CVPR 2022|看看谷歌如何在目标检测任务使用预训练权值

极市导读
论文对下游任务中的预训练权值使用方式进行了深入研究,发现长时间的fine-tuned会使得网络远离优秀初始化特征表达,这也解释为什么预训练初始化与从零训练的性能差异会随着训练时间的延长而消失。从论文的实验结果来看,搭配容量足够的检测组件,冻结预训练权值更有利于目标检测和实例分割的训练,还能显著减少计算资源消耗 >>加入极市CV技术交流群,走在计算机视觉的最前沿

论文地址:https://arxiv.org/abs/2204.00484
Introduction
迁移学习是深度学习中广泛采用的技巧,利用包含大型数据集的上游任务进行模型预训练,再将预训练模型应用到目标任务中。从ImageNet等大数据集上进行迁移学习能够有效地提升各种视觉任务、网络结构和训练方法的性能,这个做法经过了反复的证明和实践。
对于目标检测,通常先使用分类任务预训练得到的权值初始化主干网络,在训练其他探测器组件的同时对主干网络进行微调。最近,对目标检测的迁移学习有两个看似矛盾的观点:
-
大分类数据集预训练对目标检测是有益的。 -
预训练初始化与从零训练的性能差异随着训练时间的延长而消失。
论文以最简单的形式重新对转移学习进行研究,在检测器训练期间冻结主干网络权值。这样能够更好地分析预训练特征的有用性,不会因微调而产生混淆因素。使用这种方法,论文得出了以下两个观察结果:
-
在研究预训练特征的有用性时,较长时间的训练会产生歧义,因为微调后的主干权值会远离预训练权值。 -
最关键的一点,在上游分类任务中学习到的预特征比在检测数据集上微调或从头开始训练学习到的特征更适用于目标检测。
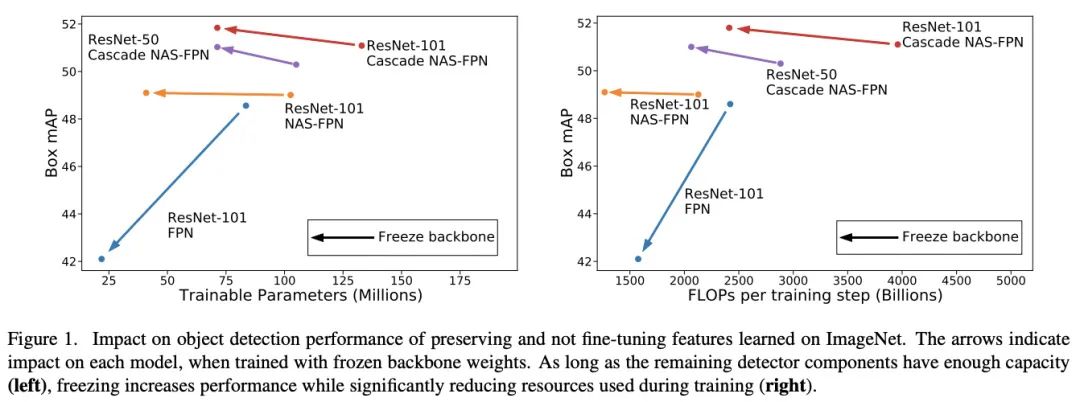
跟微调和从零训练对比,冻结预训练主干网络也能带来同样幅度、甚至更大幅度的提升,这表明后续的目标检测组件具有足够的特征表达能力。为此,论文认为可以在训练目前的检测模型时冻结预训练主干网络,不仅能得到类似或更高的性能,还能显著减少对计算资源的需求,如图1所示。如果按不同标注数量的类别进行性能分析时,冻结预训练主干网络带来的性能优势会更加明显,特别是对于标注数量较少的类。
Methodology
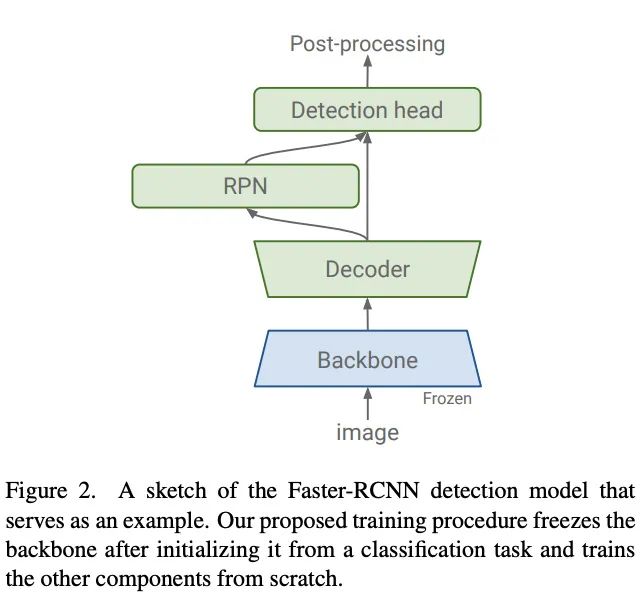
由于分类数据集(ImageNet (1.2 M) 和 JFT300M (300 M))比 MSCOCO (118K) 和 LVIS (100 K) 等常见检测数据集包含的图片数量要多几个数量级,所以论文认为在大规模图像分类任务上学习的特征比在相对较小的检测数据集中学习的特征更适合目标检测任务。
为此,论文提出冻结从分类任务中学习的权值,并且选择有足够的能力来学习detection-specific特征的目标检测组件。
Preserving classification features
为了保留从分类数据集中学习到的特征表达能力,论文采用最直接的冻结主干网络的权值的做法。相对于在预训练初始化后继续训练所有权值的常见做法,冻结主干权值不仅节省了计算,加快了训练速度,而且还提高了许多现有检测网络的性能。
Detection-specific capacity
为了将分类网络用于检测任务,通常需要添加检测相关的组件,如RPN、FPN以及Cascade RCNN等。论文发现检测组件的容量对网络的泛化能力起着重要作用,特别是使用预训练主干网络的情况下。当检测的组件具有足够的容量时,冻结权值比微调或从头开始训练表现得更好。此外,使用更多样化的分类数据集进行预训练时,性能收益会更加明显。
Data augmentation
在数据增强方面,所有实验都采用了LSJ(Large scale Jittering),而最佳的EfficientNet结果则增加了Copy-and-paste增强。从冻结权值的实验结果来看,冻结权值能够很好地与两种数据增强策略配合,在只帮助检测特定组件进行训练的情况下改善整体网络性能。
Experiments
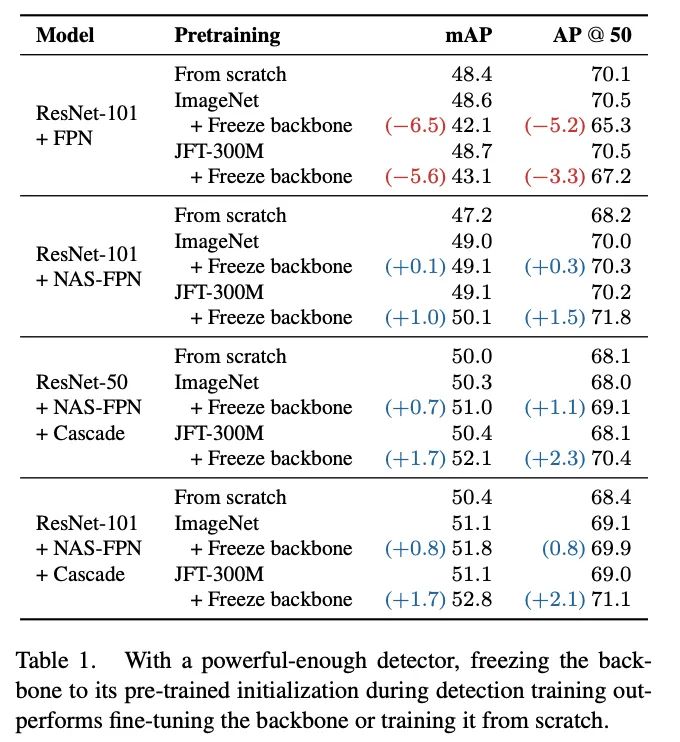
不同容量的检测的不同主干网络权值处理方法对比。
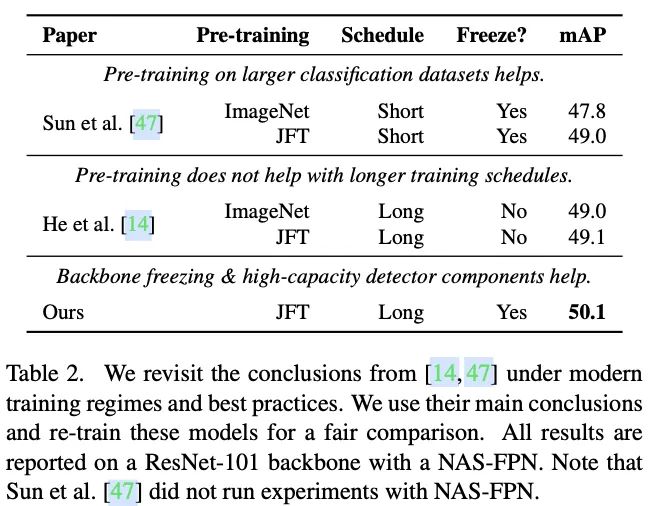
对比前面两个矛盾的观点以及论文的观点。
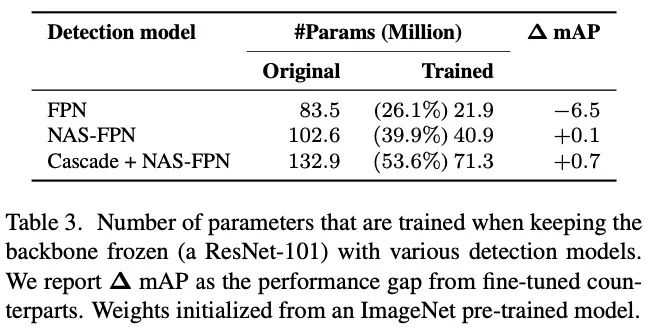
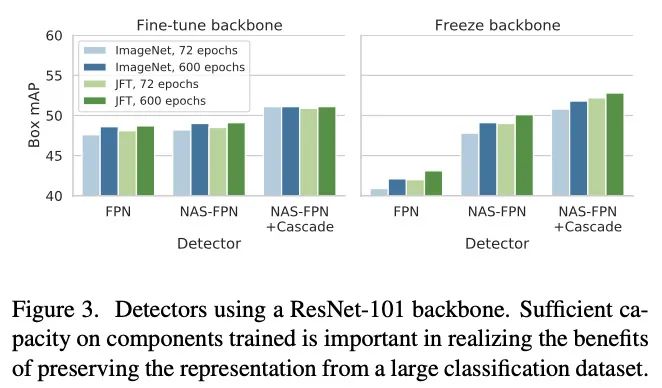
冻结主干网络与检测组件容量的关系。
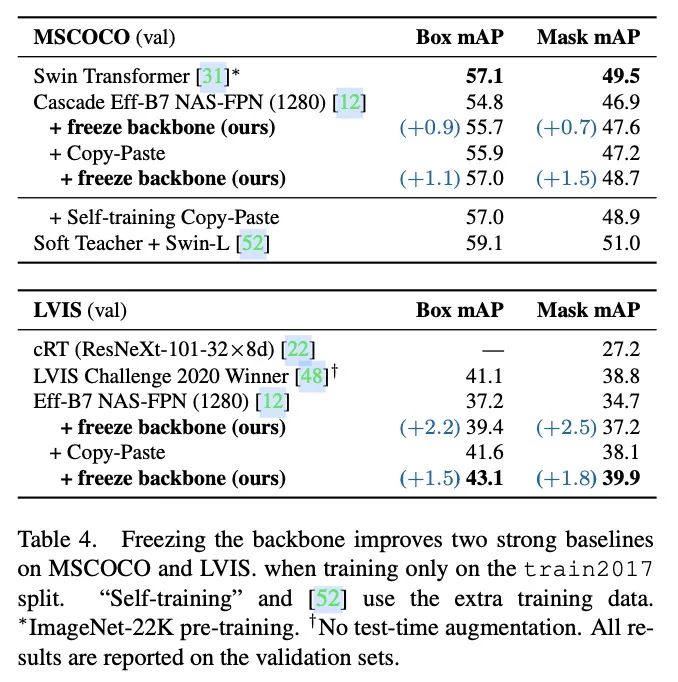
基于EfficientNet-B7+NAS-FPN构造最佳性能。
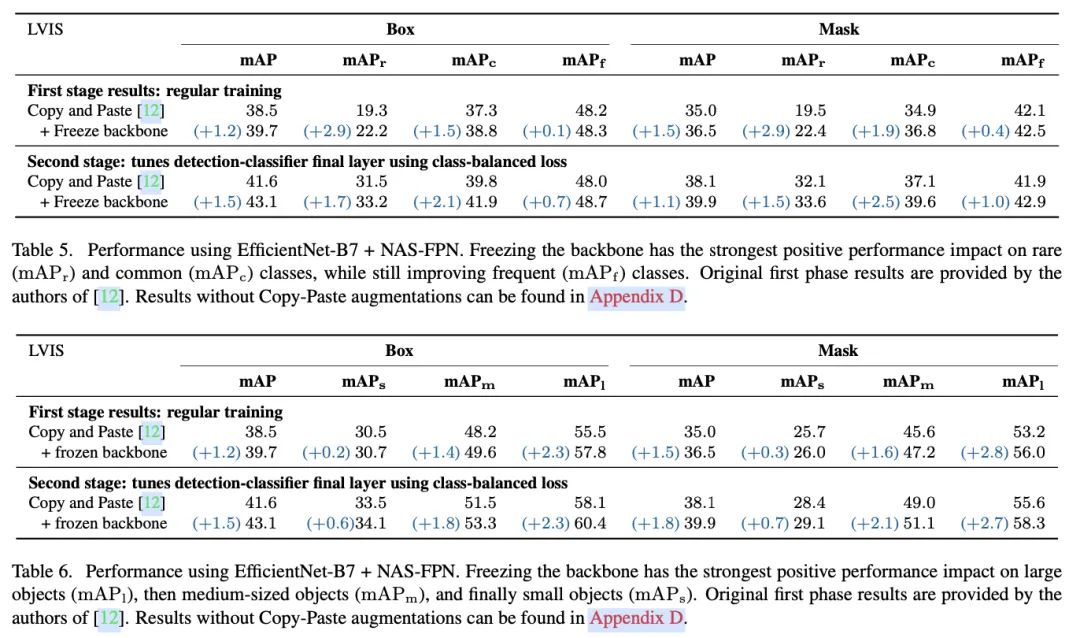
按目标大小查看基于EfficientNet-B7+NAS-FPN的性能提升。
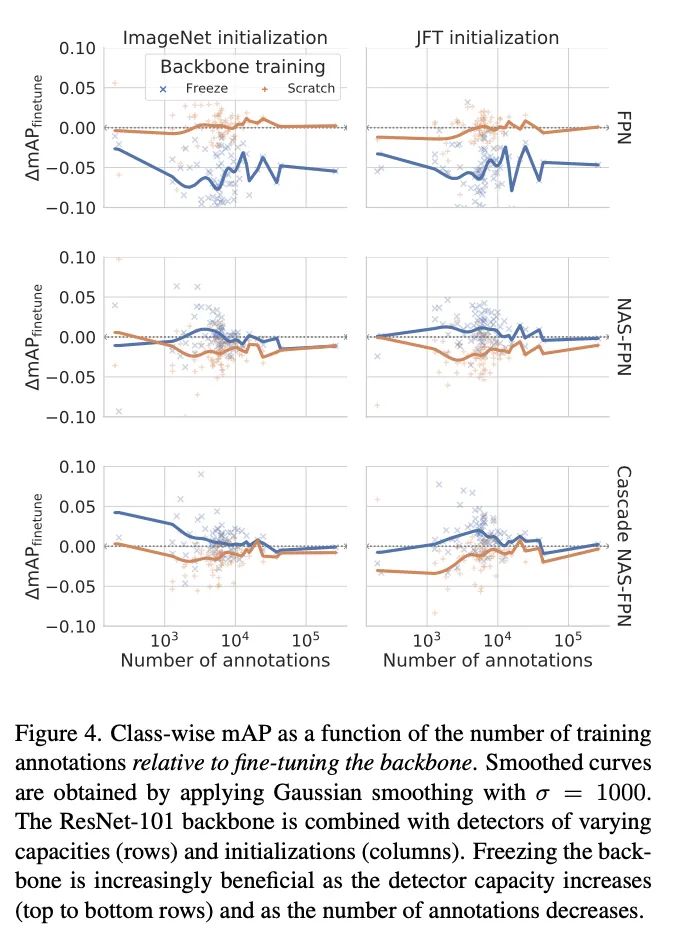
可视化对比冻结主干网络搭配不同检测组件和训练集为不同标注数的类别带来的性能收益,中间的线为所有点的高斯平滑结果。
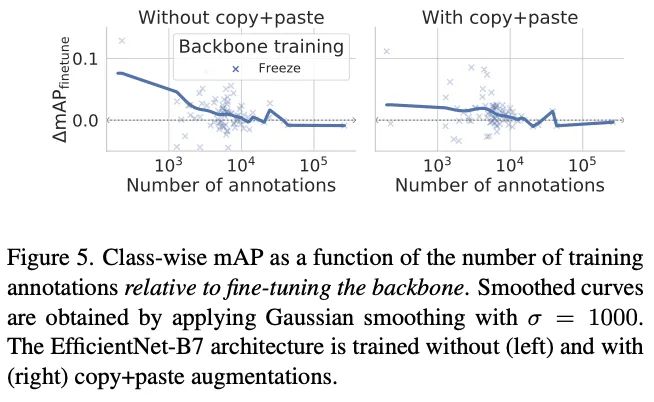
可视化对比冻结主干网络搭配Copy-and-paste为不同标注数的类别带来的性能收益,中间的线为所有点的高斯平滑结果。
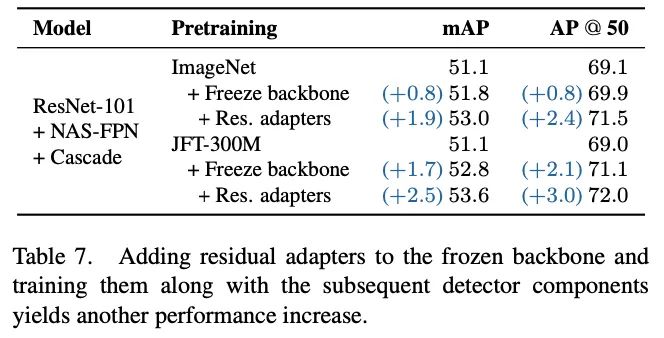
在冻结主干网络的基础上,搭配residual adapter进行域迁移能够进一步提升性能。
Conclusion
论文对下游任务中的预训练权值使用方式进行了深入研究,发现长时间的fine-tuned会使得网络远离优秀初始化特征表达,这也解释为什么预训练初始化与从零训练的性能差异会随着训练时间的延长而消失。从论文的实验结果来看,搭配容量足够的检测组件,冻结预训练权值更有利于目标检测和实例分割的训练,还能显著减少计算资源消耗。
公众号后台回复“数据集”获取90+深度学习数据集下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~




