用最简陋的LSTM,超越各种Transformer:大神新作,单头注意力RNN引热议
栗子 发自 凹非寺
量子位 报道 | 公众号 QbitAI
如今,语言模型的世界,几乎被Transformer/BERT占领了。
但如果回到2017年,把轰动世界的论文Attention Is All You Need从时间线上抹掉呢?
多头注意力不存在了,只剩下原始的LSTM,自然语言处理又会朝怎样的方向进化?

机器学习大佬Stephen Merity (Smerity) 突发奇想,强行回到过去,依靠简单质朴的LSTM,做出了单头注意力RNN,简称SHA-RNN。
这个古法炮制的新模型,只用单个GPU训练不到24小时,就在语言建模数据集enwik8上获得了接近SOTA的成绩。
除了算力要求不高,它还支持最多5000个token的长距离依赖。
论文引发了大量围观和讨论,推特已有1700赞,Reddit热度达到了170。
谷歌大脑的研究员David Ha说:
警告:这不是一篇论文,是大师级的艺术作品。
楼下立刻有人 (@Ktsaprailis) 附议:
真的,好像在读深度学习版的《银河系漫游指南》。
还有小伙伴 (@lorenlugosch) 说:
这么好玩的论文,再多来点就好了。
那么,到底是一次怎样的穿越,让大家陶醉得无法自拔?
要那么多头做什么?
就像蝴蝶效应,大佬Smerity说他要证明的是:只要方法稍有改变,整个领域会朝完全不同的方向发展。
他开发的新模型,是由几个部分组成的:一个可训练的嵌入层,一层或者多层堆叠的单头注意力RNN (SHA-RNN) ,再加一个softmax分类器。
其中,SHA-RNN的结构就是下图这样:
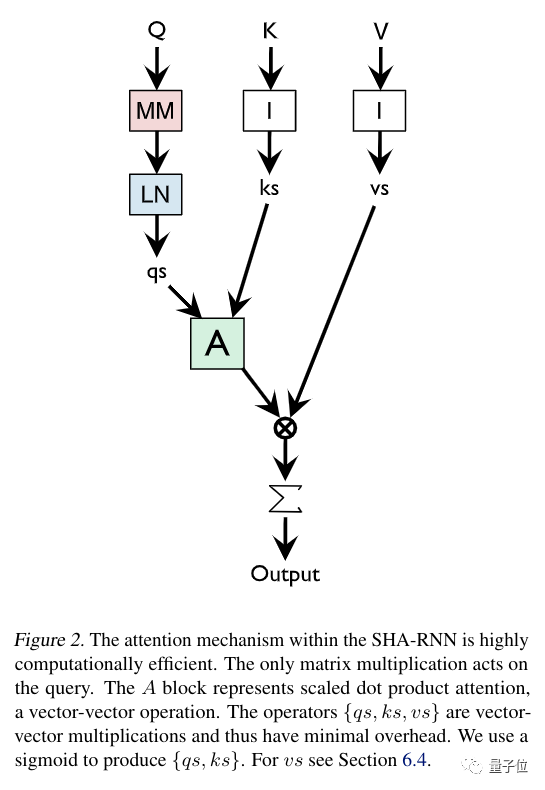
△ LN=Layer Normalization
大致说来,SHA-RNN用的是单头的、基于指针的注意力 (Pointer Based Attention) ,借鉴了2017年作者本人领衔的研究;还包含一个改造过的前馈层,名叫“Boom”,带有层归一化。
那么,分别来观察一下,注意力和前馈层。
首先是注意力。Smerity老师说,许多受Transformer启发的模型架构,都假设在构造上没有顺序 (Sequentiality) ,且每层都有几十个头,计算起来太复杂了,大家也并不知道有多少头是有效的。
相比之下,SHA-RNN模型的注意力是简化的,只留一个头,唯一的矩阵乘法出现在query (下图Q) 那里,A是缩放点乘注意力 (Scaled Dot-Product Attention) ,是向量之间的运算。
△ MM=Matrix Manipulation,LN=Layer Normalization
这样一来,计算起来效率很高,普通台式机也可以训练。
接下来讲前馈层 (“Boom” Layer) 。虽然这是从Transformer借鉴来的,不过Smerity老师重新排布了一下:
用了一个v∈ℝH向量,又用矩阵乘法 (GeLU激活) 得到另一个向量u∈ℝN×H。
然后,把u向量分解成N个向量,再求和,得到w∈ℝH向量。
这样一来,与传统的下映射层 (Down-Projection Layers) 相比,减少了运算量,除掉了一整个矩阵的参数。
那么,SHA-RNN成绩怎么样呢?
拉出来遛遛
Smerity老师说,虽然能用家里的台式机训练,但跑着跑着没了耐心,于是改用GPU (12GB Titan V) 训练了不到一天。
然后,就在两个数据集enwik8和WikiText-103试一试吧。
其中,enwik8数据集包含了上亿字节维基百科XML转储。这是比赛结果:
当然,直接和纯LSTM比是没意义的,直接和无头SHA-RNN比也没意义。
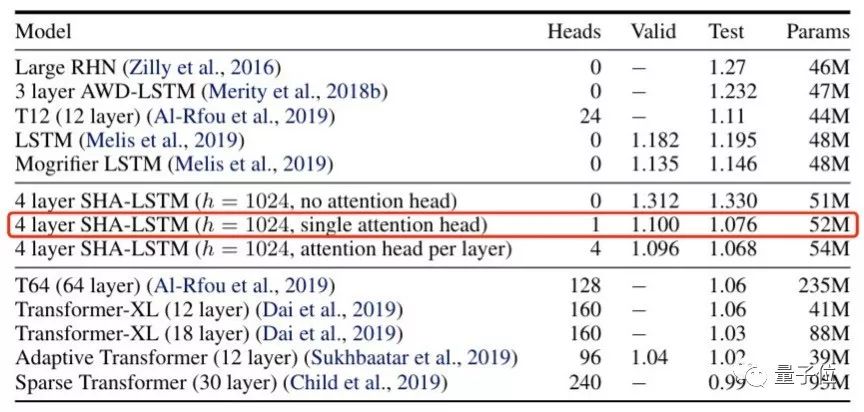
测试机上的表现,超越了各种Transformer。
另一场比赛,在WikiText-103数据集上进行,测试的是Tokenization (分词) 。结果认为,SHA-RNN可以有效抵御Tokenization攻击。
成功了。
开源了

Smerity老师的穿越算法,已经放出了代码。
大家一边欣赏论文,也可以自己去跑一下试试。
论文传送门:
https://arxiv.org/pdf/1911.11423.pdf
代码传送门:
https://github.com/smerity/sha-rnn
作者系网易新闻·网易号“各有态度”签约作者
— 完 —
大咖齐聚!参会嘉宾重磅揭晓
量子位 MEET 2020 智能未来大会启幕,李开复、倪光南、景鲲、周伯文、吴明辉、曹旭东、叶杰平、唐文斌、王砚峰、黄刚、马原等AI大咖与你一起读懂人工智能。观众票即将售罄,扫码报名预定席位 ~


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「在看」吧 !




