
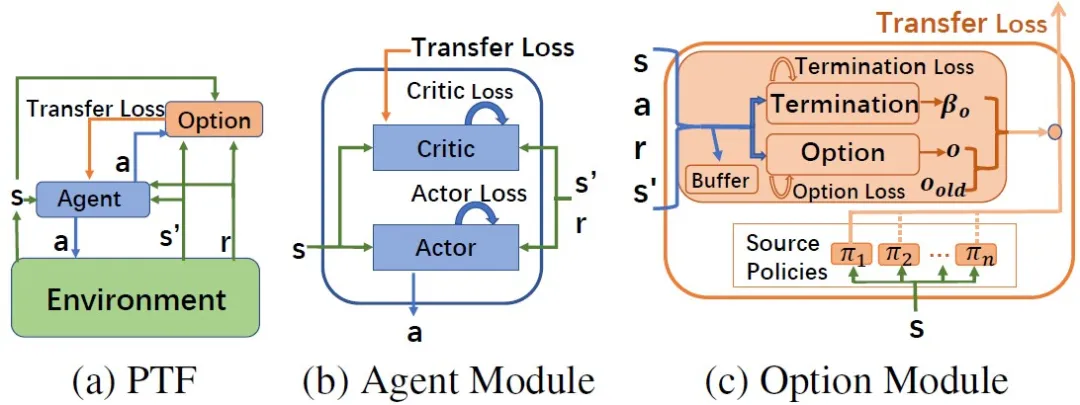
深度强化学习解决很多复杂问题的能力已经有目共睹,然而,如何提升其学习效率是目前面临的主要问题之一。现有的很多方法已验证迁移学习可利用相关任务中获得的先验知识来加快强化学习任务的学习效率。然而,这些方法需要明确计算任务之间的相似度,或者只能选择一个适合的源策略,并利用它提供针对目标任务的指导性探索。目前仍缺少如何不显式的计算策略间相似性,自适应的利用源策略中的先验知识的方法。本文提出了一种通用的策略迁移框架(PTF),利用上述思想实现高效的强化学习。PTF通过将多策略迁移过程建模为选项(option)学习,option判断何时和哪种源策略最适合重用,何时终止该策略的重用。如图1所示,PTF分为两个子模块,智能体(agent)模块和option模块。Agent模块负责与环境交互,并根据环境的经验和option的指导进行策略更新。
成为VIP会员查看完整内容
相关内容

Arxiv
4+阅读 · 2020年2月13日
相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2020年2月13日