数据科学家指南:梯度下降与反向传播算法
大数据文摘转载自数据派THU
作者:Richmond Alake
翻译:陈之炎
校对:zrx
人工神经网络[ANN)是人工智能技术的基础,同时也是机器学习模型的基础。它们模拟人类大脑的学习过程,赋予机器完成特定类人任务的能力。
数据科学家的目标是利用公开数据来解决商业问题。通常,利用机器学习算法来识别模式,用算法模型实现预测。如何为特定的用例选择正确的模型,并适当地调整参数?这需要对问题和底层算法有清晰的理解,即充分理解问题和算法,确保使用正确模型,并正确解释结果。
本文介绍并解释了梯度下降算法和反向传播算法。人工神经网络利用这些算法学习数据集,当神经网络中数据发生变化时,应如何去修正网络参数。
建立直觉
在深入探讨技术细节之前,首先来看看人类如何学习。
人类大脑的学习过程是复杂的,当前的研究工作只涉及到人类学习方式的表像。然而,已知的研究结果对构建模型非常有价值,与机器不同,在做逻辑预测时,人类无需借助大量的数据来解决问题,人们直接从经验和错误中吸取教训。
人类通过突触可塑性的过程来学习,突触可塑性是一个术语,用来描述在获得新的信息后,如何形成和加强新的神经连接。当人类经历新事件时,大脑中的连接会加强,通过训练人工神经网络,计算出预测的错误率,在此基础上来决策是加强或削弱神经元之间的内部连接。
梯度下降
梯度下降算法是一种标准的优化算法,通常,它是机器学习优化算法的首选算法。首先,来剖析一下术语“梯度下降”,以更好地理解它与机器学习算法之间的关系。
梯度是直线或曲线陡峭程度的量化度量,在数学上,它表示一条直线的上升或下降的方向。下降是指向下走的行为。因此,从这个术语的定义可以得出:梯度下降算法是对向下运动程度的量化。
为了训练一个机器学习算法,需要识别网络中的权重和偏差,这将有助于问题的解决。例如,在分类问题中,当查看图像时,需要确定图像是否为猫或狗。为此,必须构建模型,将需求建模为函数,更具体地说,是成本函数。成本函数又称为损失函数,利用成本函数衡量模型的出错程度。成本函数的偏导数影响模型的权重和偏差。
梯度下降是一种算法,用于搜索使成本函数最小化或准确度最优的那些参数。
神经网络中的成本函数、梯度下降和反向传播
神经网络令人印象深刻,同样令人印象深刻的是:在尚未明确告知要检测的特征的情况下,计算程序能够区分图像和图像中的对象。
把神经网络看作是一个接收输入(数据)的函数,并生成一种输出预测,该函数的变量便是神经元的参数或权重。
因此,神经网络的关键任务是以一种近似或最佳的方式来调整数据集的权重和偏差值。
下图描述了一个简单的神经网络,它接收输入(X1、X2、X3、Xn),将这些输入推送给包含权值(W1、W2、W3、Wn)的神经元。输入和权值经过乘法运算,结果由加法器()求和,激活函数调节该层的最终输出。
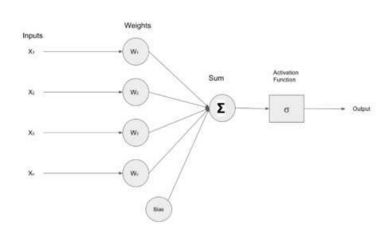
为了评估神经网络的性能,需要一种机制来量化神经网络预测值和实际数据样本值之间的差异,从而计算出影响神经网络内权重和偏差的修正因子。
成本函数填补了神经网络的预测值与数据样本的实际值之间的误差距离。
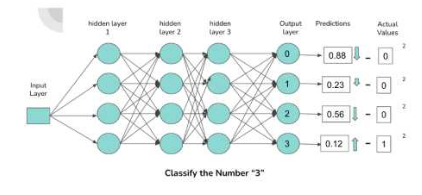
图2:神经网络内部连接和预测描述
上图描述了一个简单的密集连接神经元的神经网络结构,它对包含数字0-3的图像进行分类。输出层中的每个神经元都对应一个数字,与神经元连接的激活程度越高,神经元输出的概率就越高,该概率为通过前馈网络的数字与被激活的神经元相关联的概率。
当数字 “3”通过网络前馈时,将为 “3”分类的连接(由图中的箭头表示)分配更高的激活,使得输出与数字“3”神经元关联的概率更大。
负责神经元的激活,即偏差、权重和前一层的激活的组件有不少,这些特定的组件经过迭代修正,使得神经网络在特定的数据集上执行最优操作。
利用“均方误差”成本函数,获取神经网络的误差信息,通过网络的权值和偏差,将这些信息后向传播给神经网络进行更新。
神经网络使用的成本函数示例:
• 均方误差
• 分类交叉熵
• 二进制交叉熵
• 对数损失
在讨论完如何通过一种网络预测技术来提高神经网络的性能之后,下文将集中讨论梯度下降、反向传播和成本函数之间的关系。
图3绘制了x和y轴上的成本函数,该成本函数保存函数参数空间内的全部数值。接下来,让我们来看看神经网络是如何通过成本函数可视化来实现学习,曲线为神经网络参数空间内分布不均匀的权重/参数值。
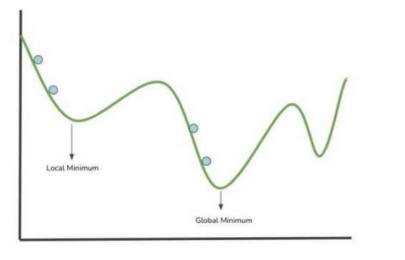
图3:可视化之后的梯度下降
上图中的蓝色点表示搜索局部最小值时进行的一个步骤(成本函数中求参数值)。模型成本函数的最低点对应于使成本函数最小的权重值的位置。成本函数越小,神经网络的性能越好。因此,可以根据上图中获取到的信息来修改网络的权重。
梯度下降是一种引导在每个步长中选取接近最小值的算法。
-
局部最小值:成本函数在指定范围内的最小参数值。 -
全局最小值:成本函数全域内的最小参数值。

-
神经网络:通过反向传播进行训练 -
反向传播 -
反向传播算法的工作原理







