©作者 | 王文
研究方向 | 计算机视觉
本文介绍一下我们中稿今年 ECCV 的一项工作。对目标检测模型所需要的数据进行标注往往是十分繁重的工作,因为它要求对图像中可能存在的多个物体的位置和类别进行标注。本文旨在减少 Detection Transformer 类目标检测器对标注数据的依赖程度,提升其数据效率。
Towards Data-Efficient Detection Transformers
论文链接:
https://arxiv.org/abs/2203.09507
代码链接:
https://github.com/encounter1997/DE-DETRs
https://github.com/encounter1997/DE-CondDETR
Detection Transformer 于 2020 年 ECCV 被提出,作为一种新兴的目标检测方法,Detection Transformers 以其简洁而优雅的框架取得了越来越多的关注。关于 Detection Transformer 的细节和后续的发展历程,本文并不作展开介绍,感兴趣的小伙伴可以参考以下文章:
https://zhuanlan.zhihu.com/p/366938351
研究动机
Detection Transformer 的开山之作是 DETR
[1]
,在常用的目标检测数据集 COCO
[2]
上,DETR 取得了比 Faster RCNN
[3]
更好的性能,但其收敛速度显著慢于基于 CNN 的检测器。为此,后续的工作大多致力于提升 DETR 的收敛性
[4,5,6,7]
。在 COCO 数据集上这些后续方法能够在训练代价相当的情况下取得比 Faster RCNN 更好的性能,表现出了 Detection Transformers 的优越性。
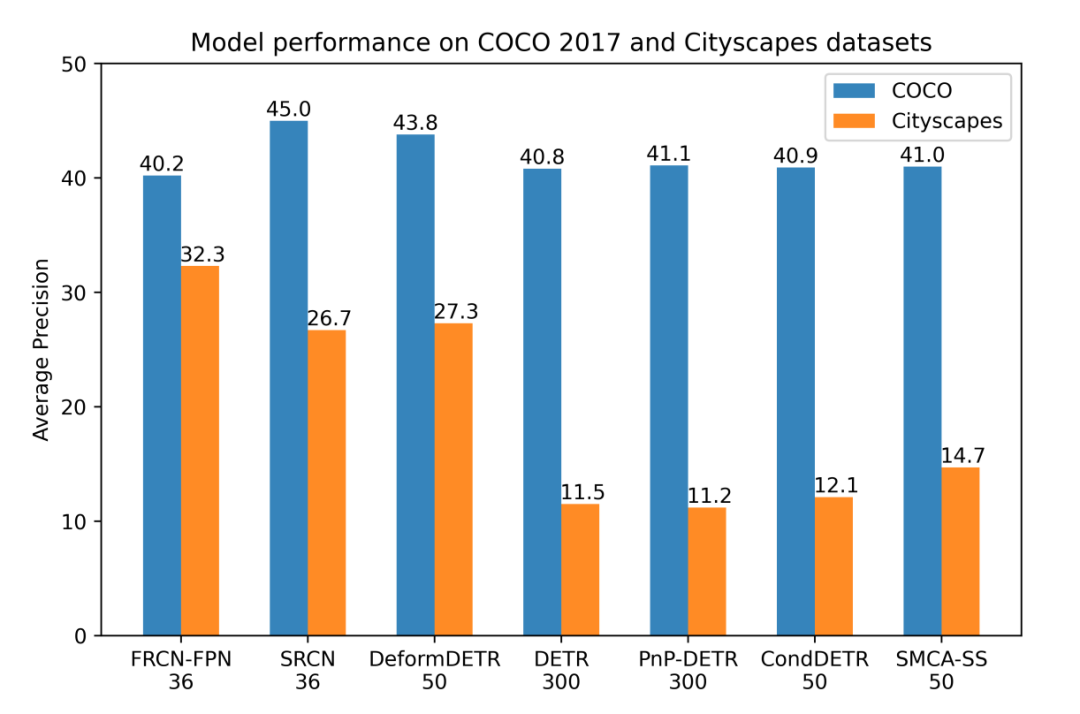
▲ 图1:不同目标检测模型在数据量充足的COCO和小数据集Cityscapes上的性能对比,模型名称下方的数字表示训练周期数。
目前的研究似乎表明 Detection Transformers 能够在性能、简洁性和通用性等方面全面超越基于 CNN 的目标检测器。但我们研究发现,只有在 COCO 这样训练数据丰富(约 118k 训练图像)的数据集上 Detection Transformers 能够表现出性能上的优越,而当训练数据量较小时,大多数 Detection Transformers 的性能下降显著。
如图 1 所示,在常用的自动驾驶数据集 Cityscapes
[8]
(约 3k 训练图像)上,尽管 Faster RCNN 能够稳定的取得优良的性能,大多数 Detection Transformers 的性能显著下降。并且尽管不同 Detection Transformers 在 COCO 数据集上性能差异不到 2AP,它们在小数据集 Cityscapes 上的性能有大于 15AP 的显著差异。
这些发现表明 Detection Transformers 相比于基于 CNN 的目标检测器更加依赖标注数据(data hungry)。然而标注数据的获得并非易事,尤其是对于目标检测任务而言,不仅需要标出多个物体的类别标签,还需要准备的标出物体的定位框。同时,训练数据量大,意味着训练迭代次数多,因此训练 Detection Transformers 需要消耗更多的算力,增加了碳排放。可见,要满足现有 Detection Transformers 的训练要求需要耗费大量的人力物力。
消融探究
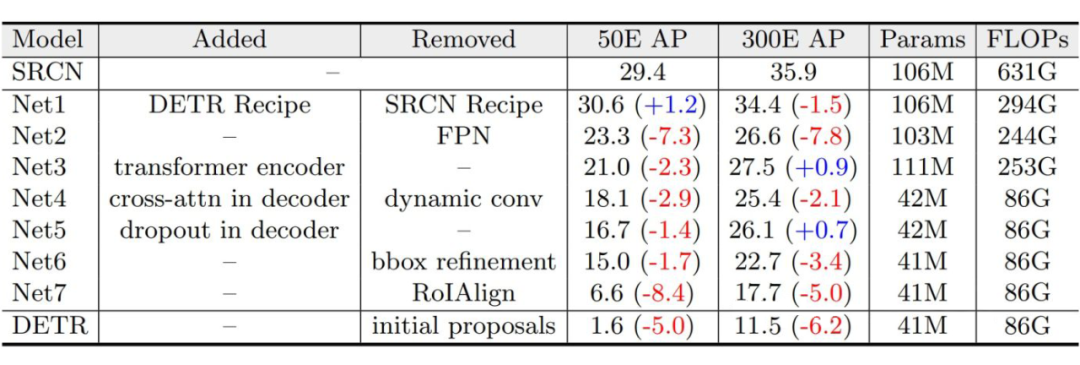
▲ 表1:从SparseRCNN(表中缩写为SRCN)到DETR的模型转化
为了寻找影响 Data-efficiency 的关键因素,我们将 data efficient 的 RCNN 逐步转化为 data hungry 的 Detection Transformer 检测器,来消融不同设计的影响。值得一提的是,ATSS
[9]
和 Visformer
[10]
采用了类似的模型转化实验,但 ATSS 旨在寻找 anchor free 检测器和 anchor-based 检测器之间的本质区别,Visformer 旨在寻找对分类任务有利的 transformer backbone 结构,而我们致力于寻找影响 Detection Transformers 数据效率的主要因素。
为了从模型转化中获得 insightful 的结果,我们需要选择合适检测器展开实验。综合一下因素,我们选择 Sparse RCNN 和 DETR 来展开实验:1)它们分别是 RCNN 和 Detection Transformer 中有代表性的检测器;2)二者有很多相似的地方,比如相同的优化器、标签匹配、损失设计、数据增强和端到端等,这有利于我们尽可能排除其他影响因素的干扰,专注于核心的区别;3)二者在 data efficiency 上存在显著差异。模型转化过程如表 1 所示,接下来,我们挑选模型转化中的关键步骤进行介绍:
去除 FPN。 由于 CNNs 具有局部性,FPN 中能够以较小的计算代价实现多尺度特征融合,从而在少量数据的情况下提升目标检测的性能。对比之下,DETR 中的 attention 机制具有全局感受野,导致其在高分辨率的特征图上需要消耗大量的运算资源,因此在 DETR 上做多尺度特征的建模往往是难以实现的。在本步中,我们去除 RCNN 中的 FPN,并且与 DETR 一致,我们仅将 backbone 中 32 倍下采样的特征送入检测头做 RoI Align 和后续解码和预测。和预期的一样,去除 FPN 的多尺度建模作用,在 50 代的训练周期下模型性能下降显著 by 7.3 AP。
加入 Transformer 编码器。 在 DETR 中,transformer 编码器可以看作是检测器中的 neck,用来对 backbone 提取的特征做增强。在去除 FPN neck 后,我们将 DETR 的编码器加入模型得到表 1 中的 Net3。有趣的是,Net3 在 50 个训练周期下的性能下降,而在 300 个训练周期下性能有所提升。我们猜想像 ViT
[11]
一样,解码器中的 attention 具有平方复杂度,因此需要更长的训练周期来收敛并体现其优势。
将动态卷积替换为自注意力机制。 SparseRCNN 中一个非常有趣的设计是解码器中的动态卷积,它的作用和 DETR 中的 cross-attention 作用十分相似,即根据图像特征和特定 object candidate 的相似性,自适应地将图像中的信息聚合到 object candidate 中。在本步骤中,我们将动态替换为 cross-attention,对应的结果如表中 Net4 所示。反直觉的,参数量大并不一定会使模型更依赖数据。事实上,含有大量参数的动态卷积能够比参数量很小的 cross-attention 表现出了更好的数据效率。
去除 RoIAlign。 SparseRCNN 和 RCNNs family 中的其他检测器一样根据目标检测的候选框对图像中指定区域的特征做采样,再基于采样后的特征做预测。对比之下,DETR 中 content query 直接从图像的全局特征中聚合特定物体的信息。在本步骤,我们去除 RoI Align 操作。可以看到,模型的性能发生了显著下降。我们猜想从全局特征中学习如何关注到包含特定物体的局部区域是 non-trivial 的,因此模型需要从更多的数据和训练周期中学习到 locality 的特性。而在见过的数据量小的情况下性能会显著下降。
去除初始的 proposal。 最后,DETR 直接预测 normalized 检测框中心坐标和宽度和高度,而 RCNNs 预测 gt 检测框相较于初始 proposal 检测框的 offsets。在本步骤中,我们消除此差异。这一微小的区别使得模型性能显著下降,我们猜想这是因为初始的 proposal 能够作为一种空间位置上的先验,帮助模型关注特定的物体区域,从而降低了从大量数据中学习关注局部区域的需要。
总结: 综上,可以看出以下因素对模型的 data efficiency 其关键作用:1)从局部区域的稀疏特征采样,例如采用 RoIAlign;2)多尺度特征融合,而这依赖于稀疏特征采样使得其运算量变得可接受;3)相较于初始的空间位置先验作预测。其中(1)和(3)有利于模型关注到特定的物体区域,缓解从大量数据中学习 locality 的困难。(2)有利于充分利用和增强图像的特征,但其也依赖于稀疏特征。
值得一提的是,在 DETR family 中,Deformable DETR
[4]
是一个特例,它具有较好的数据效率。而我们基于 Sparse RCNN 和 DETR 的模型转化实验得到的结论同样也能够说明为什么 Deformable DETR 的具有较好的数据集效率:Multi-scale Deformable Attention 从图像局部区域内做特征的稀疏采样,并运用了多尺度特征,同时模型的预测是相对于初始的 reference point 的。
我们的方法 3.1 模型增强
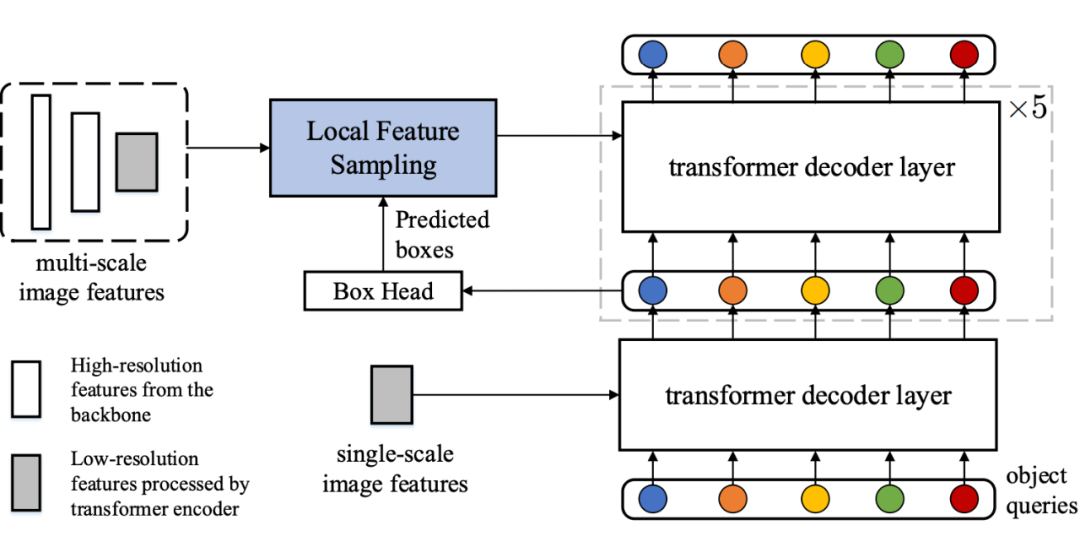
▲ 图2:我们的数据高效Detection Transformer模型结构。我们力求在尽可能少改动原模型的情况下,提升其数据效率。模型的backbone、transformer编码器和第一个解码器层均未变化
局部特征采样。 从模型转化中的分析中可以看出,从局部物体区域做特征采样对实现数据效率是至关重要的。幸运的是,在 Detection Transformer 中,由于 Deep Supervision
[12]
的存在,每一层解码器层中都为我们提供了物体检测框的信息。因此,我们可以在不引入新的参数的情况下,借助这些物体定位框来做局部特征采样。尽管可以采用更成熟的特征采用方法,我们采用最常用的 RoI Align。从第二层解码器层开始,我们借助前一层解码器的输出来做稀疏特征采样。
迭代式预测和初始参考点。 此外,Detection Transformer 中级联的结构很自然地适合使用迭代式的检测框 refinement 来提升检测的性能。我们在模型转换中的实验也表明,迭代式的预测以及相对于初始的空间参考做预测有利于实现更准确的目标检测。为此,我们引入检测框的迭代式 refinement 和初始参考点。
多尺度特征融合。 多尺度特征的运用有利于特征的高效利用,能够在数据量小的情况下提升检测性能。而我们的稀疏特征采样也使得在 Detection Transformer 中使用多尺度特征成为可能。尽管更成熟的多尺度融合技术可能被使用,我们仅仅利用 bbox 作为指导,对不同尺度的特征做 RoIAlign,并将得到的序列 concatenate 在一起。
3.2 标签增强
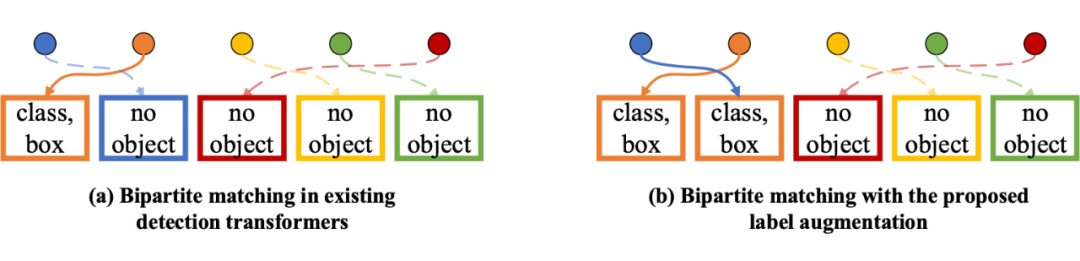
▲ 图3:(a) 现有Detection Transformer的标签分配方式;(b) 使用标签增强后的标签分配。圆圈和矩形框分别表示模型的预测和图片上的物体标注。通过复制橙色方框表示的物体标注,蓝色圆圈表示的模型预测也在标签分配中匹配到了正样本,因此得到了更丰富的监督信号。
尽管一对一的标签匹配形式简单,并能够避免去重过程,但也使得在每次迭代中,只有少量的检测候选能够得到有效的监督。模型不得不从更大量的数据或者更多的训练周期中获得足够的监督信号。为了解决这一问题,我们提出一种标签增强策略,通过在二分图匹配过程中重复正样本,来为 Detection Transformer 提供更丰富的监督信号,如图 3 所示。
在实现过程中,我们考虑两种不同的方式来复制正样本的标签,即
1)固定重复次数 (Fixed Repeat Time):我们对所有正样本标签重复相同的次数;
2)固定正负样本标签的比例 (Fixed positive-negative ratio):我们对正样本的标签进行重复采样,最终保证标签集合中正样本的比例固定。默认的,我们采用固定重复两次的标签增强方式。
实验
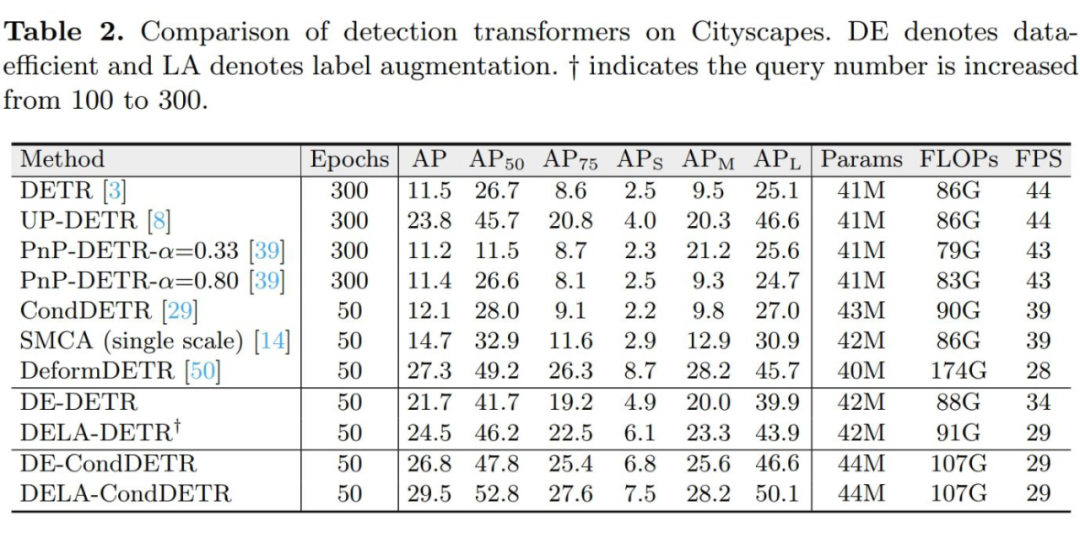
▲ 表2:不同方法在小数据集Cityscapes上的性能比较
在本部分,我们首先将我们的方法和现有的 Detection Transformer 进行比较。如表 2 所示,大部分 Detection Transformer 面临数据效率低下的问题。而我们的 DE-CondDETR 在对 CondDETR 模型做微小改动的情况下能够取得和 Deformable DETR 相当的数据效率。而辅助以标签增强提供的更丰富的监督,我们的 DELA-CondDETR 能够取得比 Deformable DETR 更佳的性能。
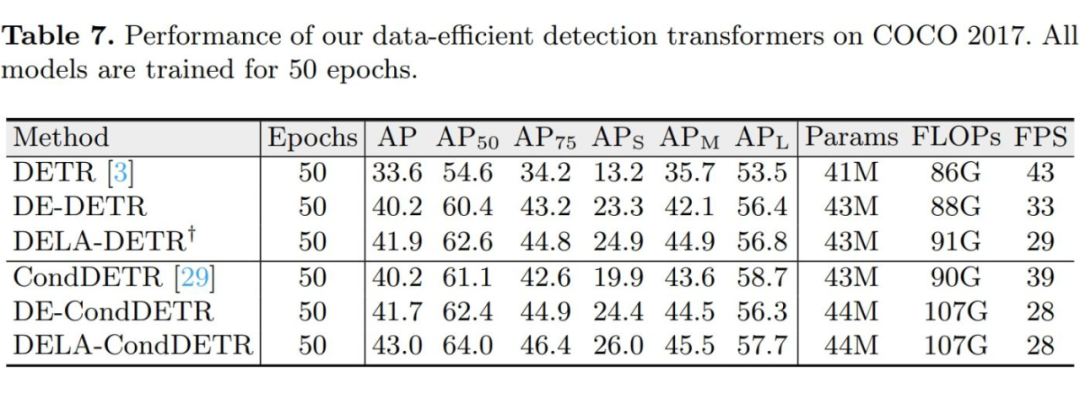
同样的,我们的方法也能够与其他 Detection Transformer 结合来显著提升其 data efficiency,例如我们的 DE-DETR 和 DElA-DETR 能够在以仅仅 50 周期取得比 DETR 500 个周期要显著优越的性能。
▲
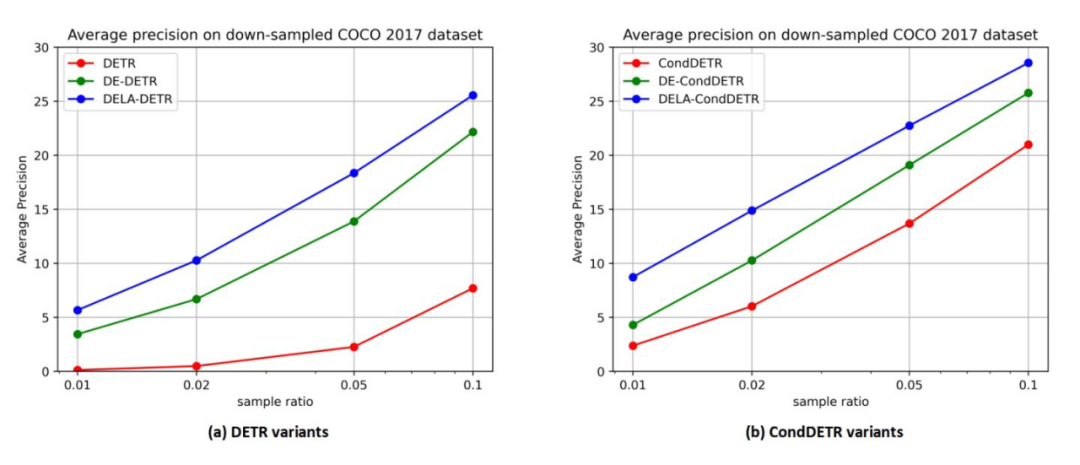
此外我们对 COCO 2017 中的训练数据进行训练图像 0.1,0.05,0.02 和 0.01 倍的采样,来观察模型在不同数据量下的性能。如图 4 所示,在不同的训练数据量下,我们的方法始终能够取得显著优于基线方法的性能。特别的,仅用 0.01 倍的数据 DELA-DETR 的性能显著优于使用五倍数据的 DETR 基线。类似的,DELA-CondDETR 性能始终优于用两倍数据训练的 CondDETR 基线。
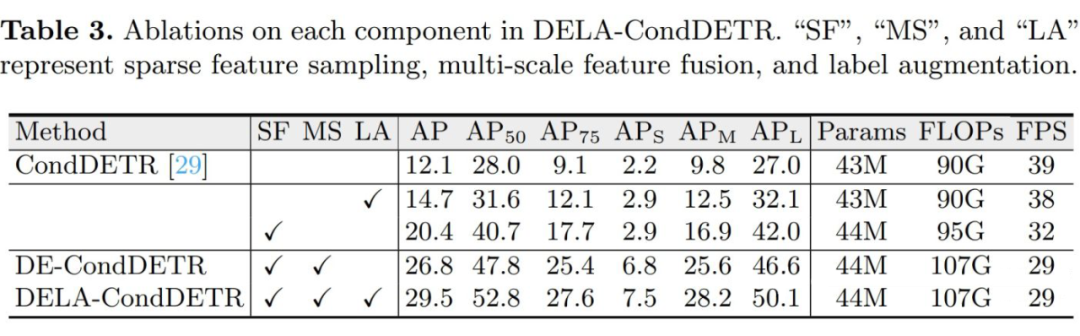
我们首先消融我们方法中各个模块的作用,如表 3 所示。 使用局部特征采样和多尺度特征均能够显著提升模型的性能,分别带来 8.3 AP和 6.4 AP 的提升。此外,使用标签增强能够进一步带来 2.7 AP 的性能提升。并且单独使用标签增强也能够带来 2.6 的性能提升。
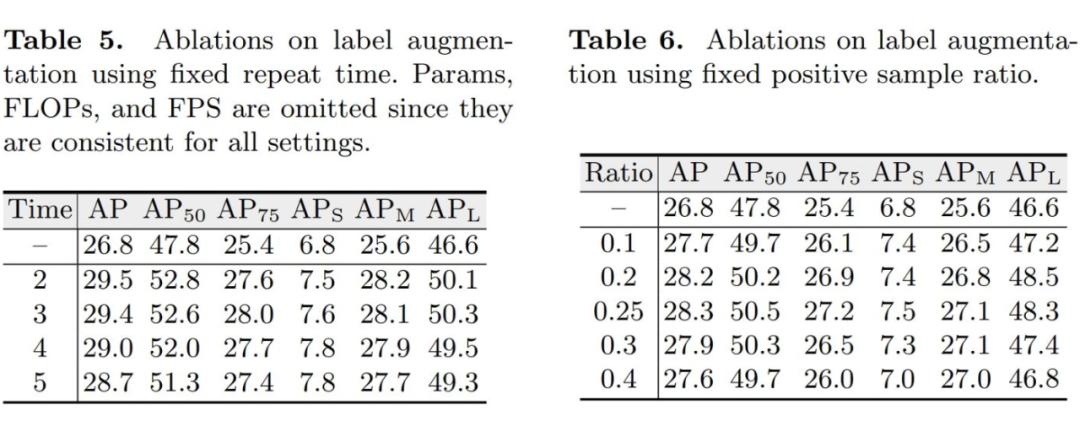
如方法部分中讨论的,我们考虑了两种标签增强策略。包括固定重复次数和固定正负样本比例。在本部分,我们对这两种策略进行消融。如上表中左表所示,使用不同的固定重复倍数均能够提升 DE-DETR 的性能,但随重复次数增加,性能提升呈下降趋势。我们默认采用重复正样本标签 2 次。
此外,如右表所示,尽管使用不同正负样本比例均能带来性能提升,在正负样本比例为 1:3 时,其取得的性能最佳,有趣的是,这也是 RCNN 系列检测器如 Faster RCNN 中最常用正负样本采样比例。
▲
尽管以上实验说明了我们的方法能够在数据量有限的情况下显著提升模型性能,它并不能表明我们的方法在数据量充足时依然有效。为此,我们在数据量充足的 COCO2017 上测试我们方法的性能。有趣的是,我们的方法不仅不会降低模型在 COCO 2017 上的性能,还能带来不小的提升。具体来说,DELA-DETR 和 DELA-CondDETR 分别相较于它们的 baseline 提升 8.1A P和 2.8AP。
▲
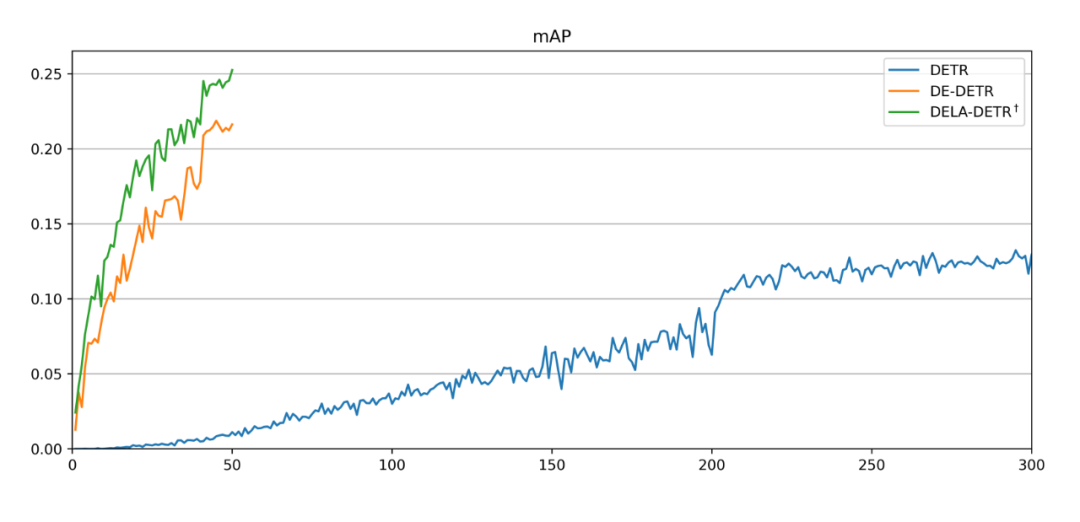
最后,为了对本文方法带来的性能提升有一个直观的感受,我们提供了不同 DETR 变种在 Cityscapes 数据集上的收敛曲线,如图 5 所示。可以看出,我们的方法能够以更少的训练代价取得更加优越的性能,展示了其优越的数据效率。更多实验结果请参考原文及其附加材料。
总结
在本文中,我们指出了 Detection Transformer 数据效率低下的问题,并通过逐步的模型转化找了影响数据效率的关键因素。随后,我们以尽可能小的模型改动来大幅提升现有 Detection Transformer 的数据效率,并提出一种标签增强策略进一步提升其性能。随着 Transformer 在视觉任务中越发流行,我们希望我们的工作能够激发社区探究和提升 Transformer 在不同任务上的数据效率。
[1] End-to-end Object Detection with Transformers
[2] Microsoft COCO: Common Objects in Context
[3] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
[4] Deformable DETR: Deformable Transformers for End-to-End Object Detection
[5] Conditional DETR for Fast Training Convergence
[6] PnP-DETR: Towards Efficient Visual Analysis with Transformers
[7] Fast Convergence of DETR with Spatially Modulated Co-Attention
[8] The Cityscapes Dataset for Semantic Urban Scene Understanding
[9] Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection
[10] Visformer: The Vision-Friendly Transformer
[11] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
[12] Deeply-Supervised Nets
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读 ,也可以是学术热点剖析 、科研心得 或竞赛经验讲解 等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品 ,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬 ,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱: hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02 )快速投稿,备注:姓名-投稿
△长按添加PaperWeekly小编
🔍
现在,在「知乎」 也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」 订阅我们的专栏吧