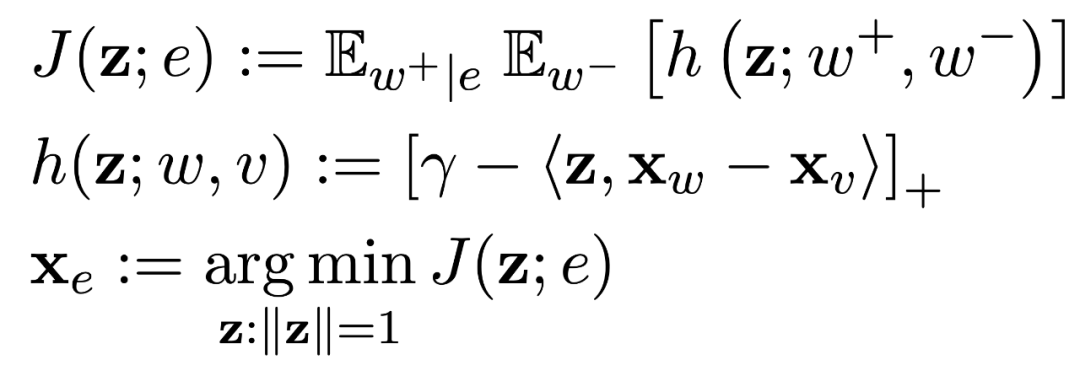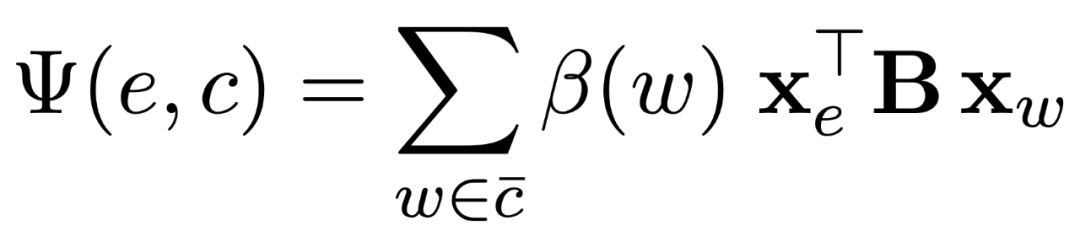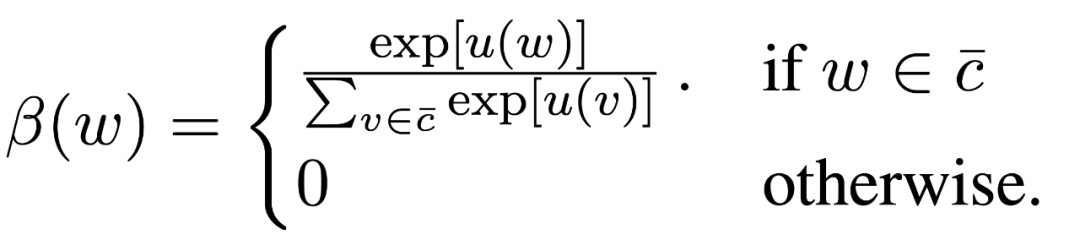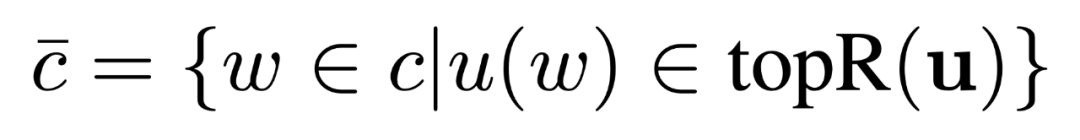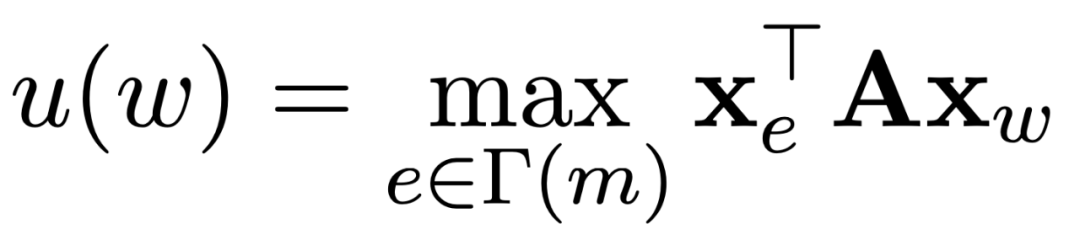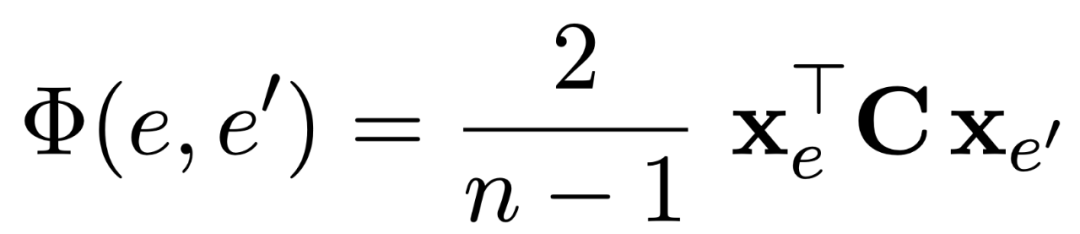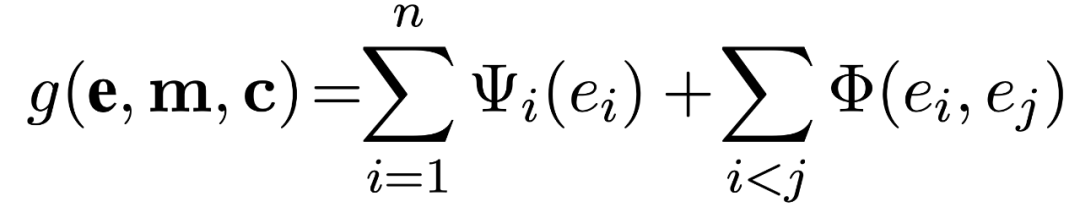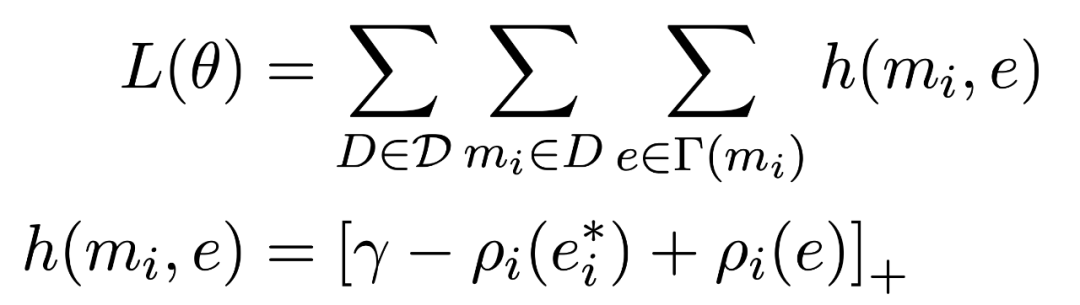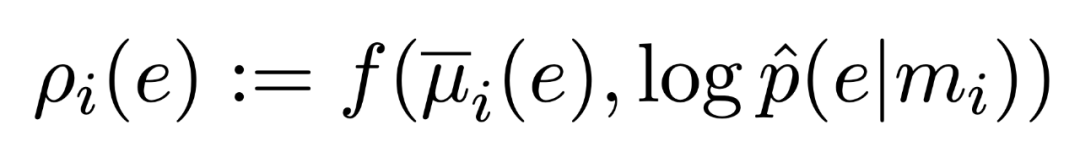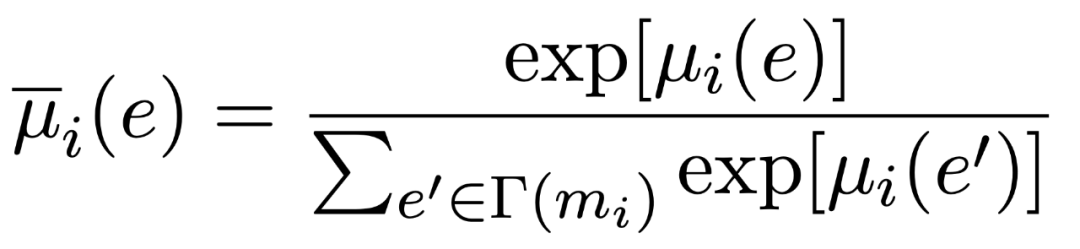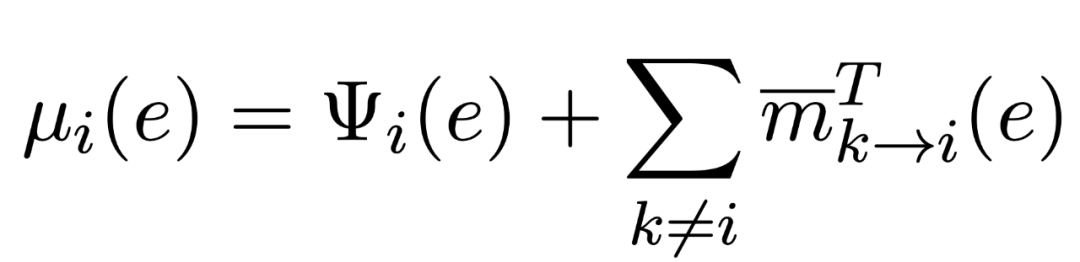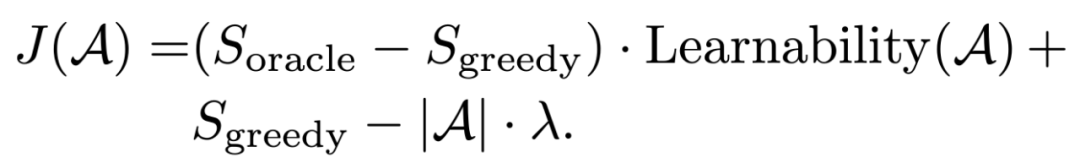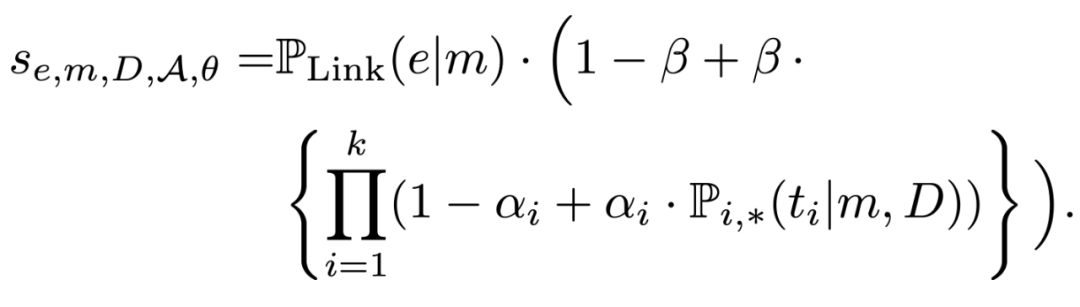本文转载自公众号:知识工场
1、什么是实体链接
实体链接(entity linking)就是将一段文本中的某些字符串映射到知识库中对应的实体上。比如对于文本“郑雯出任复旦大学新闻学院副院长”,就应当将字符串“郑雯”、“复旦大学”、“复旦大学新闻学院”分别映射到对应的实体上。在很多时候,存在同名异实体或者同实体异名的现象,因此这个映射过程需要进行消歧,比如对于文本“我正在读《哈利波特》”,其中的“《哈利波特》”应指的是“《哈利波特》(图书)”这一实体,而不是“《哈利波特》系列电影”这一实体。
当前的实体链接一般已经识别出实体名称的范围(一般称作mention),需要做的工作主要是实体(称作entity)的消歧。也有一些工作同时做实体识别和实体消歧,变成了一个端到端的任务。
实体链接一般包括候选实体生成和候选实体排序两个过程。候选实体生成指对一个mention,找到所有可能的实体作为候选项。候选实体排序指利用某些特征,对候选实体进行排序。
其中候选实体的生成可以考虑以下几个因素:
对于候选实体的排序,当前的排序方法主要包括 local disambiguation 和 global disambiguation两种。其中 local disambiguation 指对于一段文本中的多个 mention ,分别进行消歧。global disambiguation 指对于一段文本中的多个 mention 同时进行消歧,认为同一段文本中的实体具有较强的相互关联。这两种消歧分别对于 local score 和 global score 。
当前 local disambiguation 使用的特征主要包括 mention 和实体名称的相似性、mention 对应各实体的先验概率、mention 和实体的上下文的相似性。Global disambiguation 主要比较同一个文档下各实体间的 coherence ,使用的特征可以是超链接记录或上下文的相关性,衡量方法包括 context independent coherence、wikipedia link-based measure ( WLM ) 等。
接下来介绍几篇经典的论文
《Deep joint entity disambiguationwith local neural attention》- EMNLP 2017
该论文使用神经网络的方法来计算 local score 和 global score ,主要包括计算entity embeddings ,计算 local score 和 global score ,进行优化求解三个步骤。
Entity 的向量表示和 word 的向量表示属于同一个语义空间,是在基于 word2vec得到的 word embedding 的基础上 bootstrap 得到的。一个 entity 的向量会和高频共现的 word 更接近,具体的计算过程如下所示:
![]()
Local score的计算即计算entity embedding和mention上下文的word embedding 的相关性程度,为了取得更好的结果,在这里使用了 attention 来获得更强的上下文单词信息:
![]()
![]()
![]()
![]()
Global score的计算即计算两两候选实体的embedding的相关性程度:
![]()
整体的打分函数就是 local score 和 global score 的加和:
![]()
但是,这是一个 NP-hard 的问题,作者针对打分函数与 CRF 形式上的相近性进行建模,将这个问题看作一个fully-connected pairwise CRF model , 利用 belief propagation 进行优化求解:
![]()
![]()
![]()
![]()
![]()
《ELDEN: improved entity linkingusing densified knowledge graphs》-NAACL 2018
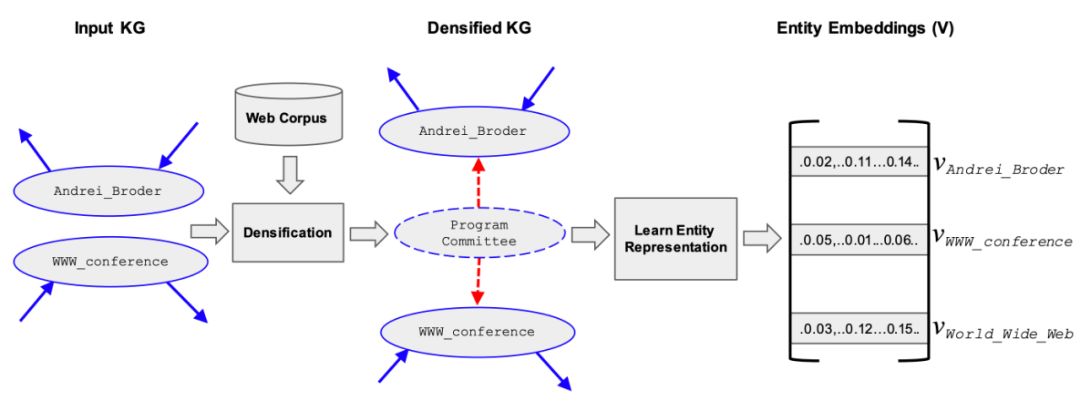
这是一篇 state of the art 的论文。它指出现有的方法中,global score 的coherence 主要基于 entity embedding 进行计算,而许多 entity embedding 是基于 KG 中实体间的边来进行计算的,对于 KG 中稀疏的部分表现不好。因此该论文使用伪实体来填充 KG 中稀疏的部分。
具体来讲,论文中将维基百科中高频出现的 unigram 和 bi-gram 短语当做伪实体,然后利用其它 web 文本中的共现信息建立伪实体和其他实体间的边。整体过程如下图所示:
![]()
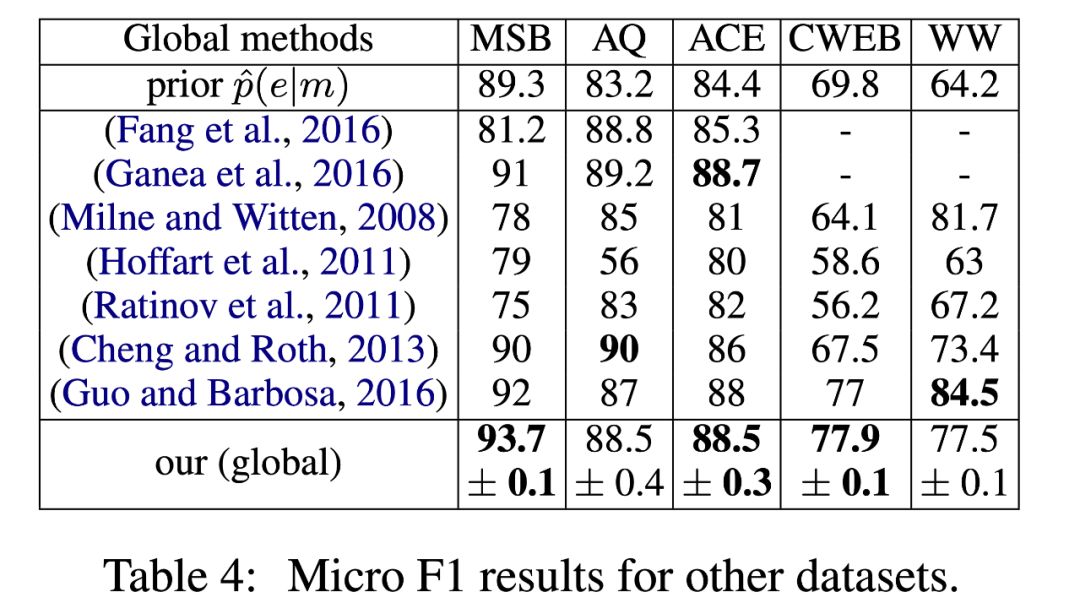
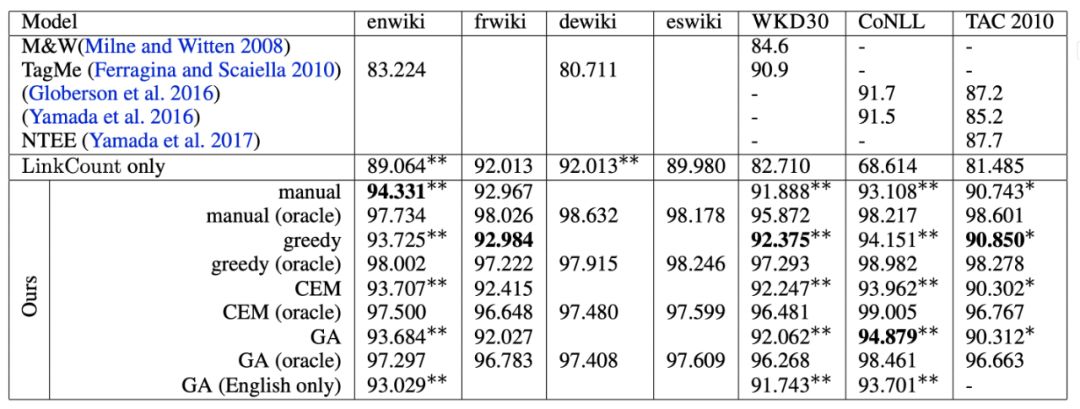
该论文测试的数据集较少,但是取得了 state of the art 的效果:
![]()
《Deeptype : multilingual entitylinking by neural type system evolution》-AAAI 2018
该论文的思路是将 type 作为约束,指导 entity linking 。这是因为在 kg 中,大多数实体都拥有 type 属性,而 type 属性的属性值往往存在于一个大的 type ontology 中。但是这个 type ontology 往往是非常大的,因此如何对这个 ontology的分支选择合适的 type 粒度,并应用到下游应用中是一个需要解决的问题。
对于这个问题的解决,该论文主要采取了两个步骤。首先,选定一个合适的 type system ,也就是确定分类器一共要分哪几个类。其次,基于这个 type system 优化文本分类器和实体链接模型。
Type system 的选择是基于两个标准进行的:learnability 和 oracle 。Learnability 用于找到分类器容易学习的 type , oracle 用于找到可以帮助提升 entity linking 效果的 type 。因此,寻找 type system 的优化目标如下所示:
![]()
对于 type system 的搜索策略,该论文也测试了遗传算法、交叉熵方法等,其结果如下:
![]()
Entity linking 的过程中,除了使用到了预测的 type ,还使用了 mention 对应entity 的先验概率:
![]()
再观察上面的实验结果可以发现,该论文仅用了先验概率和 type 约束两个特征就取得了较好的效果。
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。
![]()
点击阅读原文,进入 OpenKG 博客。