论文浅尝 | 神经符号推理综述(下)
3、神经驱动的符号推理
相比于之前的两种类型,神经驱动的符号推理的目的是挖掘规则,而神经网络在其中扮演的作用是解决纯符号推理的不确定性,并且能够有效的减少搜索空间。这种类型的方法的基本思路是找到query的多跳邻居节点,然后根据概率从这些邻居节点中选择正确的答案。这类方法大致可以分为三类,基于路径的、基于图的和基于矩阵的。
3.1、基于路径的神经符号推理
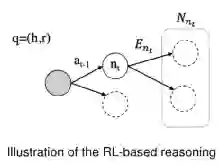
如图是基于路径方法的基本方式,在每一步上都会选择一个可能的路径。
这一类的方法的较早尝试是Path-Ranking Algorithm(PRA),需要注意的是这个方法是纯symbolic的,但是其余方法大多借鉴了这个方法,所以先简要介绍一下这个方法。 核心思想是利用连接两个实体的路径去预测他们之间是否有潜在的关系。但是每条路径的重要程度不同,所以需要对每条路径的分配合适的权重。
给定头实体h和尾实体t,PRA通过执行具有l步长的重启算法的随机游走来获得从h到t的长度为l的路径,然后计算实体对(h ,t)遵循路径p时候的得分。最后,PRA通过将不同路径的分数作为对应特征值的线性回归模型来估计不同路径的权重。
PRA依赖KG中存在的关系来寻找路径,下面两篇文章就是通过不同的方式来添加KG中的关系,分别是利用web的文本信息和语义库中的单词来补充KG中的关系。
Reading the web with learned syntactic-semantic inference rules.
Improving learning and inference in a large knowledge-base using latent syntactic cues.
以上的文章只能处理见过的关系,同时算法中的路径生成,是针对每一种关系的,所以针对不同的关系,需要训练不同的模型分别计算每种关系对应的多条路径的权重,那么很明显这种方式的局限性是比较大的。
于是Compositional vector space models for knowledge base inference提出用一个RNN模型来融合路径上的不同关系。使用了PRA来挖掘各种路径。找到这样的路径以后呢,使用RNN来将在这条路径中出现的关系的embedding融合起来,然后让融合以后的embedding更像head relation。比如这个例子里面的就是融合了一条路径的embedding。这里的embedding都是随机初始化的。这种方法的相较于PRA,泛化性更强,它能够处理没有见过的路径,也能处理训练时没有将该关系作为head relation的推理。
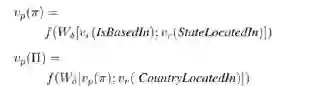
另外一种方法Chain-of-Reasoning,相比于上面的方法,他在处理路径embedding的时候,将不同的路径信息融合了起来,没有仅仅使用上面的做法,即只使用了一条路径,而考虑了多条路径,并且融合路径的方式也有很多种方式。
以上的方法都需要遍历路径,当图谱较大的时候,这种路径会非常非常多,而上述方法没有对路径进行评估,所以搜索空间很大。DeepPath使用了强化学习的方法来完成这件事。
基本思想是将推理过程建模为马尔可夫决策过程,和agent交互的环境状态是由当前节点的embedding和目标embedding来构成的。它的奖励函数是手工设计的,考虑了不同的方面,另外,一开始使用了监督学习预训练防止搜索空间过大。
DeepPath 首次将强化学习方法引入到知识图谱推理中,它对知识图谱进行简单的采样,训练策略网络;并通过手工设计的奖励函数对策略网络进行再训练。DeepPath 的主要任务是给定一个知识图谱中的实体对 (entity1, entity2),使模型推理从 entity1 到 entity2 的路径评估模型的主要任务是链接预测和事实预测。DeepPath 中存在一定问题。例如,它的奖励函数是手工设定的,这种手工设定的策略可能并不是最优的,并且针对不同的数据集可能需要不同的设置;它的采样方法可能导致策略网络出现过拟合现象;强化学习环境中的状态使用 TransE 简单地进行表示,表征能力可能不足。
AnyBURL在使用强化学习完成路径抽取以后,会将其抽象成具体的路径,并且决定生成的不同规则中哪些是置信度高的规则,以下是一个根据路径抽象出规则的例子:
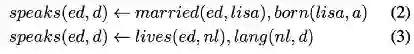
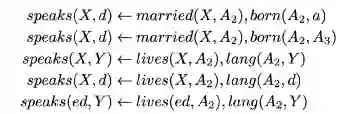
其余的强化学习方法例如MINERVA解决了其他的一些问题,Deeppath完成的是给定实体对从而推导实体之间的关系路径,而不能在给定头实体和关系的情况下推导出尾实体。MINERVA定义state的时候,没有使用answer的embedding,所以这里可以给定头实体和关系来查找答案,使用hard reward来作为激励。
Mutil-hop使用了相似度来代替hard reward。同时受到drop-out的启发,在选择过程中mask了一部分的选择来防止过拟合。
CPL在选择的时候除了考虑了KG中的信息,还考虑了文本库中的信息。
3.2、基于路径的神经符号推理
基于图的推理,GraIL利用图神经网络从抽取的子图中来推理。基本步骤如图,首先抽取head和tail周围的k跳邻居节点,然后对于每个邻居节点,用一个tuple来表示其特征,其中有两个元素,代表该节点到head和tail的距离。
这里借鉴了R -GCN的方法来建模对多关系图的消息传递,区别在于增加了一个注意力机制,该注意力机制不仅仅和两个相邻节点以及它们之间的关系有关,也和需要被预测的目标关系有关。最终利用两个目标节点的表示,整个图的表示,以及被预测被预测关系的表示,对该目标节点之间具有该目标关系进行打分,得分最高的目标关系为被预测关系。个人感觉这种方法的symbolic的成分比较少。
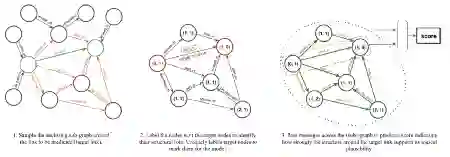
DPMPN提出基于动态子图的方法,将显示推理技术与图神经网络有效融合,开发出图版的注意力机制,用于引导动态剪枝的子图构建过程。其设计出两层图神经网络架构,下层是基于全图随机抽样的图神经网络,上层是基于批输入多子图的图神经网络,连接两个图神经网络层并指导子图构建的是一种图版的注意机制,更准确的说,是一种注意力转移机制(Attention Transition Mechanism)。深度学习网络通常是一个超大的网络,动用大量的计算节点及上百万的参数,但是针对每一个具体的例子,人类通常只用很少若干点来作解释,大量非必要的信息被过滤掉。我们看到的解释部分,实际反映的是我们的意识状态,它是从下层的潜意识全状态中通过某种筛选机制自动涌现出的可自我识别的特征,即解释,并通过主观的有序组合形成我们的推理过程,让我们能够从纷繁复杂的信息中迅速捕捉到最相关特征,大大降低后续作显式推理所需的计算复杂度。
3.3、基于矩阵的神经符号推理
基于矩阵的推理源于tensorlog框架,但是真正将其有效利用的当属neural-LP。
在tensorlog框架中,实体使用onehot向量表示,每一种关系都使用邻接矩阵表示,那么一个head relation所对应的若干条关系可以表示成如下形式:
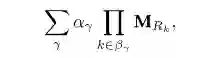
本质上是通过矩阵来找到需要预测的triplet的不同层的邻居节点,并且对于每条规则有的不同置信度来选择概率最大的实体作为结果。但是这个框架本身的问题在于搜索空间过大,并且及其耗时。
于是Neural-LP将上面的式子改写为:
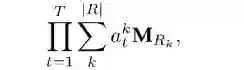
本质上是在规定了规则长度以后,在每一步上都给所有的关系分配一个的权重,这样最后的结果向量实际上是得到了head entity的T跳邻居节点,只不过每一个的权重不同,最后选择权重最大的作为预测结果。这个方法将tensorLog中离散的过程转为了可微的过程,并且通过端到端的框架直接学习到了规则。
DRUM的核心思想与Neural-LP一致,只是加了一些trick来使得寻来呢更加简单。
NLIL则注重于挖掘形式更加丰富的规则:
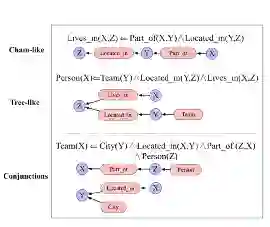
Neural-Num-LP则通过设计以下算子使得neural-LP框架能够学习到包含数值对比的规则。
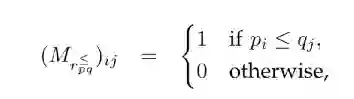
总结
以下是这篇文章中提到的神经符号推理的所有模型和方法。总体而言,第一种神经符号推理,即符号驱动的神经推理,旨在学习实体和关系的嵌入。利用逻辑规则增加高置信度三元组的个数,提高embedding的效果。因此推理过程仍然是基于embedding的,这缺乏可解释性。第二类,即符号驱动的概率推理,通过以KGs为基础的规则来限定逻辑规则。随着KGs中实体和关系的增加,基础原子/规则将急剧增加,从而导致推理和学习的计算成本增加。此外,这些方法不会产生新的规则。以上两种方法都以答案预测为唯一目标。不同的是,在符号驱动的概率推理中,规则被用来作为预测答案的特征,而在符号驱动的神经推理中,规则被用来生成更多的事实。第三种,即神经驱动的符号推理,以答案预测和规则学习为目标。为了达到这一目的,它根据从头部实体开始的路径、图形或矩阵来推断答案,从而增强了预测答案的可读性。然而,随着跳数的增加,路径、子图或矩阵乘法变得更加复杂,使得预测性能对知识图的稀疏性更加敏感。

OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。


