DeepMind提出SAC-X学习范式,无需先验知识就能解决稀疏奖励任务
让儿童(和成年人)整理东西已经是件难事了,但是想让AI像人一样整理东西是个不小的挑战。一些视觉运动的核心技能是取得成功的关键:接近一个物体,抓住并且提起它,然后打开一个盒子,将其放入盒中。要完成更复杂的动作,必须按照正确顺序应用这些技能。
控制任务,比如整理桌子或堆叠物体,都需要智能体决定如何、何时并且在哪里协调机械臂和手指的六个关节以移动并实现目标。在某一特定时刻,可能的动作会有多种组合,并且要想把它们按顺序组合好,就产生了严重的问题——这也使得强化学习成为一个有趣的领域。
类似奖励塑造(reward shaping)、学徒式学习(apprenticeship learning)或从展示中学习有助于解决上述问题。但是,这些方法需要对任务有足够的了解——利用很少的先验知识学习复杂的控制任务仍然是未解决的挑战。
昨天,DeepMind提出了一种新的学习模式,名为“计划辅助控制(SAC-X)”以解决上述问题。SAC-X的工作原理是,为了从零开始掌握复杂任务,智能体必须先学习探索一系列基础技能,并掌握他们。正如婴儿在学会爬行和走路前必须学会保持平衡一样,让智能体学习简单技能以增强内部协调性,有助于它们理解并执行复杂任务。
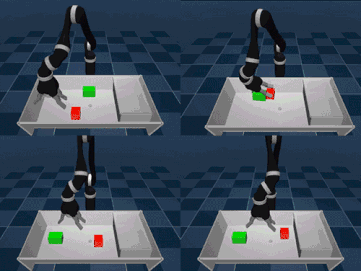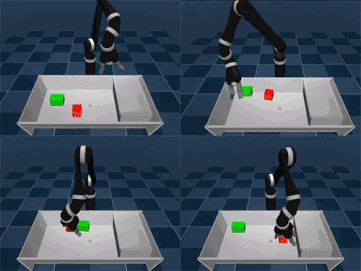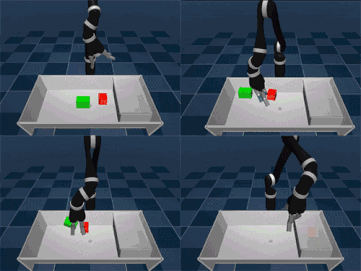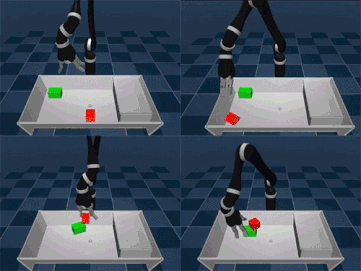
研究人员在一些模拟环境和真实机器人上试验了SAC-X方法,其中包括堆叠不同目标物体和整理桌子(其中需要移动对象)。他们所指的辅助任务的通用原则是:鼓励智能体探索它的感应空间。例如,激活手指的触觉感应器、在腕部的感应器感受力度的大小、将本体感应器的关节角度最大化或强制物体在其视觉相机传感器中移动。如果达到目标,每个任务都会得到一个简单的奖励,否则没有奖励。

智能体最后能自己决定它现在的“目的”,即下一步要完成什么目标,这有可能是一项辅助任务,或是外部决定的目标任务。重要的是,通过广泛使用off-policy学习,智能体可以检测到奖励信号并从中学习。比如,在捡起或移动目标物体时,智能体可能会不经意间完成堆叠动作,这样会使奖励观察到这一动作。由于一系列简单任务能导致稀有的外部奖励,所以对目标进行规划是十分重要的。它可以根据收集的相关知识创建个性化的学习课程。事实证明这是在如此宽广的领域开发知识的有效方式,并且当只有少量外部奖励信号可用时,这种方法更加有用。我们的智能体通过调度模块决定下一个目标。调度器在训练过程中通过元学习算法得到改进,该算法试图让主任务的进度实现最大化,显著提高数据效率。

对SAC-X的评估表示,使用相同的底层辅助任务,SAC-X能从零开始解决问题。令人兴奋的是,在实验室里,SAC-X能在真实的机械臂上从零学习拾取和放置任务。这在过去是很有难度的,因为在真实的机械臂上学习需要数据效率。所以人们通常会训练一个模拟智能体,然后再转移到真正的机械臂上。
DeepMind的研究人员认为SAC-X的诞生是从零学习控制任务的重要一步(只需要确定任务的最终目标)。SAC-X允许你设定任意的辅助任务:它可以是一般的任务(如激活传感器),也可以是研究人员需要的任何任务。也就是说在这方面,SAC-X是一种通用的强化学习方法,除了用于控制任务和机器人任务之外,能广泛适用于一般的稀疏强化学习环境。
原文地址:deepmind.com/blog/learning-playing/
论文地址:arxiv.org/pdf/1802.10567.pdf




