CVPR 2022|基于Transformer的高质量实例分割方法Mask Transfiner

极市导读
本文介绍一篇基于Transformer的高质量实例分割论文 Mask Transfiner for High-Quality Instance Segmentation。不同于现有方法统一处理整张图片,Mask Transfiner提出了新颖的信息损失区域检测机制,并且在三个大规模实例分割数据集COCO,Cityscapes和BDD100K上均取得了明显的性能提升,尤其是在物体的边缘区域。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

项目主页: https://www.vis.xyz/pub/transfiner
代码及模型: https://github.com/SysCV/transfiner
论文: https://arxiv.org/abs/2111.13673
本文介绍一篇基于Transformer的高质量实例分割论文 Mask Transfiner for High-Quality Instance Segmentation [CVPR 2022]。Mask Transfiner在产生高精度物体分割结果的同时,避免了传统Transformer模型的高内存及计算负担。不同于现有方法统一处理整张图片,Mask Transfiner提出了新颖的信息损失区域(Incoherent Regions)检测机制,在此基础上构造了四叉树结构(Quadtree Structure),使用Transformer将信息损失区中的空间离散点作为序列输入以自纠正预测错误。Transfiner在三个大规模实例分割数据集COCO,Cityscapes和BDD100K上均取得了明显的性能提升,尤其是在物体的边缘区域。例如,使用R50-FPN作为backbone,Transfiner在COCO数据集上boundary AP提高了5.6,mask AP提高了3.0。
是否使用Mask Transfiner:

和PointRend做对比-例1:

和PointRend做对比-例2:

在BDD100K上与Mask R-CNN对比:

Mask Transfiner 四叉树的渐变优化过程:

引言
实例分割是计算机视觉中的一个基础任务,需要预测图像中每个像素点的实例标签,并区分不同的物体。然而,实例分割的效果提升很大程度上是由物体检测器的发展推动的,基于 Mask R-CNN 和 DETR 的方法在 COCO Challenge中取得了领先性能。尽管这些方法在物体的检测方面表现出色,如图1所示,我们观察到分割物体的mask在高频区域仍过度地粗糙和平滑,并有大量的边缘像素点被错分。准确且高质量的实例分割不仅需要考虑图像的高层语义,也需要大分辨率的深度特征图以保留物体细节,与此同时,大尺寸会带来高计算量和内存消耗。因此,高效及非常准确的实例分割是极具挑战的。

为了解决以上问题,本文提出基于Transformer的高质量实例分割算法Mask Transfiner。如图 2 ,不同于常规方法,Transfiner首先识别容易出错并需要优化的像素区域(黄色标识),并把这些像素点按四叉树结构表示。这些像素点是根据下采样物体mask的信息损失而计算得到,主要分布在物体边界或高频区域中,空间上不连续。我们把这些区域称为信息损失区域(Incoherent Regions)。它们位置稀疏,仅占总像素的一小部分。然而,通过实验分析,我们发现这一区域对最终分割性能非常重要。这允许Transfiner在预测物体mask的过程中只处理在高分辨率特征图上的少部分区间。
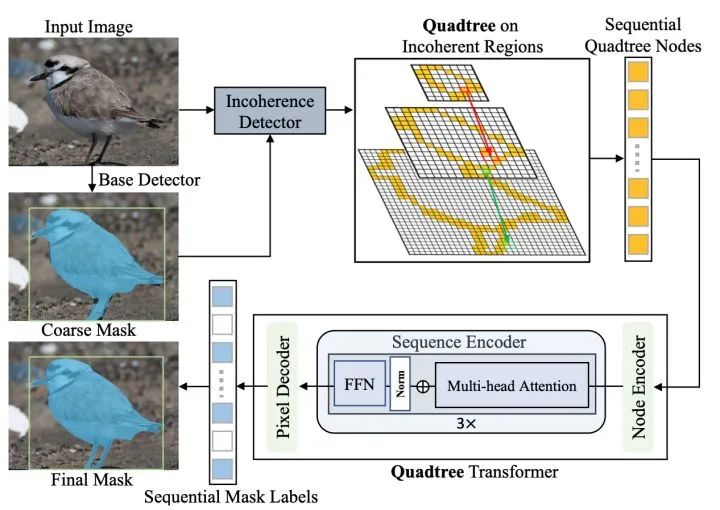
结合信息损失区域的离散分布特点,Transfiner通过构建四叉树结构来表示多层级上不同的离散点。为了预测每个树节点实例标签,由于点分布在不连续的空间上,Transfiner没有采用卷积网络,而设计了基于Transformer的分割网络。Transfiner将这些离散的节点转为无序的像素序列。它包含三个模块:节点编码器 (Node Encoder)、序列编码器 (Sequence Encoder)和像素解码器 (Pixel Decoder)。节点编码器首先丰富每个点的特征表示,例如补充点的位置编码和临近点局部细节信息。然后,序列编码器将节点序列作为Query输入基于Transformer的序列编码器中。最后,像素解码器预测每个点对应的实例标签。与PointRend中使用的MLP相比,特征点的序列化输入和多头注意力使得Transfiner能够灵活地将多个尺度的稀疏特征点同时建模,并对每个特征点的关系进行长距离比较和跨层级地进行关联。
Mask Transfiner的算法框架
【信息损失区域(Incoherent Regions)的定义】
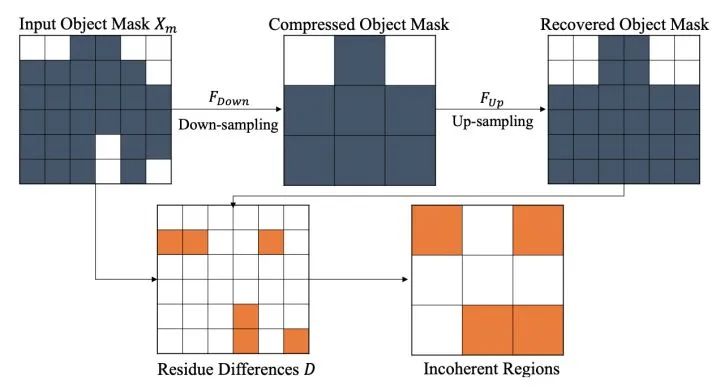
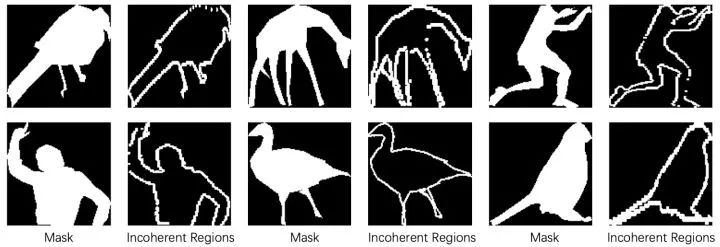
实例分割的边缘错误很多是空间分辨率过低产生的,例如对物体标注mask的下采样、过小的RoI池化、和基于PCA/DCT的系数压缩等。这些分割方法把低分辨率特征作为输入,由于丢失了高分辨率图上的物体细节,使准确地分割物体细节非常困难。为了解决这个问题,同时减少高分辨率带来的计算负担,我们提出了信息损失区域(Incoherent Regions),即计算物体Mask由于空间分辨率降低而信息损失的区域。如图 3 所示,我们首先对GT Mask标注Xm进行下采样,模拟mask压缩而导致的信息丢失,再将被压缩过的mask做上采样重建,并对重建前后的mask信息损失的区域计算残差。图4是GT物体mask生成incoherent mask的结果,如中间的列,可以看到incoherent region覆盖了鸟/长颈鹿的腿部及人的手指等细节区域。
在表 1 中,我们对信息损失区域进行了实验分析,发现很大部分分割误差集中在这些区域。它仅占物体对应的边界框区域面积的14%,却占所有错误预测像素点的43%。在信息损失区域中,coarse mask预测的精度仅为56%。通过进一步的oracle实验,我们发现如果把这部分损失区域用GT的像素label填充,分割性能可以在COCO上从35.5提升到51.0。这说明信息损失区域对最终分割的性能非常关键。

【四叉树的构造】
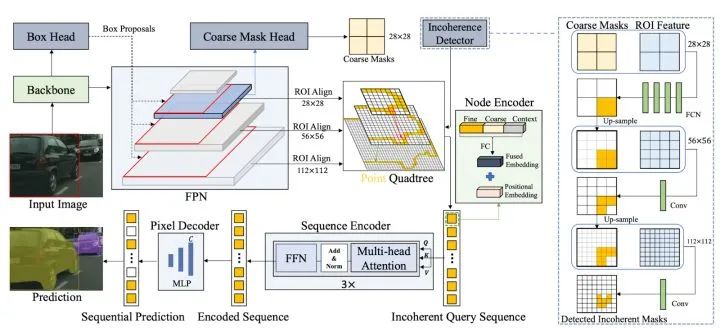
Transfiner构造了一个由不同层级信息损失节点构成的四叉树。这些节点都来自于RoI金字塔,但因为层级区别而特征粒度不同。四叉树的结构如图5的 Point Quadtree部分所示,来自低层级的RoI特征(如分辨率28×28)的信息损失节点在其相邻的更高层的RoI中(如分辨率56×56)中有四个对应子节点。为了减少计算量,我们只将预测为损失节点的像素点向上层进一步分解,并把树的最大深度设为3。更为具体地,我们把从最低层级(28x28)检测到的信息损失点作为根节点,从上到下递归扩展四个子象限点,构建了一个多层次的四叉树。在更高层的特征图上选取子象限点,是因为大尺度特征具有更高的分辨率和更多的物体局部细节。
【信息损失区域的检测】
信息损失区域的检测遵循由低到高的级联设计(cascaded design)。如图5右侧,为了检测RoI金字塔上的不同层级上信息损失节点,Transfiner先将最低层的RoI特征(28x28)和初始的物体mask预测作为输入,采用一个简单的全卷积网络(四个3×3 卷积)预测四叉树的根节点。每个根结点会分解到临近更高RoI层对应的4个子节点,例如从RoI大小28x28延伸到56x56。对于高层的RoI特征,Transfiner对上一层损失区域检测的mask做上采样后与RoI特征拼接,并使用单个1×1卷积层预测更精细的信息损失节点,以保持检测模块的轻量化。
【特征提取】
如图5,Backbone网络和FPN首先对输入图片提取多层次深度特征(从 P2到P5),并在此基础上构造了一个RoI特征金字塔,以由粗到细的方式进行实例分割。具体地,Transfiner首先预测物体检测框并输出粗糙的mask,然后在FPN的三个层级提取特征来构建RoI金字塔,其中RoI大小依次递增为 {28, 56, 112}。我们仅选取四叉树的三个层级信息损失点作为无序序列输入,形状为 C × N,其中 N 是节点总数,C 是特征通道维度。值得注意的是,由于信息损失区域高度稀疏,N << HW。不同于已有算法,Transfiner不是根据物体大小只选取单层FPN 特征,而是将跨 RoI 金字塔上多层且稀疏分布的信息损失点作为输入,并预测每个点相应的分割标签。
【节点编码】
为了丰富每个信息损失节点的特征,Mask Transfiner 的节点编码器(Node Encoder)使用四种不同的信息线索对每个四叉树节点进行编码:1)从 FPN 金字塔的相应位置和层级提取的细粒度深度特征。2) 初始检测器的粗略掩码预测提供高层的语义信息。3) 相对位置编码,补充节点在RoI中的距离相关性。4)每个节点的周围临近点信息来补充局部细节。对于每个节点,我们使用从 3×3 邻域中提取的特征,再经全连接层压缩到原特征维度。直观地说,这有助于定位物体边缘,以及捕捉物体的局部形状。如图 4 所示,细粒度特征、粗略掩码估计和点的局部特征经拼接后与位置向量相加,得到编码后的节点。
【序列编码和像素解码】
四叉树节点经编码器编码后,为了建模点之间的关联,序列编码器(Sequence Encoder)中的多头注意力模块会对输入序列进行点之间的特征融合及更新。相较于MLP,Transformer可以执行序列上的全局跨尺度推理。序列编码器的每一层都由多头自注意力模块和全连接的前馈网络(FFN)组成。为了给输入序列补充足够的前景和背景信息,我们还将RoI金字塔中最低层大小为14x14的196个特征点输入。与标准Transformer解码器不同,Transfiner 的像素解码器(Pixel Decoder)是一个简单的两层 MLP,不具有多头注意力模块。它对树中每个节点的输出查询进行解码,以预测最终的实例标签。
实验与对比
【可视化结果比较】
在图6的第一行,我们提供了对Baseline方法Mask R-CNN的初始mask预测和Transfiner在不同四叉树深度下的定性对比。随着四叉树变深,我们发现Transfiner的mask预测也逐渐精细化,并能更准确地分割物体边缘细节,特别是鸟的足部区域。在图5的第二行,我们可视化了随机选取的4个节点(红色标识)在进行预测的注意力分布。从节点R1来看,注意力稀疏分布,并集中在其周边具有较高外观相似度的区域,在注意力视图可以看到明显的鸟背部区域的前后景区分。

此外,我们还提供了Transfiner与已有的实例分割SOTA方法在COCO,Cityscapes和BDD100k上的可视化结果比较。Transfiner预测结果比已有的方法具有更高的精度和质量。以图 7 中的第三行为例,SOLQ 和Mask R-CNN 仅在高频区域(长颈鹿的头部和脚部区域)提供了非常粗略的mask预测(分辨率大小28×28)。虽然PointRend 采用了224×224的大输出尺寸,但依然无法正确分割出长颈鹿左腿间的缝隙。



【定量对比】
此外,在下表中我们还提供了Mask Transfiner在三个大型的实例分割数据集上的定量结果比较,Mask Transfiner的性能优于已有的二阶段(two-stage)和基于Instance Query的实例分割模型。例如在 COCO 上,Transfiner 在不同的backbone和检测器类型下均有明显的性能提升,使用 R101-FPN 和 Faster R-CNN 的性能超过 RefineMask 和 BCNet 1.8 Boundary AP 和 2.5 Boundary AP,在使用R50-FPN和Query-Based检测器超过QueryInst算法 3.1 Boundary AP。
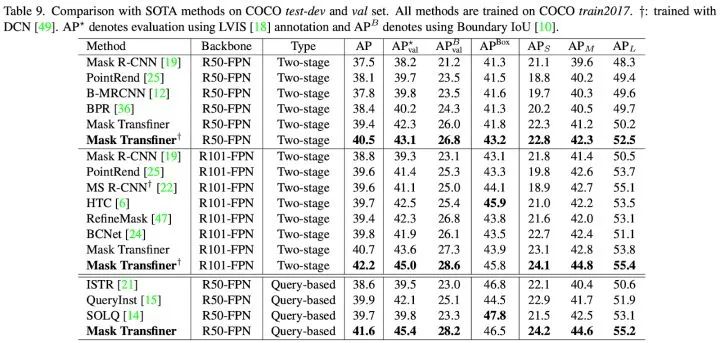
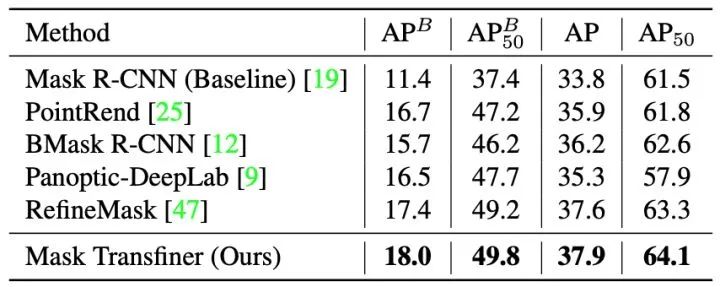

更多Mask Transfiner的实现和实验细节可参考我们的论文和开源代码,图5到图7可视化及表格部分包含的对比算法来源如下:
[1] Ke, Lei, Martin Danelljan, Xia Li, Yu-Wing Tai, Chi-Keung Tang, and Fisher Yu. "Mask Transfiner for High-Quality Instance Segmentation." In CVPR, 2022.
[2] He, Kaiming, Georgia Gkioxari, Piotr Dollár, and Ross Girshick. "Mask r-cnn." In ICCV. 2017.
[3] Kirillov, Alexander, Yuxin Wu, Kaiming He, and Ross Girshick. "Pointrend: Image segmentation as rendering." In CVPR. 2020.
[4] Dong, Bin, Fangao Zeng, Tiancai Wang, Xiangyu Zhang, and Yichen Wei. "Solq: Segmenting objects by learning queries." In NeurIPS, 2021.
[5] Cheng, Tianheng, Xinggang Wang, Lichao Huang, and Wenyu Liu. "Boundary-preserving mask r-cnn." In ECCV, 2020.
[6] Ke, Lei, Yu-Wing Tai, and Chi-Keung Tang. "Deep occlusion-aware instance segmentation with overlapping bilayers." In CVPR, 2021.
在文末总结一下Mask Transfiner算法的核心贡献:1. 我们首次提出了信息损失区域(Incoherent regions) 的概念及相应检测机制,避免了整图上的大计算量。2. 在这一区域的基础上,我们构造了一个四叉树结构的transfomer,将不同尺度空间下离散分布的特征点转为输入同一序列,并使用transformer对序列进行全局推理和预测,取得了大幅度的性能提升。如果大家觉得文章内容有帮助,欢迎大家转发,关注我们的工作,star开源的代码!也欢迎一起讨论!同时也希望能对其他计算机视觉中的其他需要高分辨率稠密预测的任务,如语义分割, depth/pose estimation和optical flow等等有启发。
公众号后台回复“CVPR2022”获取论文分类合集下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~




