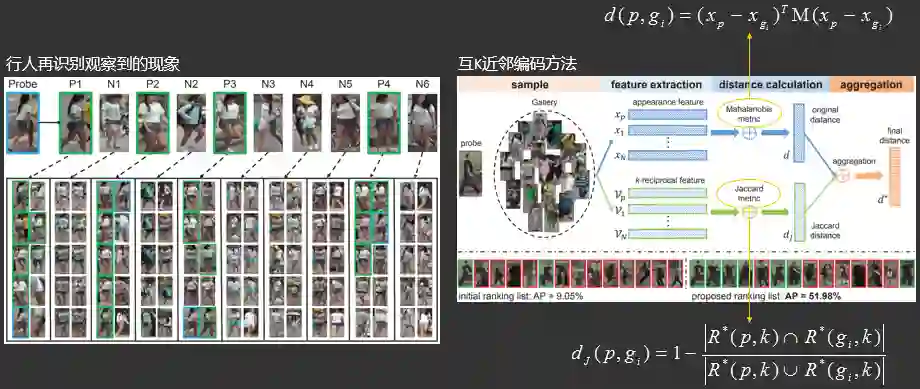
2.3.3.11 同款检索之互k近邻编码重排序
2.4 扫一扫识物平台建设
2.4.1 数据清理平台
2.4.2 模型训练平台
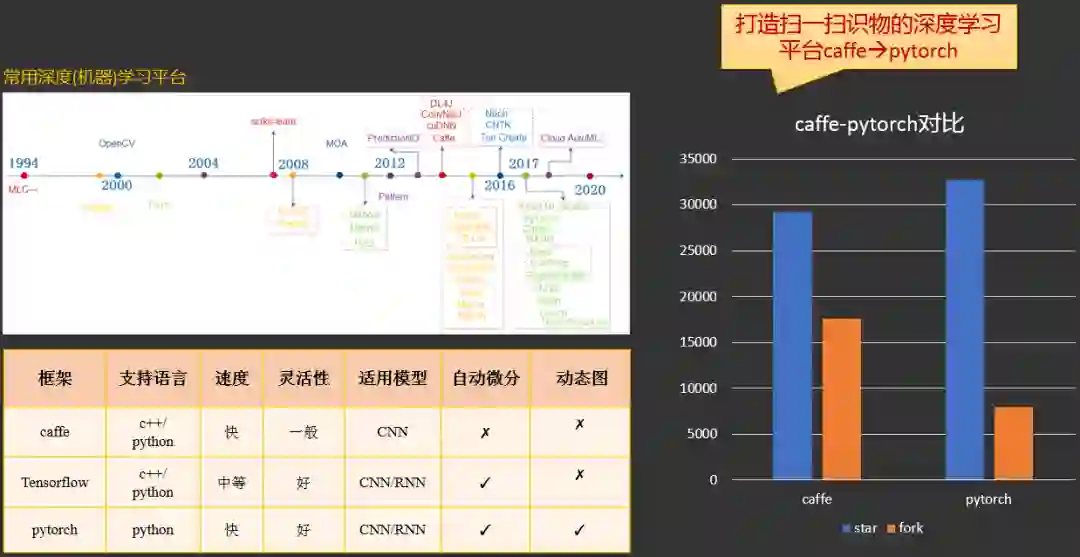
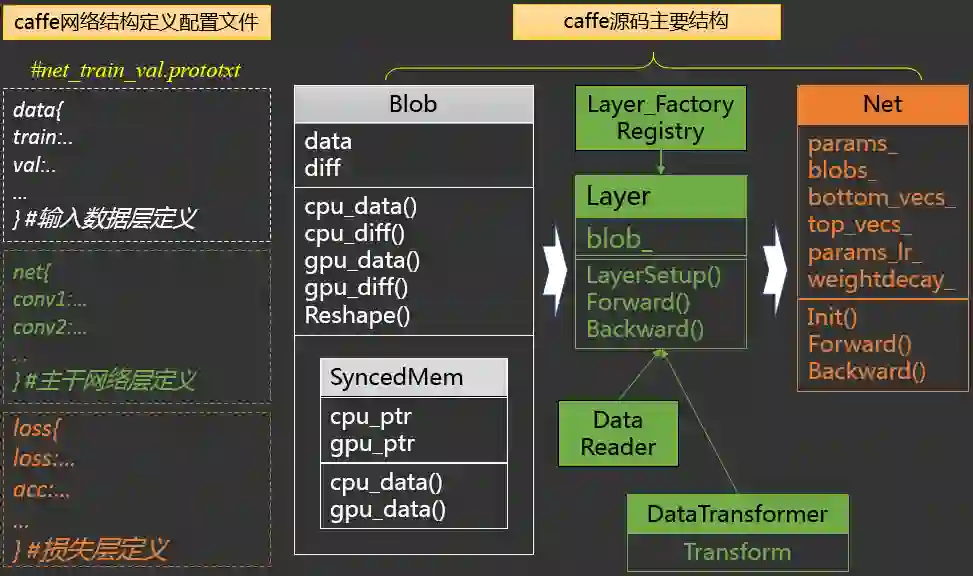
2.4.2.1 caffe
1)支持丰富的数据增广策略;
2)支持多类型数据加载;
3)支持蒸馏学习/互学习算法;
4)支持困难感知模型算法;
5)支持排序模型算法;
6)支持batchsize扩充。
1)训练快, 结果稳定;
2)基于prototxt快速试验各种多模型/多标签/多数据源任意组合。
1)新算法开发慢;
2)调试不灵活;
3)显存优化不好;
4)学术前沿方法更新少。
2.4.2.2 pytorch
1)支持丰富的数据增广策略;
2)支持多类型数据加载;
3)支持蒸馏学习/互学习算法;
4)支持排序模型算法;
5)支持更多主流网络EfficientNet;
6)支持数据去噪/合并同款/检索;
7)支持混合精度训练。
1)自动求导, 算法开发效率高;
2)动态图, Python编程, 简单易用;
3)Tensorboard可视化方便;
4)Github资源多, 紧跟前沿;
5)Pytorch1.3支持移动端部署。
1)在多任务自由组合不如caffe prototxt方便。
2.4.3 模型部署平台
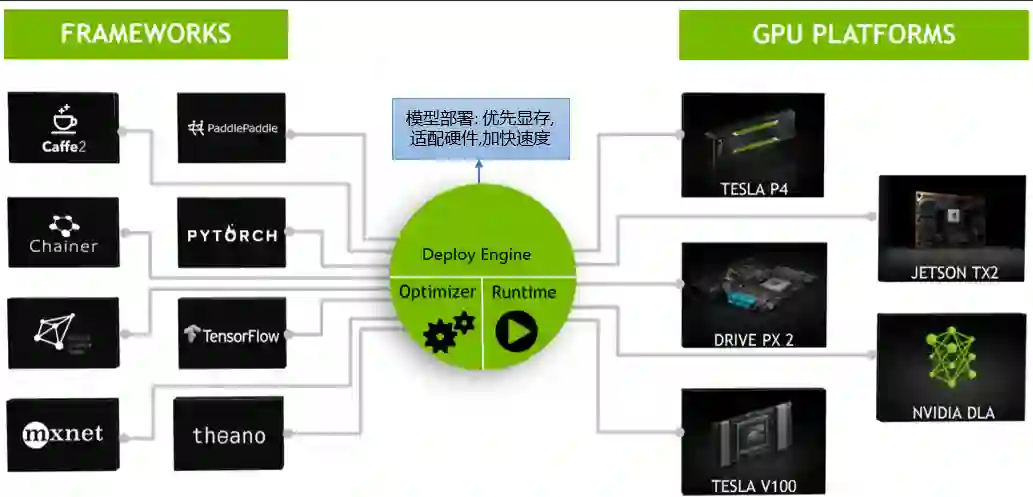
2.4.3.1 模型部署平台:tensorRT
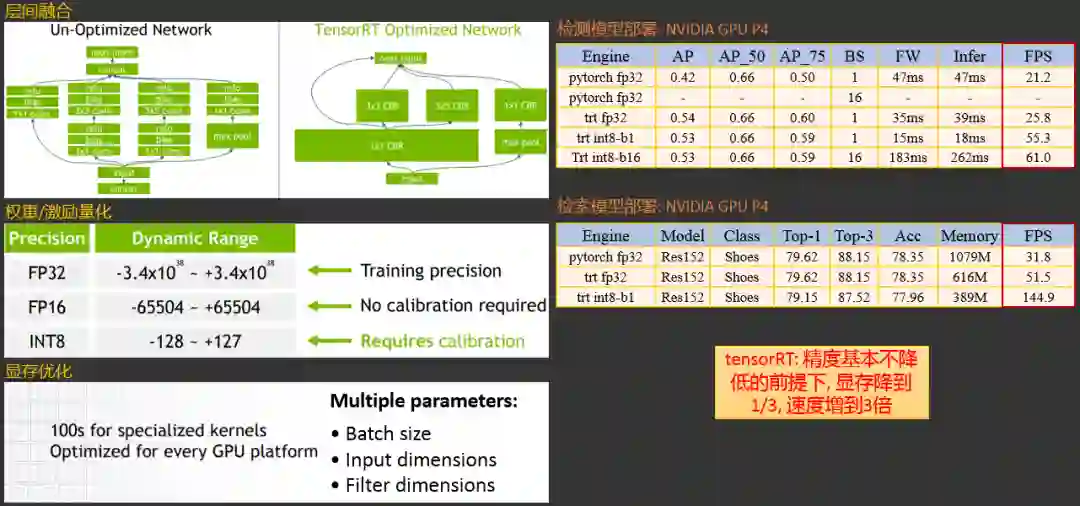
2.4.3.2 模型部署平台:ncnn

2.4.4 任务调度系统平台

扫一扫识物展望
参考文献
微信AI
不描摹技术的酷炫,不依赖拟人的形态,微信AI是什么?是悄无声息却无处不在,是用技术创造更高效率,是更懂你。
微信AI关注语音识别与合成、自然语言处理、计算机视觉、工业级推荐系统等领域,成果对内应用于微信翻译、微信视频号、微信看一看等业务,对外服务王者荣耀、QQ音乐等产品。