万字长文读懂微信“看一看”内容理解与推荐

在微信AI背后,技术究竟如何让一切发生?关注微信AI公众号,我们将为你一一道来。今天我们将放送微信AI技术专题系列“微信看一看背后的技术架构详解”的第三篇——《微信看一看内容理解》。
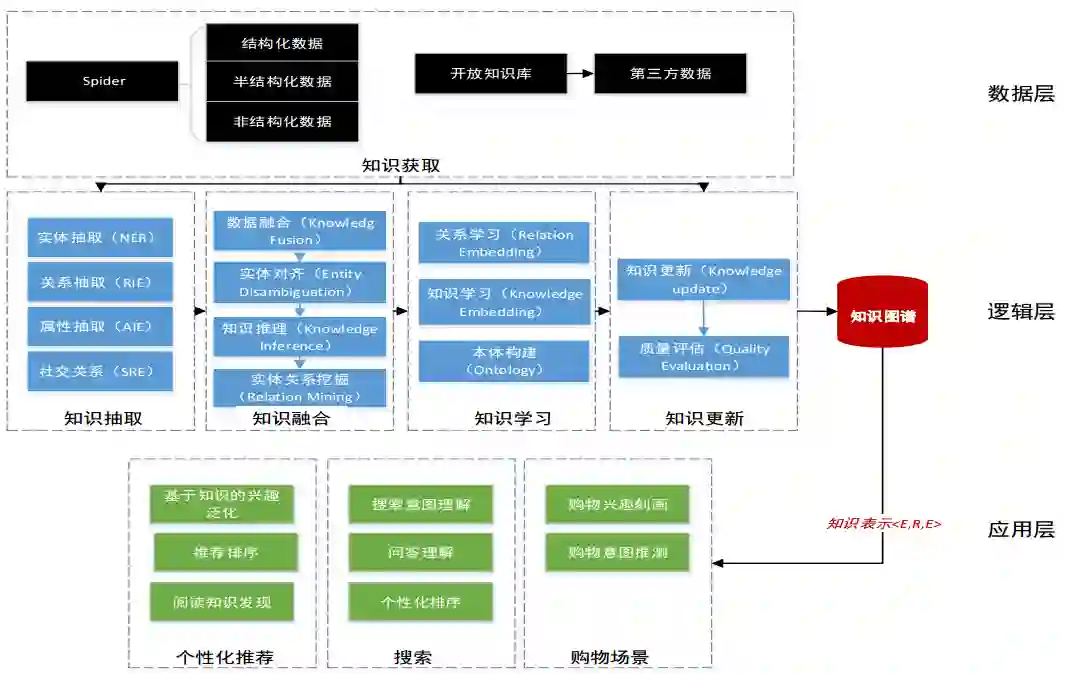
内容理解与推荐
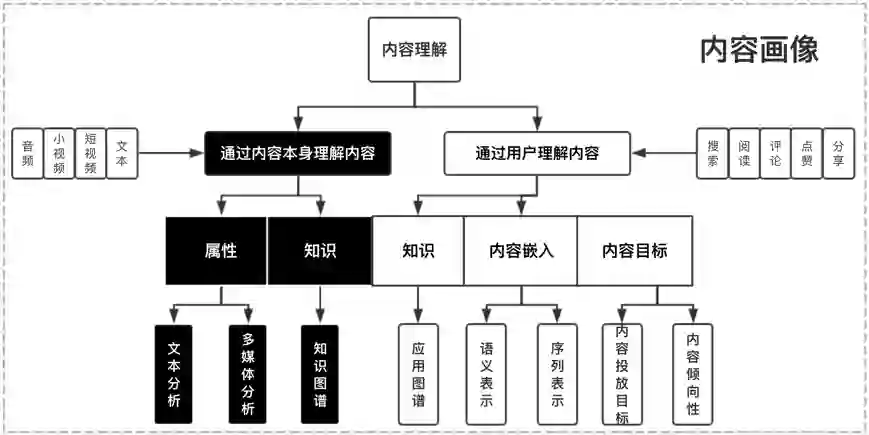
文本内容理解
2.1 文本分类

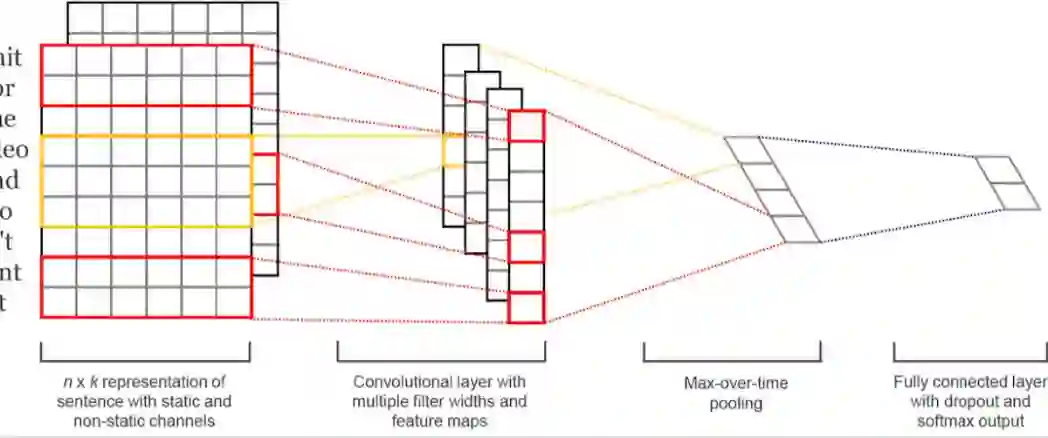
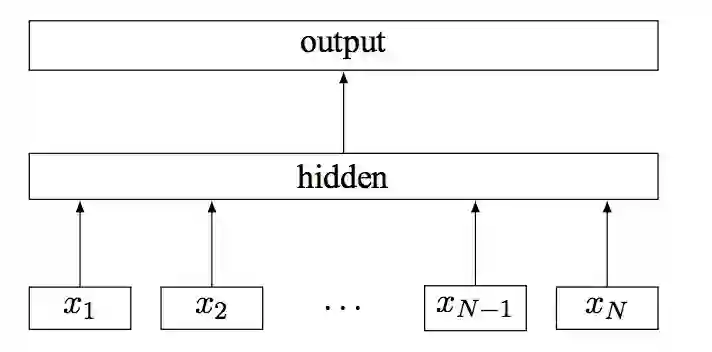
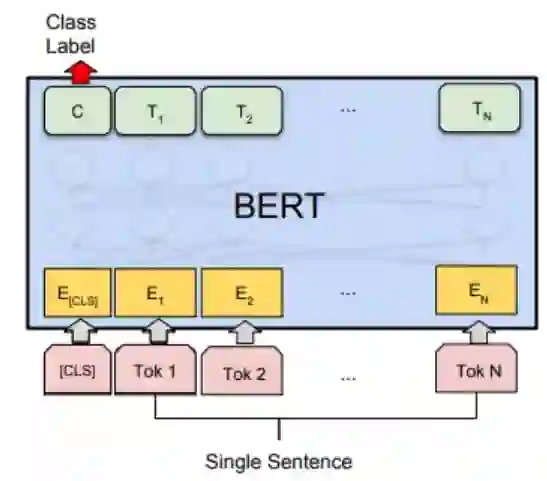
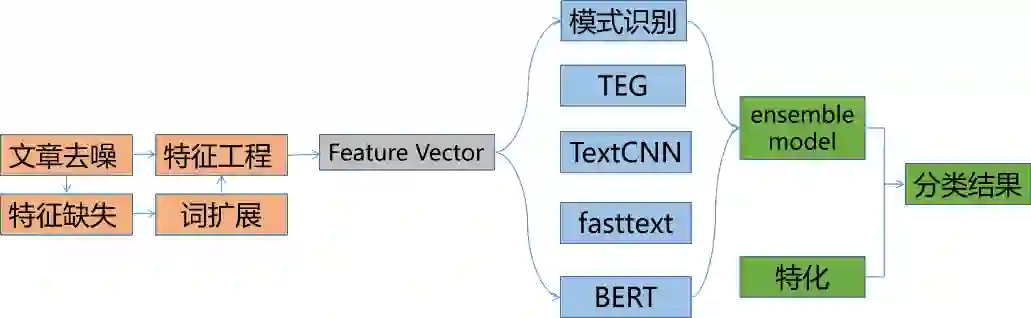
2.2 推荐文本标签
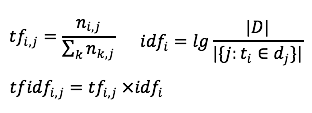
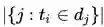 表示包含tokeni的文档个数。某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的tf-idf。因此,tf-idf倾向于过滤掉常见的词语,保留重要的词语。TFIDF优点是基于统计方式,易于实现,缺点是未考虑词与词、词和文档之间的关系。
表示包含tokeni的文档个数。某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的tf-idf。因此,tf-idf倾向于过滤掉常见的词语,保留重要的词语。TFIDF优点是基于统计方式,易于实现,缺点是未考虑词与词、词和文档之间的关系。
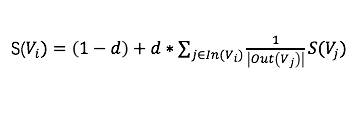
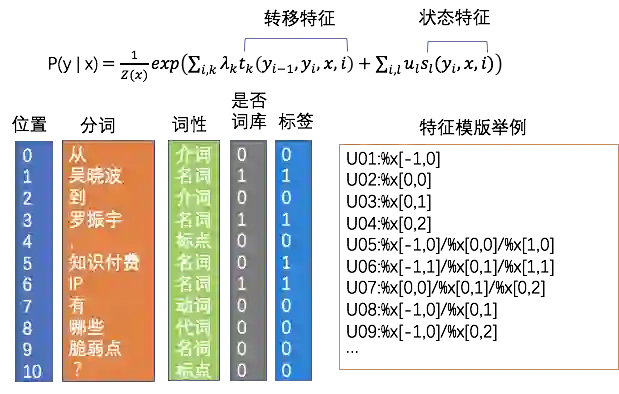
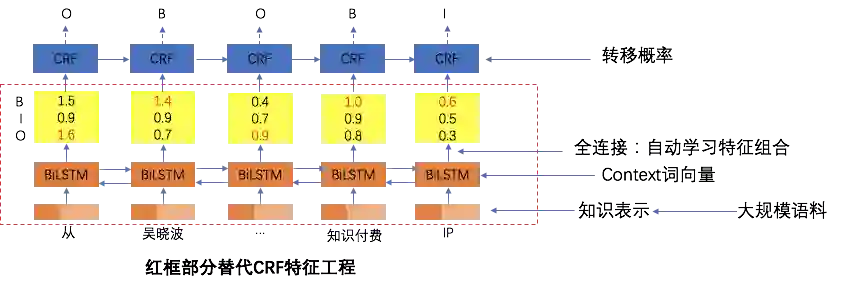
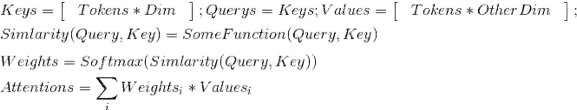
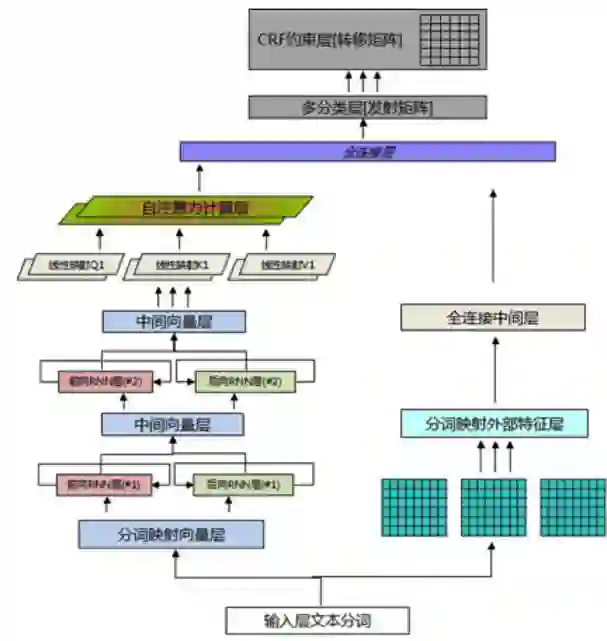
2.3 推荐entity识别

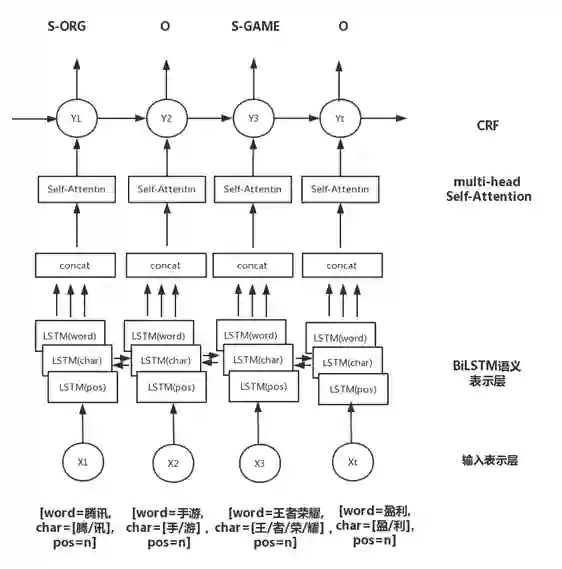
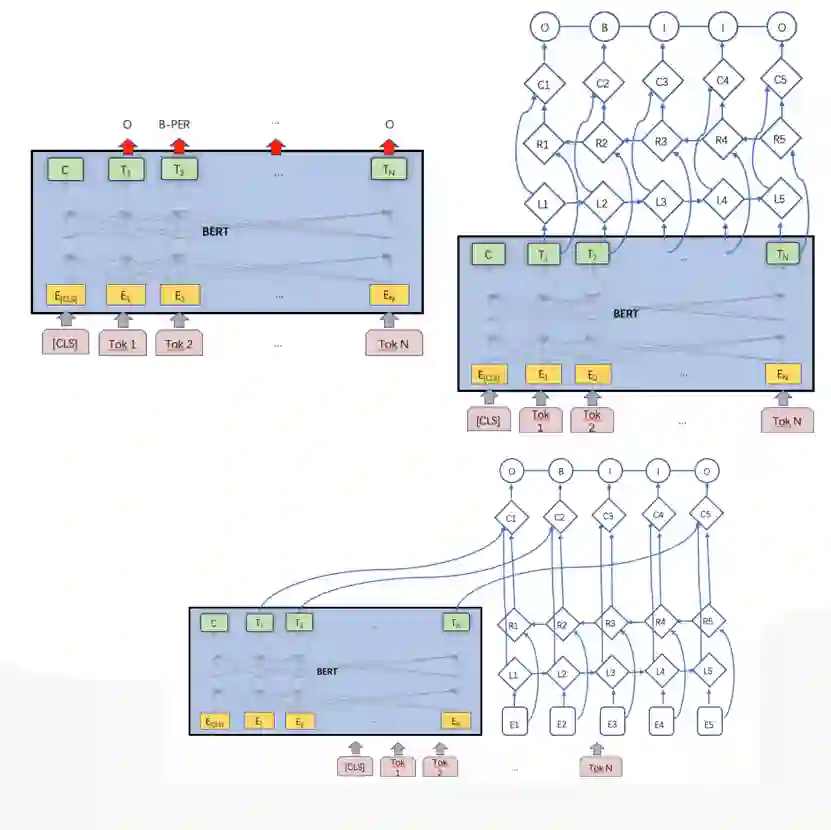
2.4 标签映射
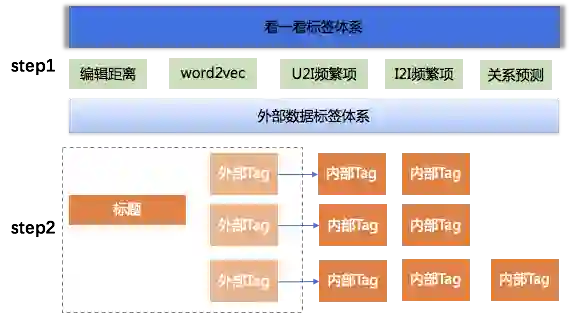
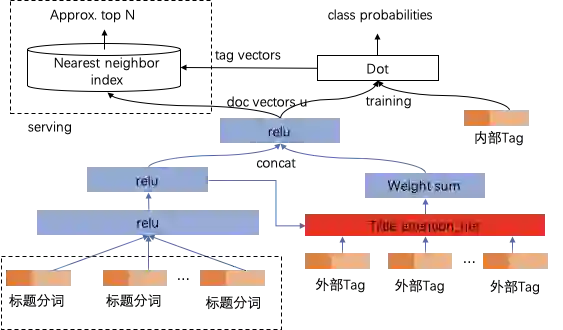
2.5 标签聚合
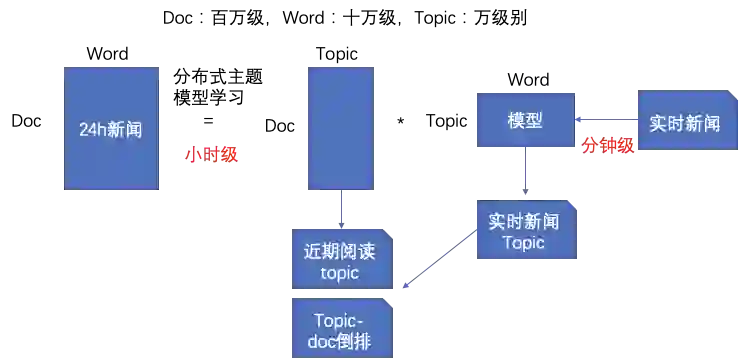
2.6 标签排序
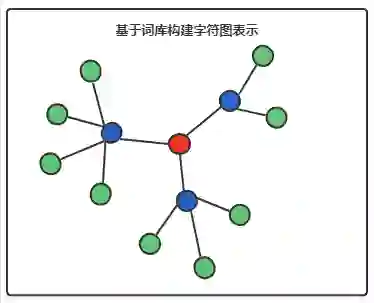
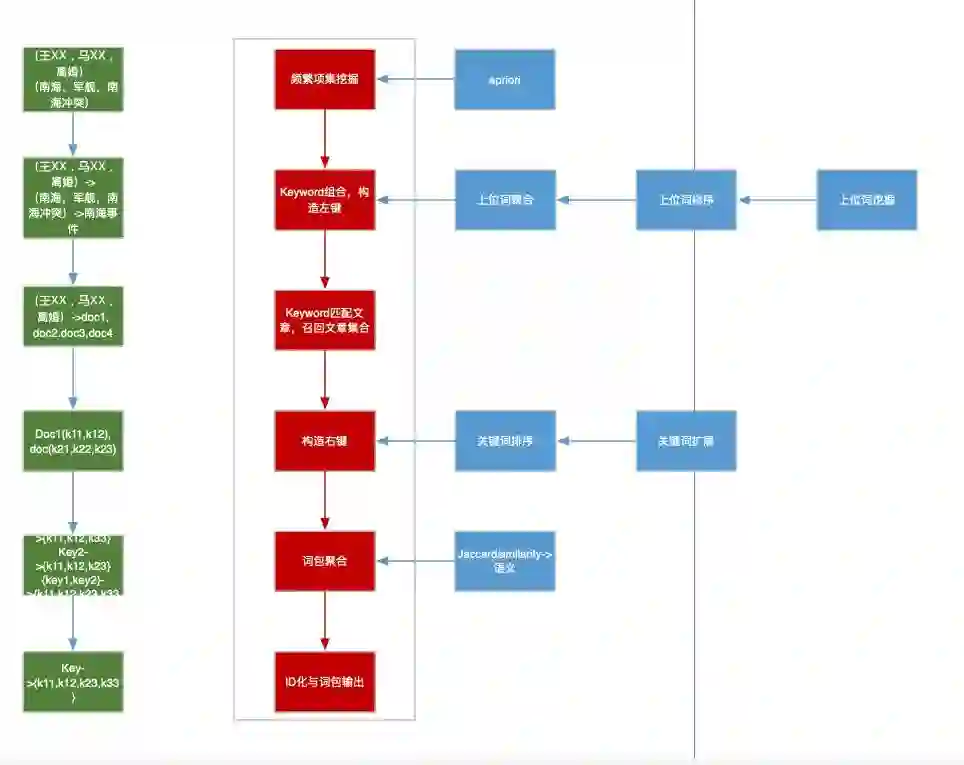
2.7 关系图谱
视频内容理解
3.1 视频分类

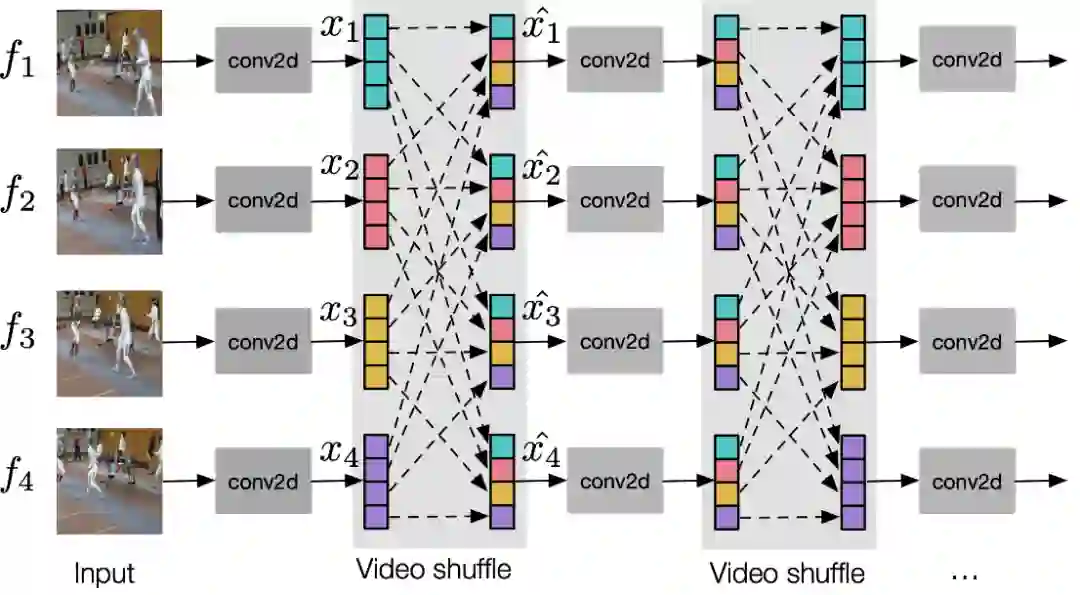
3.2 视频标签
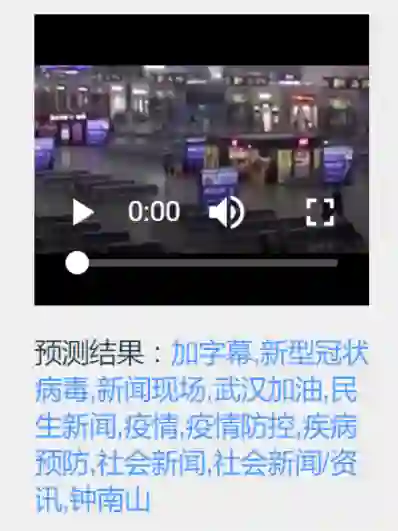
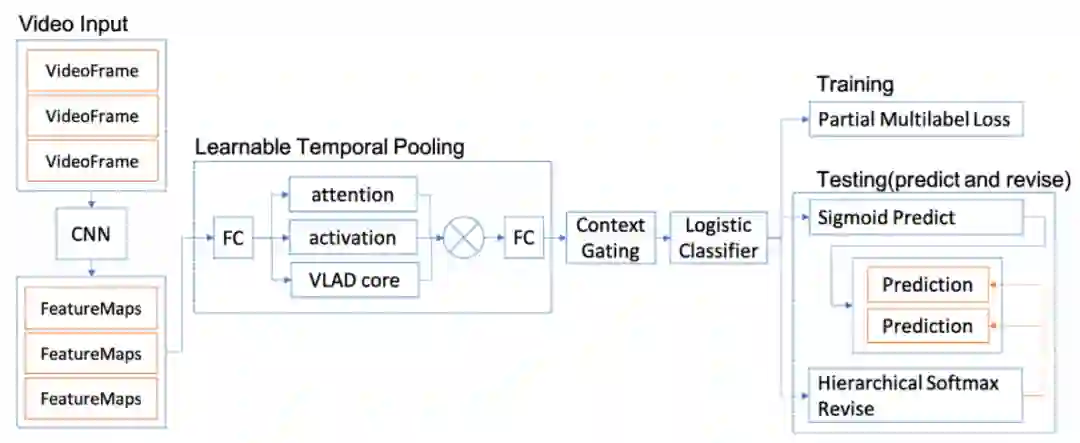
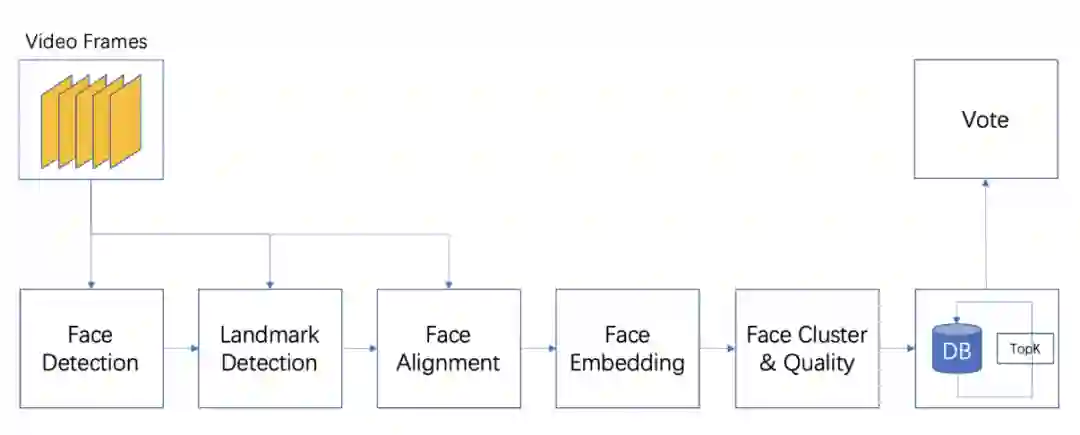
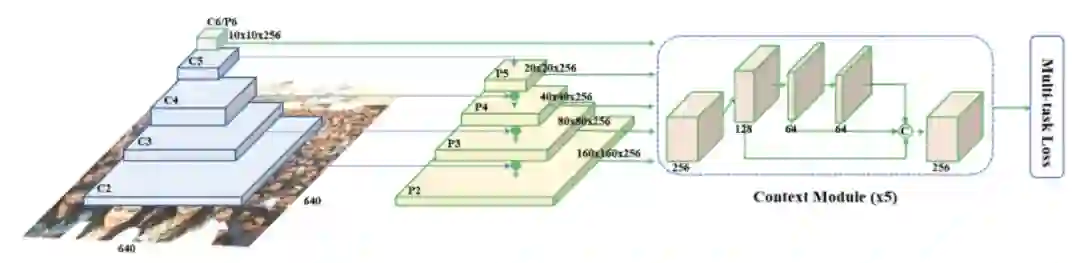
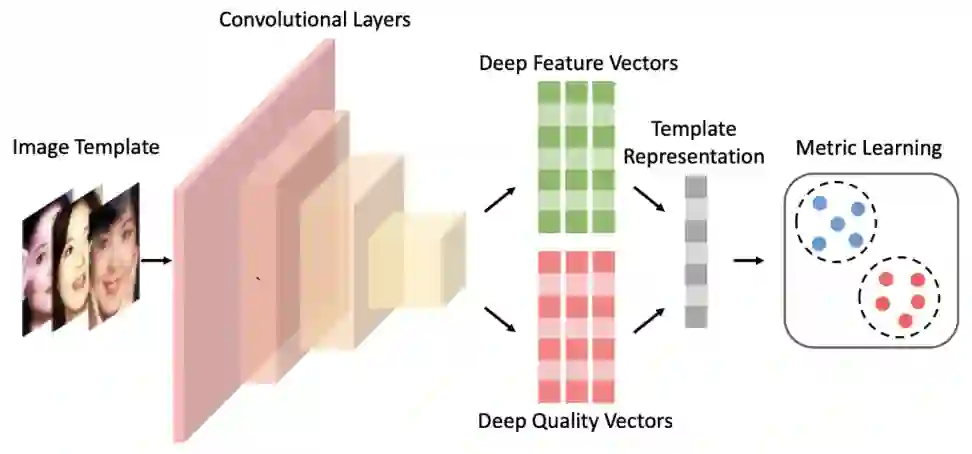
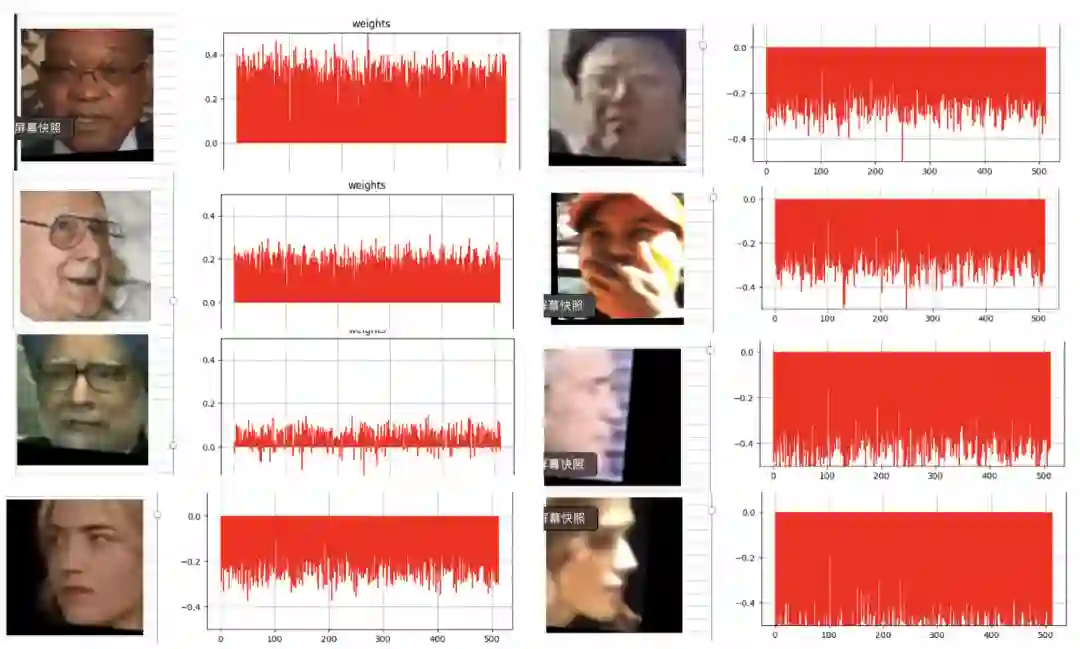
3.3 视频 Embedding
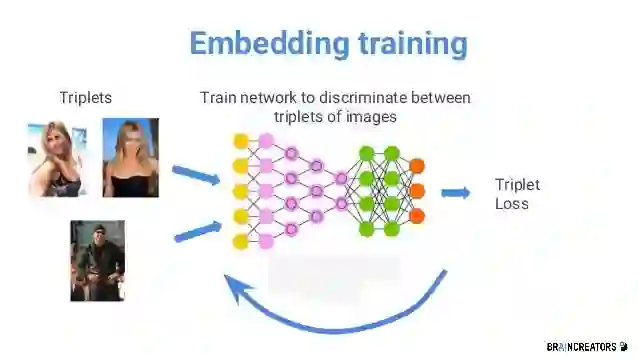

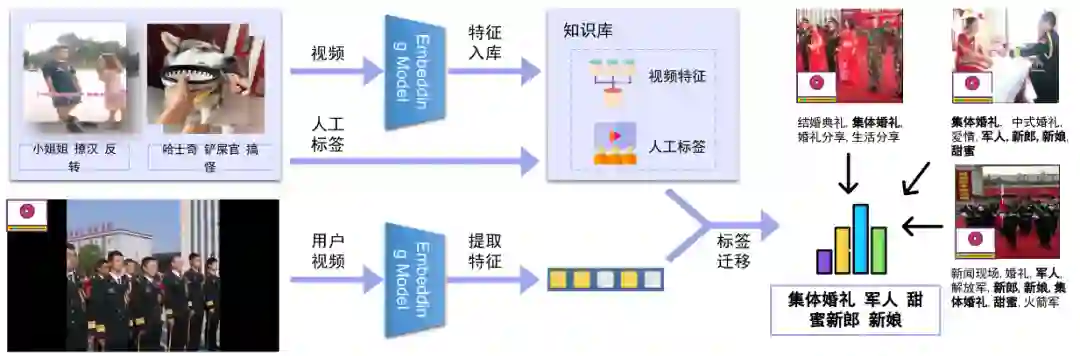

3.4 视频主题文本提取技术(T-OCR)
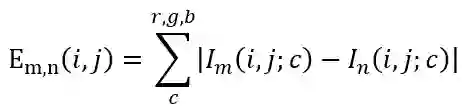
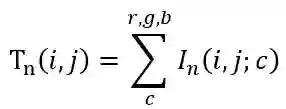
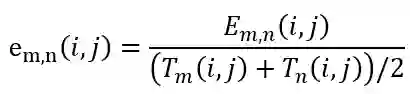

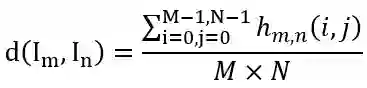
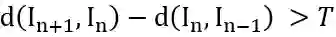 时,从第 n + 1 帧切分镜头。
时,从第 n + 1 帧切分镜头。
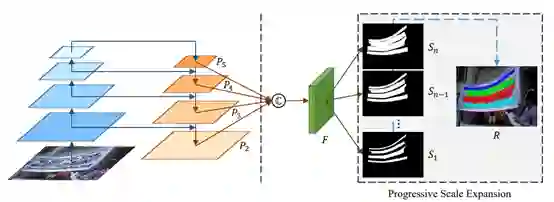
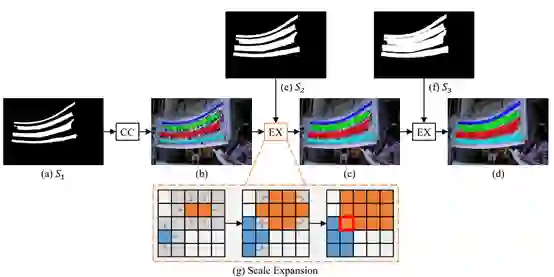

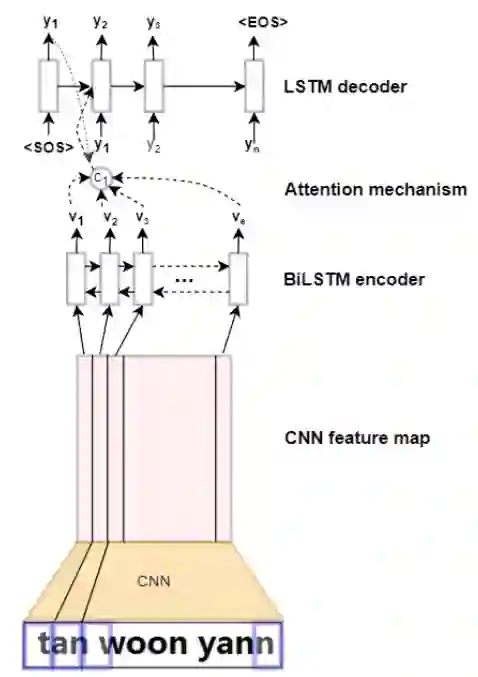
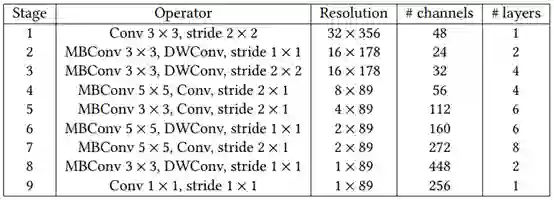
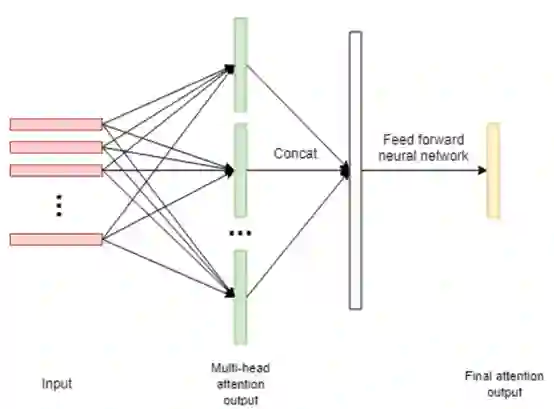
3.5 视频封面图和 GIF
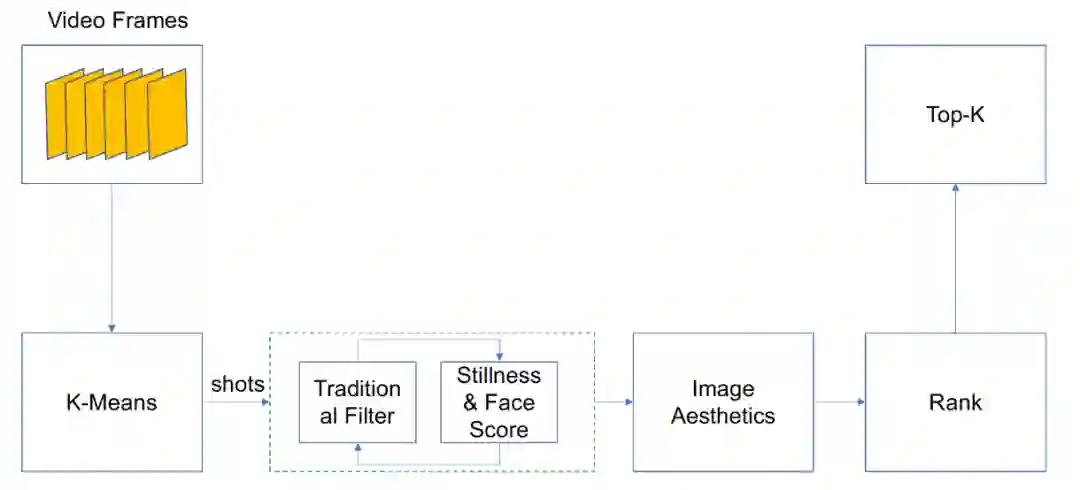

推荐内容倾向性与目标性识别

4.1 目标
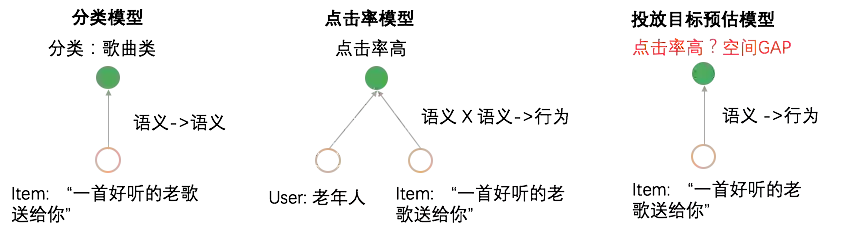
4.2 模型演进
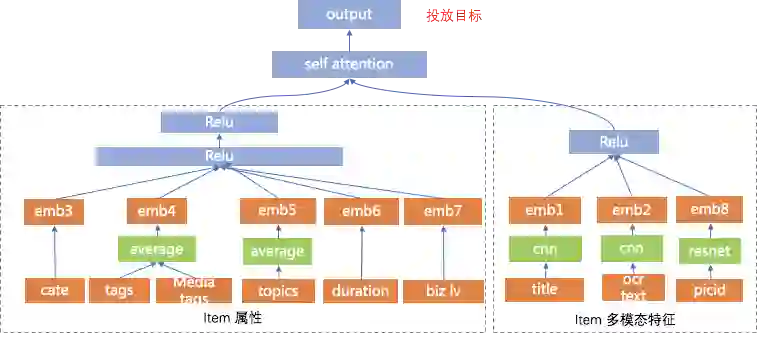
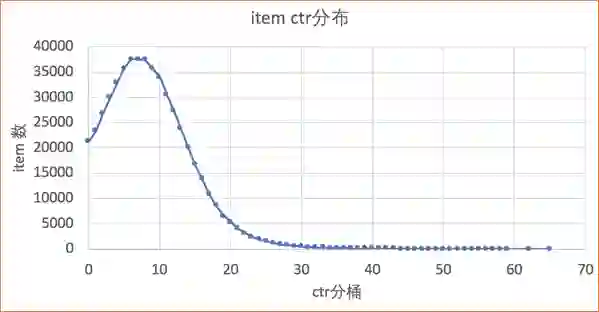
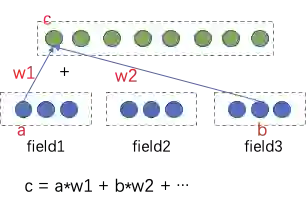
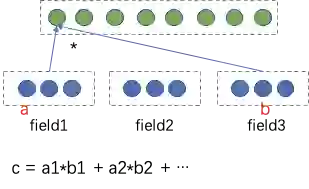
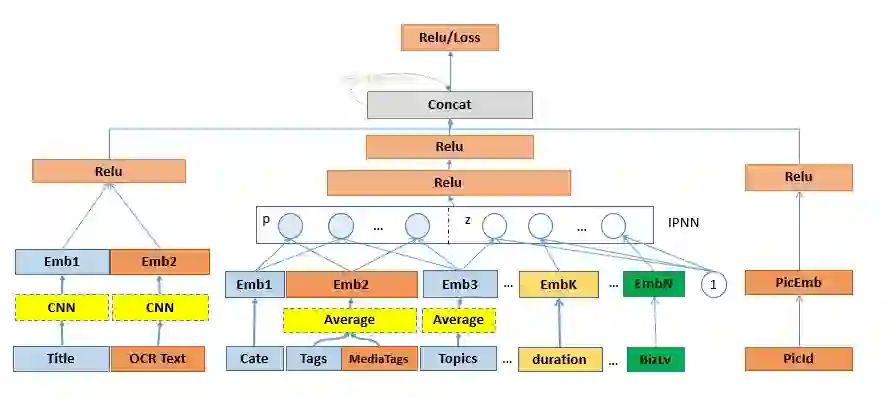
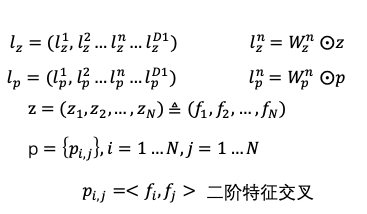
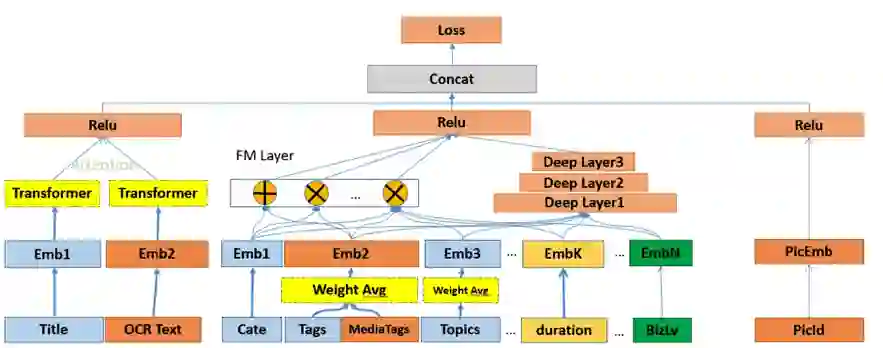

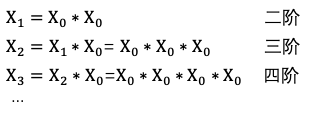

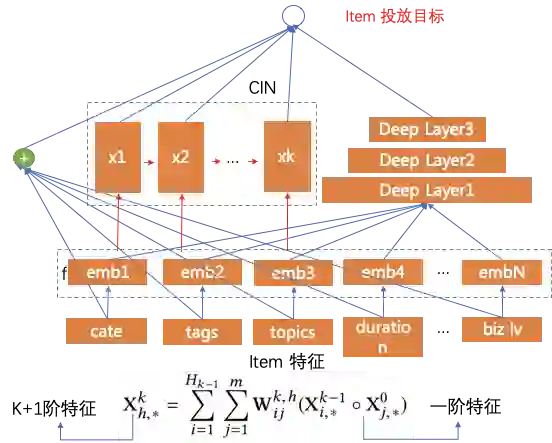
内容理解在推荐上的应用
5.1 全链路特征
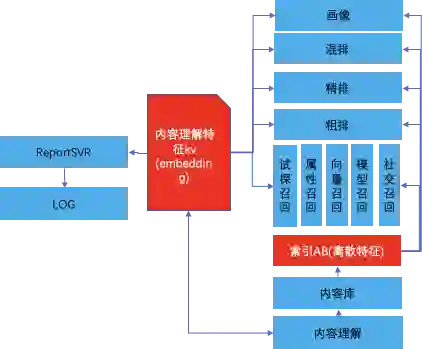
5.2 内容试探
5.3 优质内容库构建
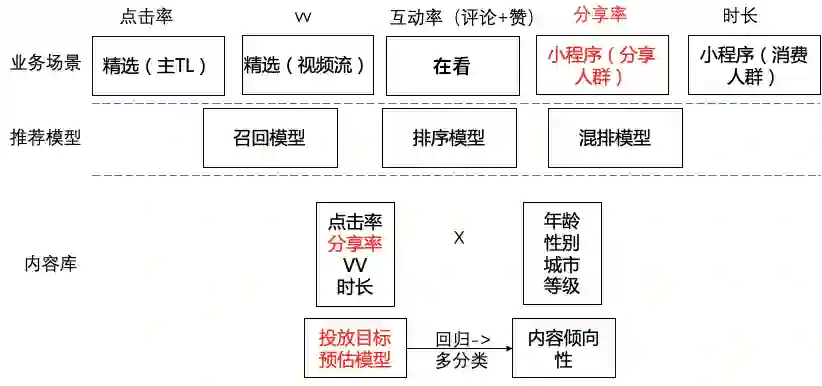
5.4 智能创意
总结与展望
微信AI
不描摹技术的酷炫,不依赖拟人的形态,微信AI是什么?是悄无声息却无处不在,是用技术创造更高效率,是更懂你。
微信AI关注语音识别与合成、自然语言处理、计算机视觉、工业级推荐系统等领域,成果对内应用于微信翻译、微信视频号、微信看一看等业务,对外服务王者荣耀、QQ音乐等产品。
登录查看更多
相关内容

专知会员服务
41+阅读 · 2019年12月15日




相关VIP内容
专知会员服务
41+阅读 · 2019年12月15日
相关资讯
相关论文