学界 | SIGIR2017满分论文:IRGAN

在现代信息检索领域一直是两大学派之争的局面。一方面,经典思维流派是假设在文档和信息需求(由查询可知)之间存在着一个独立的随机生成过程。另一方面,现代思维流派则充分利用机器学习的优势,将文档和搜索词联合考虑为特征,并从大量训练数据中预测其相关性或排序顺序标签。
本篇 SIGIR2017 的满分论文则首次提出将两方面流派的数据模型通过一种对抗训练的方式统一在一起,使得两方面的模型能够相互提高,最终使得检索到的文档更加精准。文章的实验分别在网络搜索、推荐系统以及问答系统三个应用场景中实现并验证了结果的有效性。
论文链接:https://arxiv.org/pdf/1705.10513.pdf
阅读笔记精选

Gapeng
读完整个文章,我觉得值得学习的地方有很多:
1. 把 GAN 应用到 IR 上,这个算是一个亮点。
2. 作者不是生硬地套用 GAN 的框架,而是因地制宜,根据 IR 任务的特点,巧妙设计了 G 和 D,将 IR 的生成模型和判别模型统一到 GAN 框架下。
3. IR 系统,从数据库中检索相似的信息,应对的是离散的数据,而 GAN 一般在连续情况下容易 work。常用的 SGD 在这里并不 work,作者采用 RL 的 policy gradient 作为替代。 IRGAN 将 generative retrieval model 和 discriminative retrieval model 分别作为 GAN 的 generator 和 discriminator(文章里对生成模型和判别模型的提法跟我们通常所说的刚好相反)。所以,IRGAN 训练的结果是两个 IR 系统!一个是生成模型,一个是判别模型! 作者开源了代码,做了一些实验实验:web search,item recommendation,question answering,实验结果表明,IRGAN 打败了多种 strong baselines,带来显著的性能提升。作者认为,这种性能提升得益于 GAN 的对抗训练机制。两类 IR 模型统一到 GAN 框架下,虽然它们的性能不同,但是跟没有采用对抗训练的模型相比,它们之中至少有一个能够得到显著的性能提升。

Ttssxuan
1. 信息获取主要有两种模式:a. 预测给出的文档相关性;b. 给出文档对,判别他们之间的相关性;
2. 判别模型:挖掘标注与非标注的数据中的信息,用于指导训练拟合文档内在相关性分布生成模型;
3. 生成模型:生成判别模型难以判别的例子;
4. 经典相关性模型着重于,如何从查询生成 (相关) 文档;独立模型,每个 token 是独立从相关文档档中生成;统计语言模型一般是从文档中生成查询元素;在词嵌模型中,词从其上下文中生成;在推荐系统中,也有类似的方法,从 item 的上下文中生成 item;
5. 模型扩展到 pointwise, pairwise, listwise, 其中 pointwise 基于人的判断来衡量相关性,pairwise 主要是在所有文档对中找出最相关的文档对,listwise 着重于返回最合理的相关性排序;
6. 观察到的正例和未观察到的正例之间会存在内在联系,生成器需要基于判别器的信息来快速推动这些未观察到的正例;
7. 与 conditional GAN 有些相似;
8. 生成模型提供了一种新的负采样方式;
9. 使用 IR 的奖励机制,是在传统模型中不可获取的;
10. 应用于:网页搜索在线排序(sf: LambdaRank, LambdaMART, RankNet)、item 推荐系统(cf matrix factorisation)、问答系统(退化成 IR 的评估)

illegaldata
总结 - 作者有两个思路很巧妙:
1. 不像传统的 GAN,用噪声信号作为输入做生成,然后判别,而是将 Query 做输入,直接利用 Generative 和 Discriminative IR Models 做 GAN;
2. 将 RL 的 Policy Gradient 引入针对离散的输入变量;以上两个步骤使得 GAN 更具推广意义。
Q&A 精选
hustliaohh
the generative retrieval focusingon predicting relevant documents given a query, and the discrim-inative retrieval focusing on predicting relevancy given a query-document pair.
生成模型用于预测与查询相关的文档,判别模型用于预测给出的查询对的相关性。(GAN 网络的基本原理,本文很好的将信息检索抽象成 GAN 网络的表达方式)
fryzhang: 常用的 GAN 来生成样本,都是来比较是否足够真实。IR 的任务也是给定样本,判断是否 relevant。本文的将 GAN 与 IR 结合的思路给人一种简单却又让人恍然大悟的感觉。
lgpang
which depicts the (user’s)relevance preference distribution over the candidate documentswith respect to her submitted query
这句话很重要,说明获得的信息是否符合用户提交的请求(正相关),具有很强的主观性。对于同样的搜索语句,不同的用户期盼得到的答案可能不一样。所以相关性应该是根据每个用户的搜索历史,点选历史,弃选历史量身定制的。难道这个条件概率函数要加上用户的因素,改写成 p(d | q, u, r) ?其中 u 代表特定的用户。就像 google 搜索,如果一个用户登陆了 google chrome 浏览器,那么搜索结果就会根据个人的访问历史定制。
illegaldata: 这个思路有点意思,可以试试把 web search 和 item recommendation 结合起来,就是带用户明细的训练和测试数据不太好找。
jianzhengming
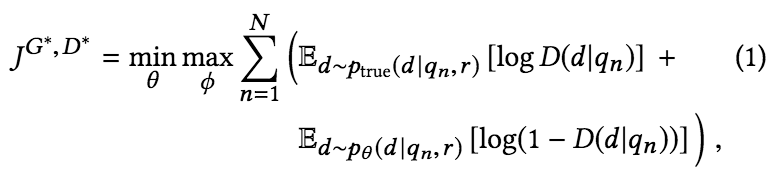
log(1-D(d|qn)) 中的 D(d|qn) 与 ptrue 中的 D(d|qn) 应该是不同的概念吧?
Ttssxuan: 是同一个概念,可以把 minmax 拆分成 min 和 max,对于 min 则是 discriminator 尽量把 ptrue 分对,尽量把 pgen 分对的减少 (1 - d),对于 max 也是类似,只是针对 generator。
argmax: 同一个概念,也是同样的函数,但计算的分布不一样。

wangbin11
sigmoid function of the discriminator score
D 的定义用 sigmod 函数定义有什么好处?用于估算概率吗?mark 一下,看完再 review 这个问题。
END: 这里跟原始 GAN 中一样吧,也是输出概率吧,也可看做是二分类问题。
想和我们一起研读优质 paper?
点击「阅读原文」提交内测申请,我们将在 48 小时内完成审核并和您取得联系。
关于 PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。


点击 | 阅读原文 | 进行报名




