微信扫一扫识物是怎么实现“离线写,在线读”的?

在微信AI背后,技术究竟如何让一切发生?关注微信AI公众号,我们将为你一一道来。今天我们将放送微信AI技术专题系列“微信扫一扫的技术与艺术”的第三篇——《微信扫一扫识物——离线系统篇》。
导语
什么是识物
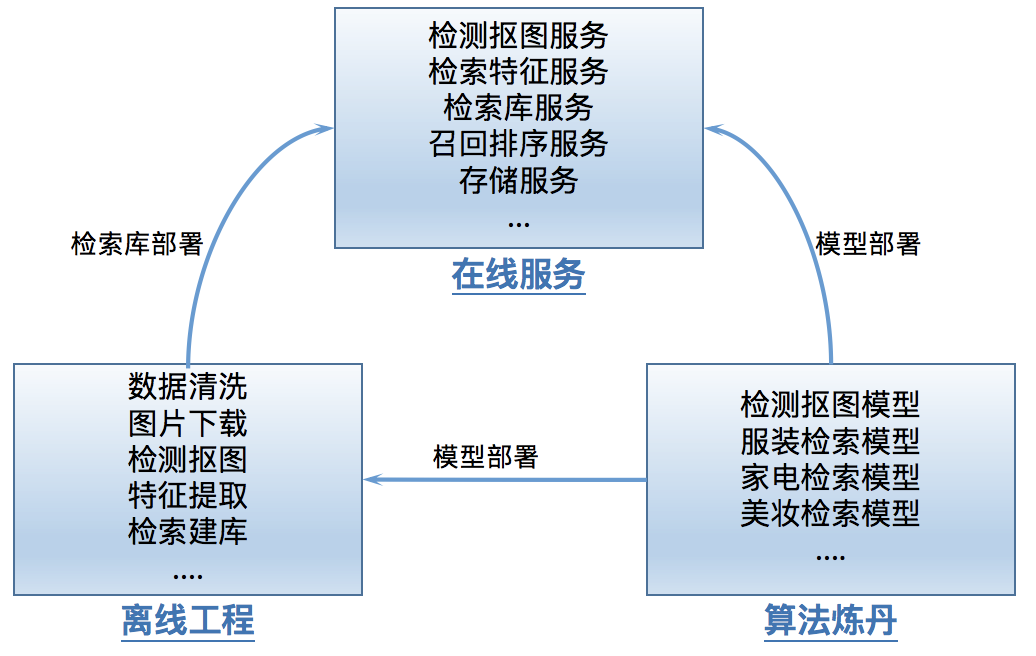
1. 算法模型
2. 离线工程
3.在线部署
挑战
1. 数据版本
2. 数据处理性能
3. 繁杂的流程
4. 数据质量
数据版本

2.1 检索库

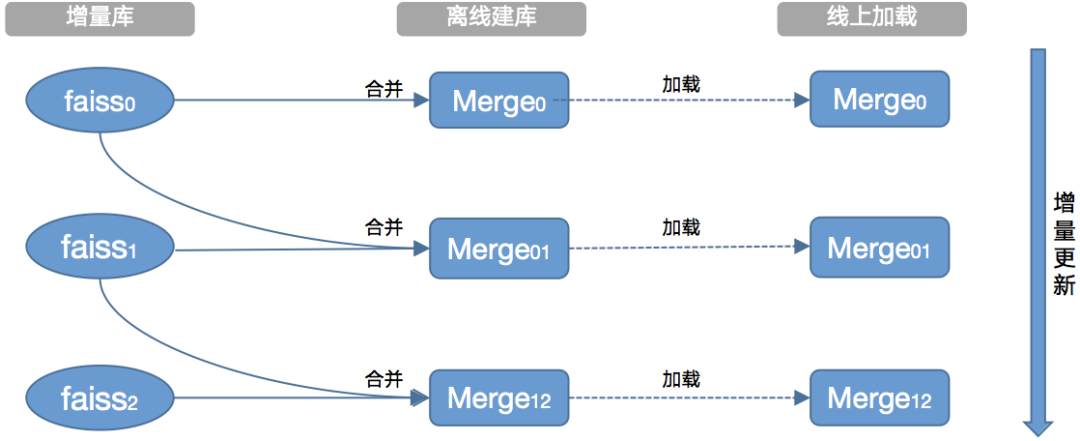
2.2 数据版本兼容
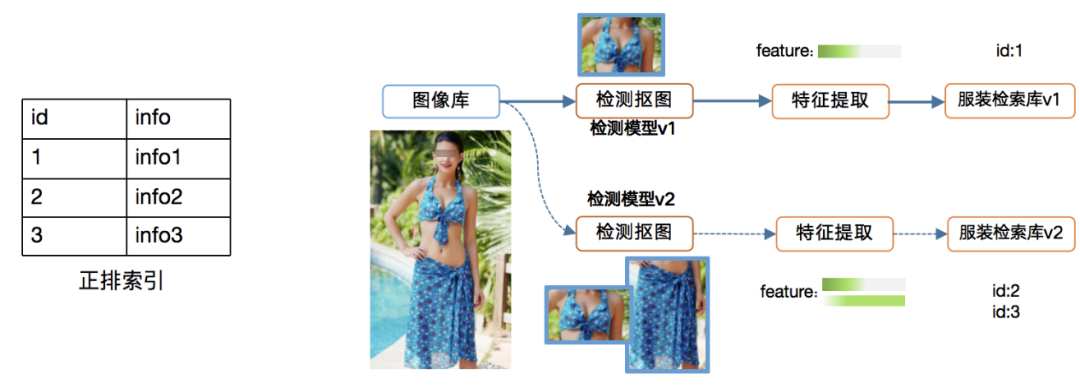
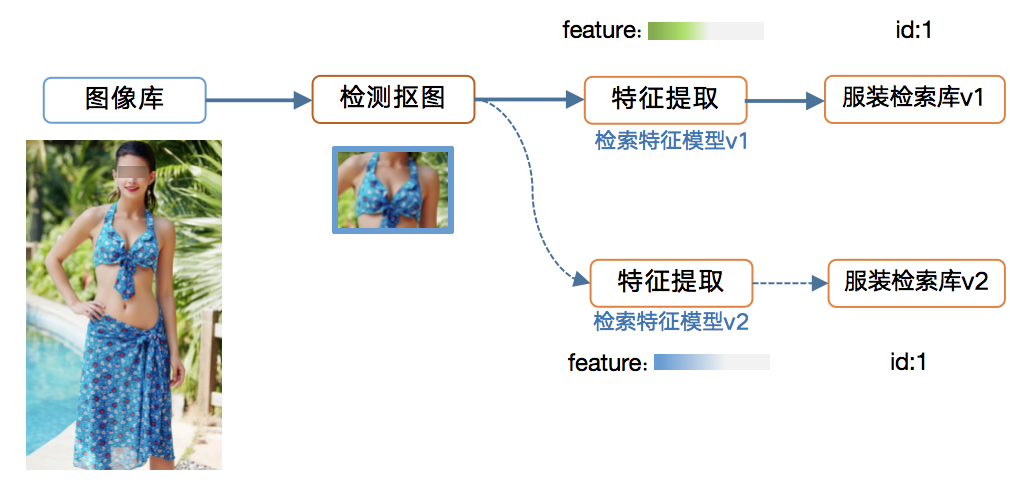
2.3 数据版本管理系统
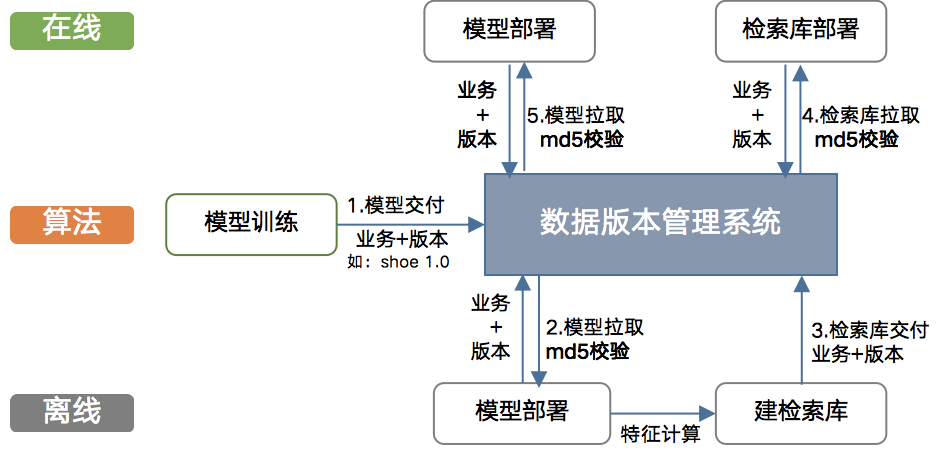
2.4 docker化
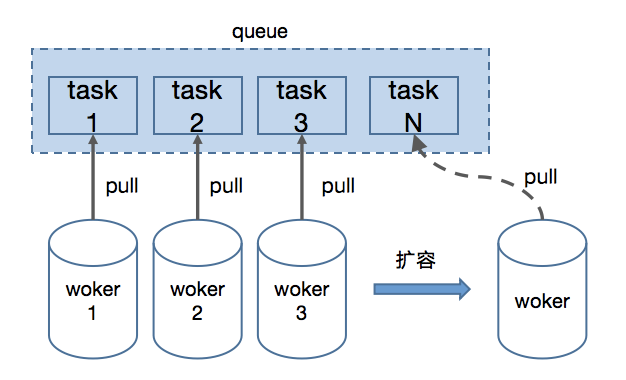
分布式计算
3.1 数据拆分
3.2 数据并行计算
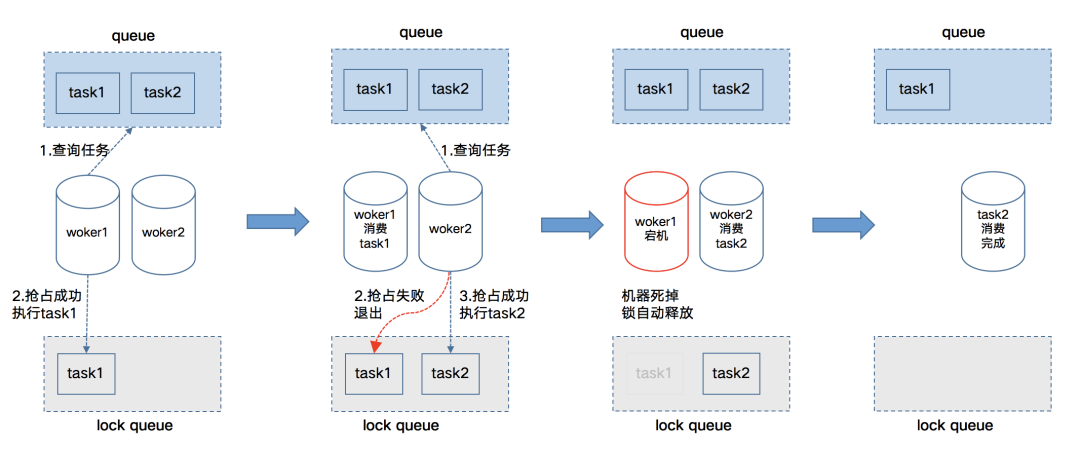
任务调度
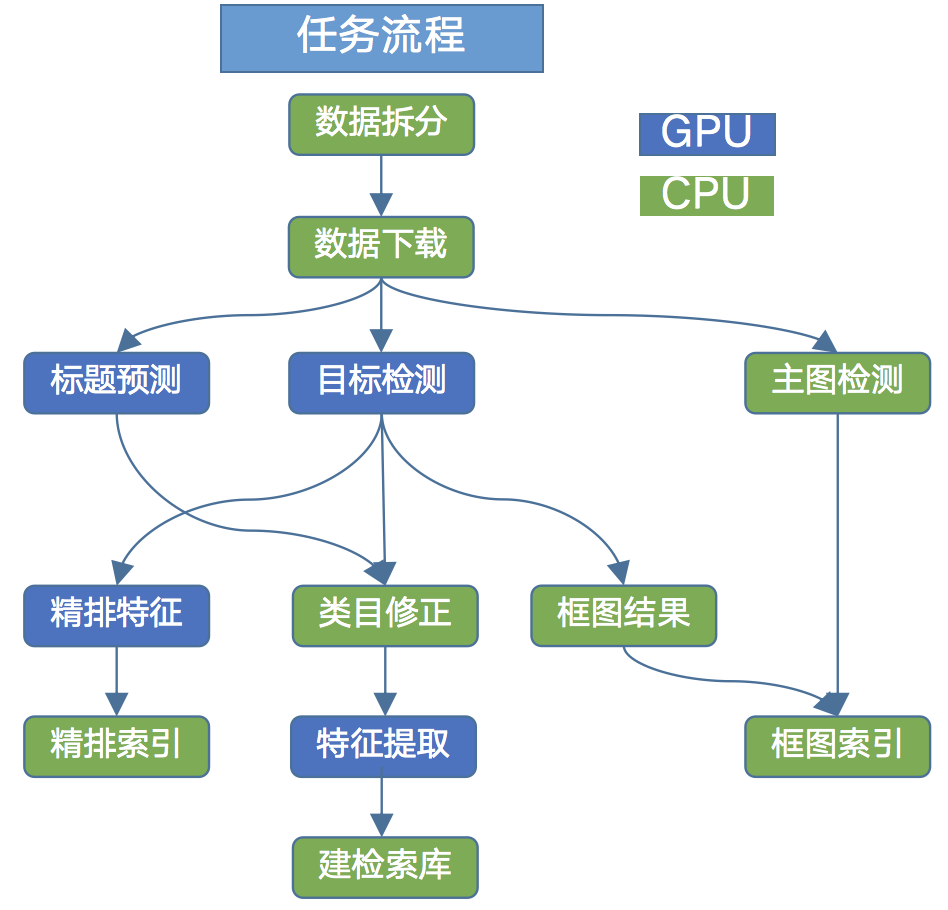
4.1 任务系统
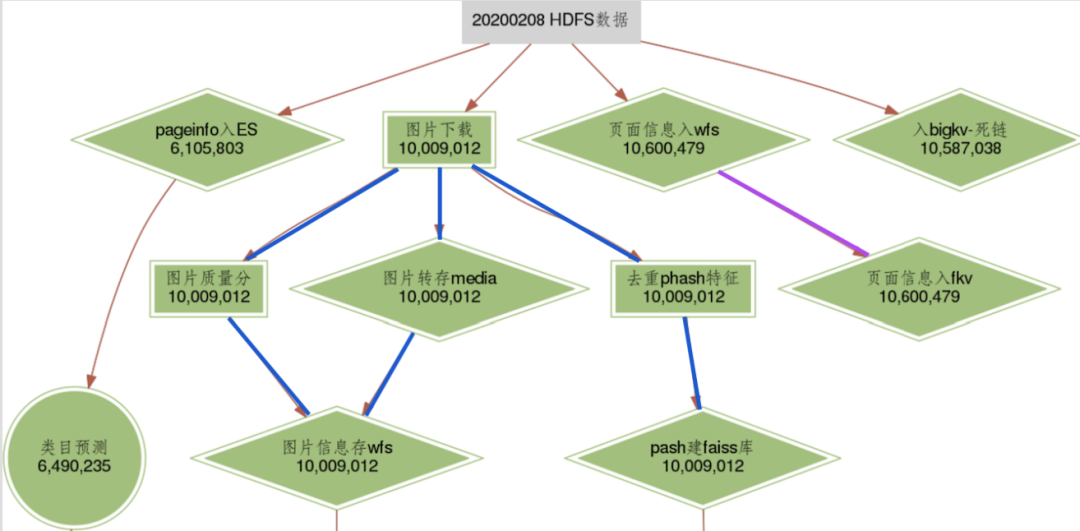
· 文件系统:文件系统这里使用了微信自研分布式文件存储系统的WFS,我们所有中间数据和结果数据都存放在这里
· 存储系统:主要有任务存储和实例存储,与一般实例存储不同的是,为了分布式计算,我们在数据维度和类目维度做了拆分,一个实例包含一个或多个子实例
· 调度系统:主要负责收集、管理任务状态,检查任务依赖
· 触发器:定时轮训调度系统,找到满足执行条件的任务实例
· 任务队列:存储待执行的任务实例,由worker获取依次消费
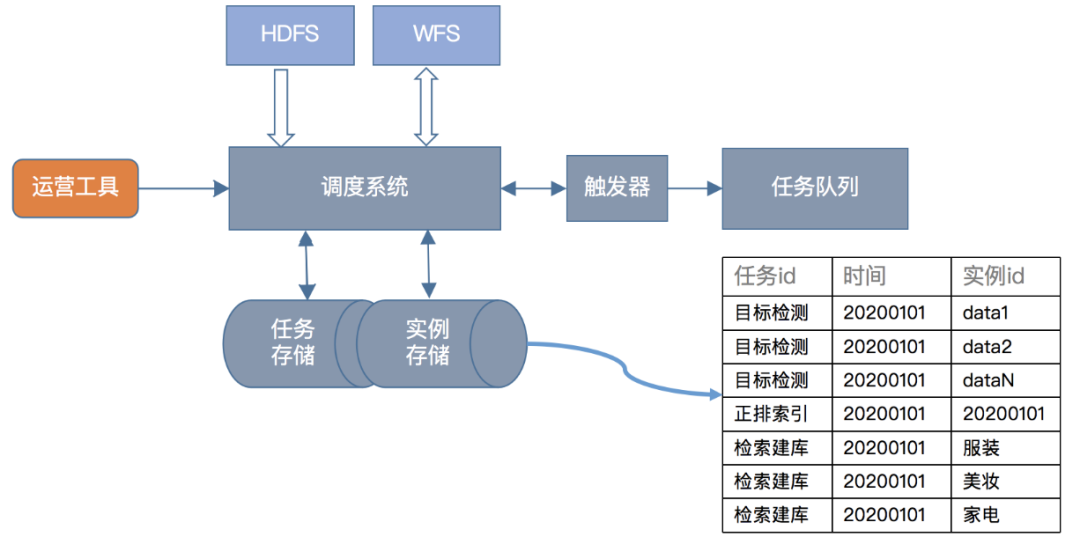
4.2 在线服务合并部署
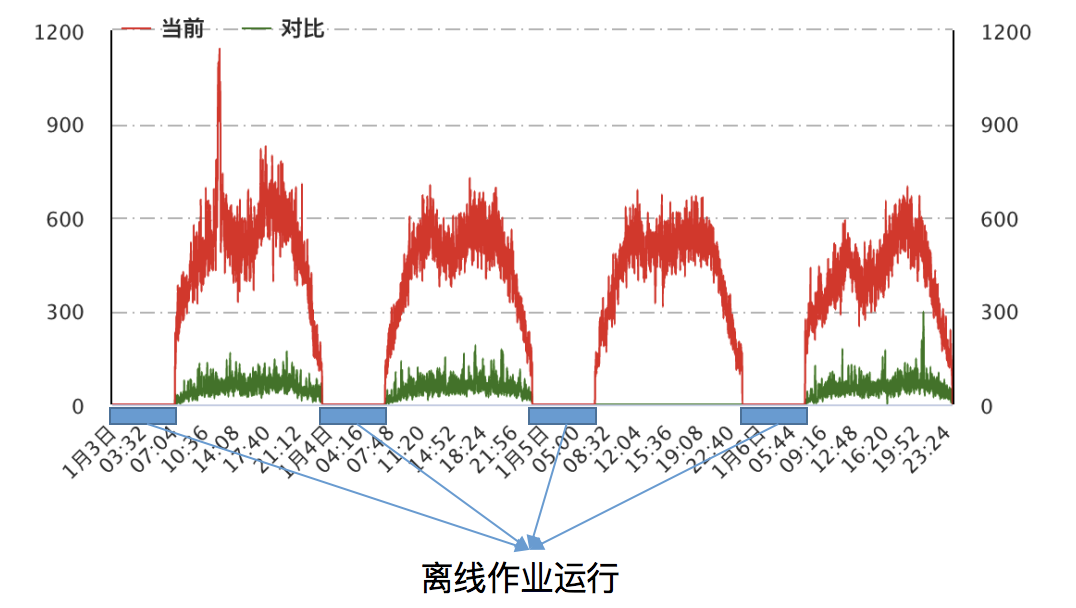
数据质量
5.1 数据可视化
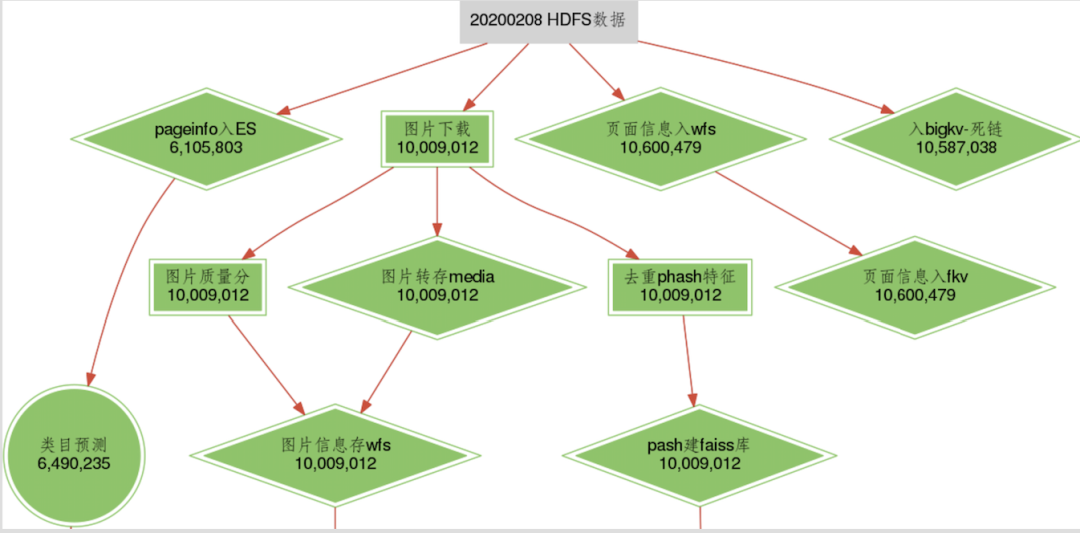
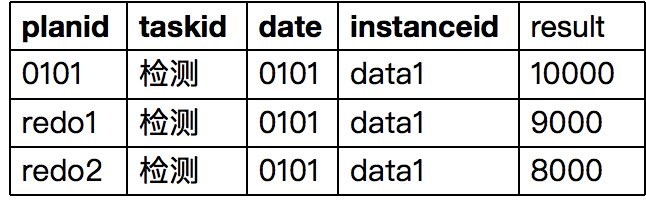
5.2 一致性检查
5.3 评测系统

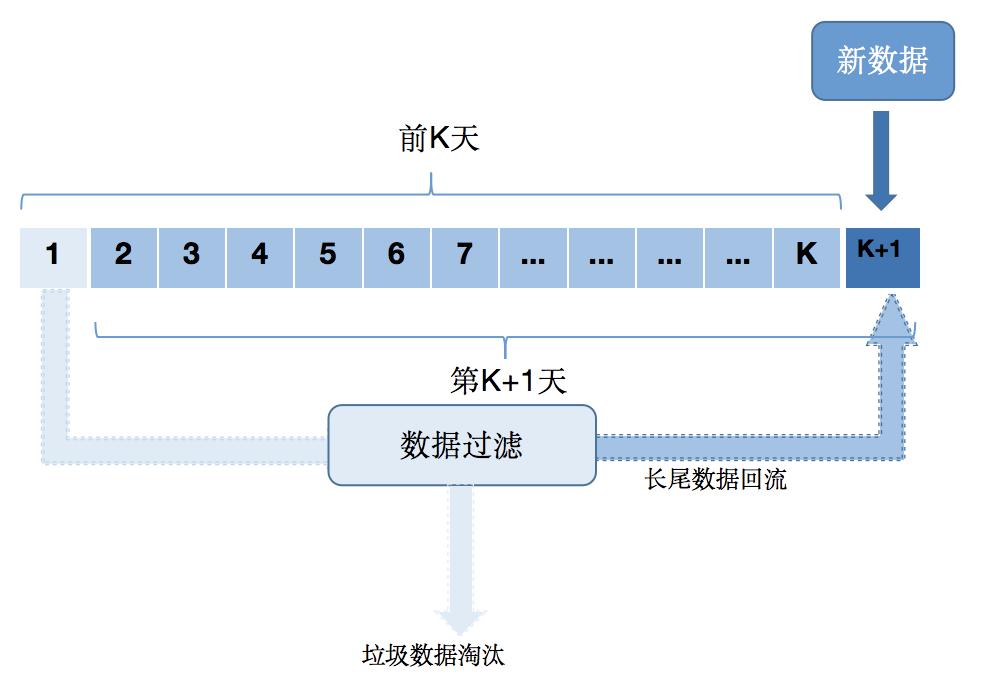
5.4 数据淘汰
总结
微信AI
不描摹技术的酷炫,不依赖拟人的形态,微信AI是什么?是悄无声息却无处不在,是用技术创造更高效率,是更懂你。
微信AI关注语音识别与合成、自然语言处理、计算机视觉、工业级推荐系统等领域,成果对内应用于微信翻译、微信视频号、微信看一看等业务,对外服务王者荣耀、QQ音乐等产品。

登录查看更多
相关内容
Arxiv
0+阅读 · 2022年4月17日
Arxiv
0+阅读 · 2022年4月16日




相关VIP内容
相关资讯