无需奖励机制,伯克利的“反向课程”让强化学习更智能
在一些复杂任务,比如让机器人移动、互相比赛或者玩雅达利游戏时,强化学习是一个强有力的工具,它可以利用奖励机制训练一个机器人,从而改进它的行为。这样的例子有很多,但是如果想设计一种既容易训练,并在优化后能立即产生预期动作的奖励机制是非常难的。假设我们想让一台机械臂将一个中间开口的正方形套进立柱低端,一般的奖励机制是这样的:如果机械臂放对了位置,那么会得到“1”,如果位置放错,那么将得到“0”。
然而,让机械臂把正方形中间对准柱子然后再慢慢滑到底端,这个任务是无法简单地通过二元奖励机制学会的,因为初始位置并不确定,所以永远无法达到目标位置,如图1。

图1:在大多数起点,随机初始化策略无法达到目标,因此无法学习
若随机选定初始位置,机械臂无法移动到目标位置,故无法学习。
不过,研究者也可以试着改良奖励机制,能稍稍修正这一问题,但是找到一个良好的改正方法需要十分专业的知识和相当数量的实验。例如,如图2所示,简单地将正方形的中心与柱子底部的距离减到最小仍然不成功,正方形直接会撞到柱子上。

图2:从正方形中心到立柱底端生成一个惩罚函数,调整奖励,从而生成不良行为
于是,我们提出一种有效的学习方法,不用修改奖励机制,自动生成起始位置。
用课程代替奖励机制修改
我们训练的目标是,让实验对象(机械臂)从任意位置开始都能触达正确位置,无需人类调整奖励机制。显然,并不是所有起始位置的操作难度都相同。即使是从离柱子很近的位置开始操作,机械臂也并非每次都能完成任务。如果它成功了,就会获得奖励,从而开始学习。机器得到的知识可以用来解决离柱子更远的任务。通过选择起始位置的顺序,我们可以利用这个问题的底层结构提高学习效率。这种技术的重要优势之一就是不用修改奖励机制,直接优化稀疏奖励不容易产生不良行为。讲一套相关的学习任务进行排序被称为课程学习(curriculum learning),对我们来说,核心问题就是如何选择这一任务的顺序。我们利用机械臂的表现自动生成一套“课程”,先从目标的位置开始,然后慢慢向外扩展。接下来我们就给大家详细解释。
反向课程学习
在“目标导向”型任务中,最终目的就是能从任何起始位置到达目标位置。比如,还是刚刚那个“套环”任务,我们想让机械臂把中间有孔的正方形套进柱子上,不论从哪里拿起来都能做到。对大多数起始位置来说,最初的尝试均无法成功,所以奖励为0。不过,从图3可以看到,如果初始位置里柱子底端非常近的话,还是有可能将正方形放到最下面的。

图3
既然在近的地方可以成功,那么我们可以试一下较远的地方。一旦机械臂达到目标位置附近,它就知道如何做了,如图4。

图4
最终,机械臂将范围扩大也能成功套入正方形,如图5。

图5
这种反向学习或者从目标向外扩展的方法,灵感来源于动态规划(Dynamic Programming)。在DP中,较简单的子问题的解决方案通常用来解决更难的问题。
中间难度起点(SoID)
为了实施这种反向学习过程,我们需要确保这种从目标向外扩展的速度适合实验对象。换句话说,我们想用数学描述起始点的位置,记录目前实验对象的表现性能,然后为RL算法提供良好的学习信号。我们特别关注策略梯度算法,通过采取预期总奖励的预计梯度来改进参数化策略。这种对梯度的预计往往是原始强化学习算法的变体,这是通过从状态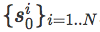


公式1
在目标导向任务中,轨迹奖励

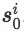
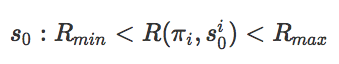
公式2

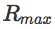
自动生成和反向课程
根据如上的知识和推倒,我们想利用SoID训练策略。但不幸的是,很难在每次策略更新的时候找到适合方程2的起点,于是我们引入了一种类似的方法自动生成逆向课程:在第一次迭代时,我们在SoID预计的起点附近采样。为了做到这一点,我们提出了一种方法,在最后一次迭代中收集轨迹,过滤掉非SoID起始点,然后对附近位置进行采样。下方视频算法进行了完整说明,详细信息如下:
动画演示了算法的主要步骤,以及它是如何自动生成合适的课程
过滤非SoID位置
在每个梯度策略迭代训练中,我们从一些初始位置
附近取样
过滤掉非SoID起点后,我们需要获取新的SoID起点,扩大范围继续训练。于是我们在剩余的SoID起点附近采样,因为这些点与当前的策略难度相似,因此也有可能符合SoID的条件。但是,应该用怎样的方法才最合适呢?我们建议从
假设
为了初始化算法,我们需要在目标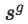
我们的算法可以从收集到轨迹起点,选择起点的分布。在许多系统中都是如此,就像所有的模拟系统一样。Kakade和Langford在此假设上提出修改起点分布的有用性的理论证据。
应用于机器人
导航到一个固定目标,以及精细地打造所需结构是机器人的两个典型任务。在以下任务中,我们分析了我们所提出的算法是如何自动生成反向课程的:
1. 点群迷宫(point-mass maze)

在这一任务中,我们想要学习如何能让一个点到达右上方的红色小球区域。
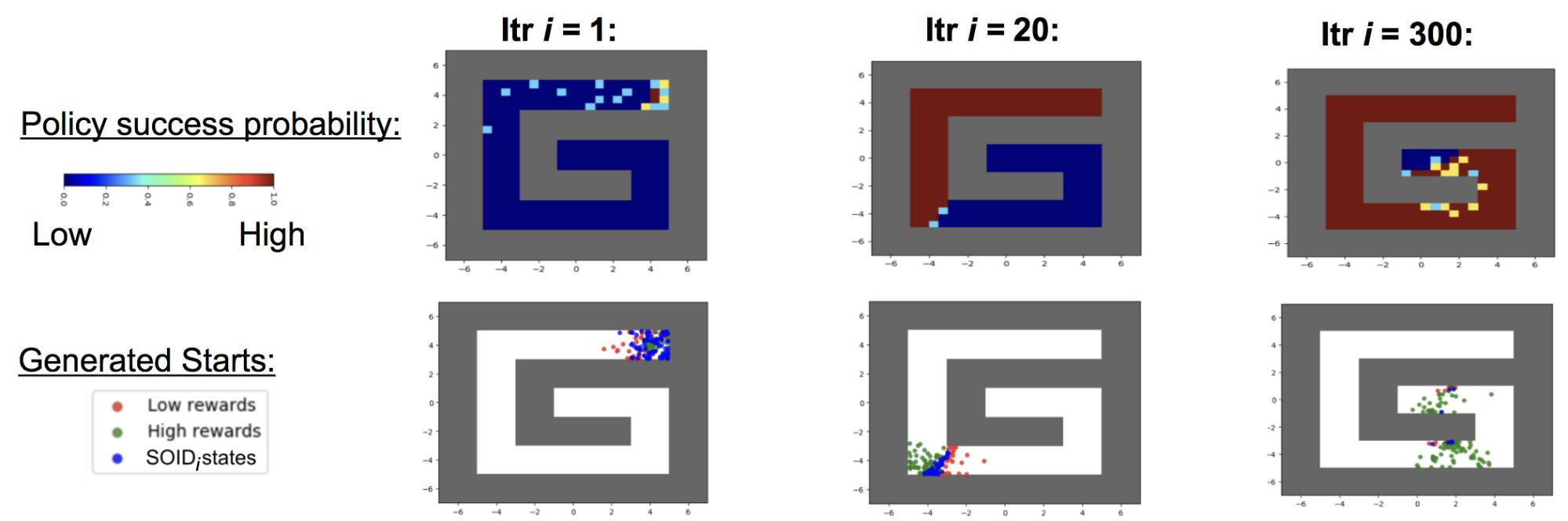
图6:反向课程生成的策略表现和起点位置,总是在中等难度区域进行跟踪
在图6中可以看到,当迭代i=1时,除了目标点周围的其他地方成功的概率都为0。第二行显示了我们的算法如何在i=1时选出目标点附近的起点。在后面两列中可以看到,在我们所提出的方法产生的起点,又是训练策略可以成功,但有时却不行,因此为其他任何策略梯度学习方法提供了良好的学习信号。
为了避免忘记是从哪一起点到达目标的,我们保留了所有之前SoID策略的replay缓存。在每次迭代训练中,我们都能从缓存中对一小部分轨迹进行采样。
2. 蚂蚁迷宫(Ant Maze Navigation)

当用我们的反向课程方法训练时,即使是稀疏的奖励,蚂蚁也会产生复杂的组合动作,并学会利用环境
机器人往往需要复杂的协调运动才能完成目标动作。例如,下图中的四足物体需要知道如何协调其所有的力矩向目标移动。在下面的动图中我们可以看到,即使试验队形在成功后只收到成功或失败的奖励,我们的算法也依然能够学习这种行为。我们没有修改奖励函数,其中不包括任何目标距离、质心速度以及探索奖励。
3. 精细化操作
我们的方法也可以解决机器人的复杂操作问题,如下两图所示:
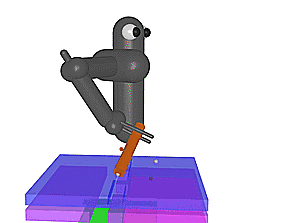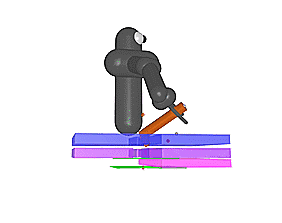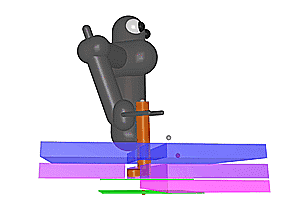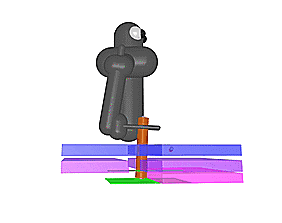
上图中的机械臂拥有七个自由度,同时具有复杂的接触约束。第一个任务要求机器人把中间有洞的正方形插入立柱底部,第二个任务要求机器人将钥匙插入所中,顺时针旋转90度,再进一步插入后再逆时针选择90度。在这两项任务中,只有实验对象完成最终任务后才会给予奖励。当前不使用课程的最先进的强化学习方法无法学习怎样解决问题,但是通过我们的反向课程生成,我们可以从更广泛的初始位置获取成功策略。
结论以及未来的方向
最近,深度学习方法正从解决单一问题向多任务集转变。这是为了更接近真实场景,因为每次当有任务需要执行时,起始配置、目标参数或其他参数都会发生变化。因此,推动课程学习从而加深理解这些任务的底层结构至关重要。我们的逆向课程策略就是朝这一方向努力的一步,如果没有课程学习,就无法在运动和复杂的任务操作中产生令人印象深刻的结果。
此外,在最终的动图中可以观察到,我们的实验对象已经学会利用周围环境运动,而非避开环境。因此,我们提出的基于学习的方法,有助于解决经典运动规划算法难以解决的问题,例如带有非刚性对象的环境或几何参数不确定的任务。接下来,我们将把生成课程方法与领域随机方法结合起来,以生成可迁移到真实世界的策略。
原文地址:bair.berkeley.edu/blog/2017/12/20/reverse-curriculum/






