DETR在目标检测一样能打!DINO: 让目标检测拥抱Transformer(开源)

极市导读
DINO(DETR withImproved deNoising anchOr boxes),从三月初霸榜至今(7月),该模型第一次让DETR (DEtection TRansformer)类型的检测器取得了目标检测的SOTA性能,在COCO上取得了63.3 AP的性能,相比之前的SOTA检测器将模型参数和训练数据减少了十倍以上! >>加入极市CV技术交流群,走在计算机视觉的最前沿
PR一下我们@hzhang@隆啊隆最近刷榜COCO的目标检测模型,DINO(DETR withImproved deNoising anchOr boxes),从三月初霸榜至今(7月),该模型第一次让DETR (DEtection TRansformer)类型的检测器取得了目标检测的SOTA性能,在COCO上取得了63.3 AP的性能,相比之前的SOTA检测器将模型参数和训练数据减少了十倍以上!

论文:https://arxiv.org/abs/2203.03605
代码:https://github.com/IDEACVR/DINO ,现已开源!
主要特性:
-
SOTA性能:在大模型上以相对较小的数据和模型(~ 1/10相比之前SwinV2)取得了最好的检测结果。在ResNet-50的标准setting下取得了 51.3 AP。 -
End2end(端到端可学习) :DINO属于DETR类型的检测器,是端到端可学习的,避免了传统检测器许多需要手工设计的模块(如NMS)。 -
Fast converging(收敛快) :在标准的ResNet-50 setting下,使用 5 个尺度特征(5-scale)的 DINO 在 12 个 epoch 中达到 49.4 AP,在 24 个 epoch 中达到 51.3 AP。使用4个尺度特征(4-scale)的DINO达到了了类似的性能并可以以 23 FPS 运行。
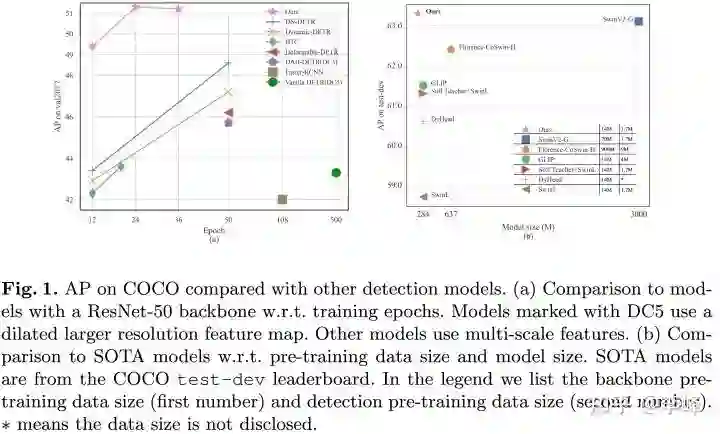
效果展示


Motivation 出发点
Transformer如今被广泛应用于自然语言处理和计算机视觉,并在很多主流的任务上都取得了最好的性能。然而,在目标检测领域,DETR这种基于Transformer的检测器虽然作为一种很有新意的检测器,但却没有作为一种主流的检测器得到广泛运用。例如,几乎所有的模型在PaperWithCode(https://paperswithcode.com/sota/object-detection-on-coco)的榜单上都是使用传统的CNN检测头 (如HTC[1])。
因此,我们很感兴趣的事就是,DETR这种简洁、端到端可学习的目标检测器,同时还有更强的模型Transformer的加持,能否无法取得更好的表现?
答案是肯定的。
Background 背景简介
在做DINO之前,我们实验室的几个同学完成了DAB-DETR[2] 和DN-DETR[3] ,DINO也是我们几个同学一起接着这两篇工作的一个延续,沿用了这些设计。
DAB-DETR是在思考DETR query理解的问题。它直接把DETR的positional query显示地建模为四维的框 ,同时每一层decoder中都会去预测相对偏移量 并去更新检测框,得到一个更加精确的检测框预测,动态更新这个检测框并用它来帮助decoder cross-attention来抽取feature。
DN-DETR是在思考DETR中的二分图匹配问题,或者说标签分配问题。我们发现DETR中的二分匹配在早期十分不稳定,这会导致优化目标不一致引起收敛缓慢的问题。因此,我们使用一个denoising task直接把带有噪声的真实框输入到decoder中,作为一个shortcut来学习相对偏移,它跳过了匹配过程直接进行学习 (详细理解在我之前的文章:https://www.zhihu.com/question/517340666/answer/2381304399)。
这两篇文章让我们对DETR的理解加深了很多,同时也把DETR类型模型的效果做到了和传统CNN模型在收敛速度和结果上comparable。如何进一步提高检测器性能和收敛速度?我们可以沿着DAB和DN去进一步思考:
-
DAB让我们意识到query的重要性,那么如何学到更好的或者初始化更好的query? -
DN引入了去噪训练来稳定标签分配,如何进一步优化标签分配?
Method 方法简介
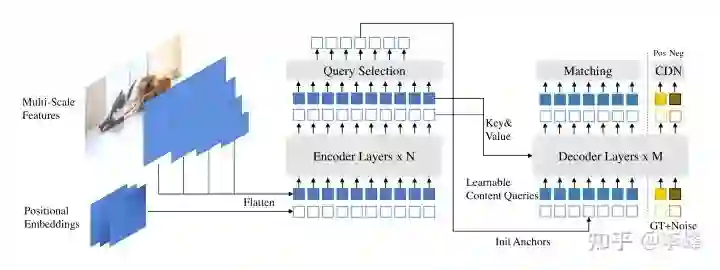
为了解决上面提到的问题,DINO进一步提出了3个改进来进行优化,模型架构如上图所示。
1.Contrastive denoising(DN)
DN的去噪训练里面引入的噪声样本都是正样本来进行学习,然而模型不仅需要学习到如何回归出正样本,还需要意识到如何区分负样本。例如,DINO的decoder中用了900个query,而一张图中一般只会有几个物体,因此绝大部分都负样本。
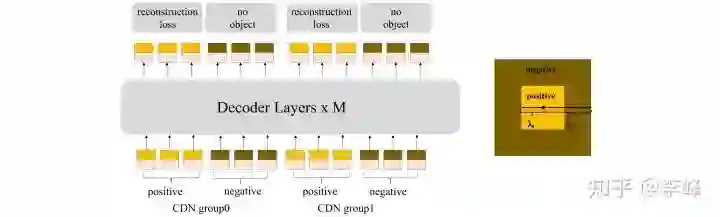
因此,我们设计了训练模型识别负样本的方法,如上图所示,我们对DN进行了改进,不仅要回归真实框,还需要辨别负样本。对于DN的输入当对真实框加入了较大噪声时,我们就认为其为负样本,在去噪训练中会被监督不预测物体。同时,这些负样本恰好是在真实框附近的,因此是相对很难区分难的负样本,让模型得以学习的正负样本的区分问题。
2. Mix query selection
在大部分detr模型中,query是从数据集中学习出来的,并不和输入图片相关。为了更好得初始化decoder query,deformable detr[4]提出用encoder的dense feature中预测出类别和框,并从这些密集预测中选出一些有意义的来初始化decoder feature。
然而,这种方式并没有在后来的工作中得到广泛运用,我们对这种方式进行了一些改进并重新强调其重要性。在query中,我们实际更关心position query,也就是框。同时,从encoder feature中选取的feature作为content query对于检测来说并不是最好的,因为这些feature都是很粗糙的没有经过优化,可能有歧义性。例如对“人”这个类别,选出的feature可能只包含人的一部分或者人周围的物体,并不准确,因为它是grid feature。
因此,我们对此进行了改进,让query selection只选择position query,而利用可学习的content query。
3. Look forward twice
这个方法对decoder的梯度传播进行了一些优化,这里就不展开讲了,可以到我们的paper进一步阅读。
总结
我们希望DINO能给大家带来一些启示,它具有SOTA的性能,端到端优化的简洁,以及快速收敛、训练和 inference快等多个优点。
同时也希望DETR类型的检测器得到更多人的运用,让大家意识到DETR类型的检测器不仅是一种novel的方法,同时也具拥有强健的性能。
参考
-
^HTC https://arxiv.org/abs/1901.07518 -
^DAB-DETR https://arxiv.org/abs/2201.12329 -
^DN-DETR https://arxiv.org/pdf/2203.01305.pdf -
^https://arxiv.org/abs/2010.04159
公众号后台回复“项目实践”获取50+CV项目实践机会~

# 极市原创作者激励计划 #

“
点击阅读原文进入CV社区
收获更多技术干货


