关于序列建模,是时候抛弃RNN和LSTM了

在 2014 年,RNN 和 LSTM 起死回生。我们都读过 Colah 的博客《Understanding LSTM Networks》和 Karpathy 的对 RNN 的颂歌《The Unreasonable Effectiveness of Recurrent Neural Networks》。但当时我们都「too young too simple」。现在,序列变换(seq2seq)才是求解序列学习的真正答案,序列变换还在语音到文本理解的任务中取得了优越的成果,并提升了 Siri、Cortana、谷歌语音助理和 Alexa 的性能。此外还有机器翻译,现在机器翻译已经能将文本翻译为多种语言。在图像到文本、文本到图像的变换以及视频文字说明的应用中,序列变换也是卓有成效。
在 2015-2016 年间,出现了 ResNet 和 Attention 模型。从而我们知道,LSTM 不过是一项巧妙的「搭桥术」。并且注意力模型表明 MLP 网络可以被「通过上下文向量对网络影响求平均」替换。下文中会继续讨论这一点。
经过两年多的时间,我们终于可以说:「放弃你的 RNN 和 LSTM 路线吧!」
我们能看到基于注意力的模型已越来越多地被用于谷歌、Facebook 和 Salesforce 的 AI 研究。它们都经历了将 RNN 模型和其变体用基于注意力的模型替换的过程,而这才刚刚开始。RNN 模型曾经是很多应用的构建基础,但相比基于注意力的模型,它们需要更多的资源来训练和运行。(参见:https://towardsdatascience.com/memory-attention-sequences-37456d271992)
读者可查阅机器之心的GitHub项目,理解RNN与CNN在序列建模上的概念与实现。
为什么?
RNN、LSTM 和其变体主要对时序数据进行序列处理。如下图中的水平箭头部分:
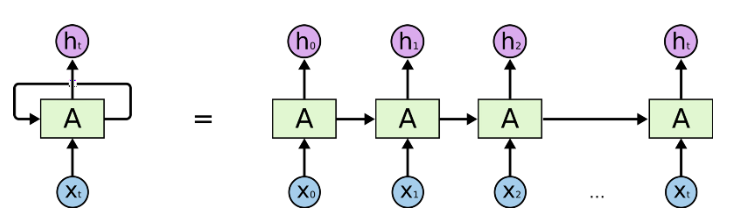
RNN 中的序列处理过程,来自《Understanding LSTM Networks》
这些箭头表明,在长期信息访问当前处理单元之前,需要按顺序地通过所有之前的单元。这意味着它很容易遭遇梯度消失问题。
为此,人们开发了 LSTM 模型,LSTM 可以视为多个转换门的合并。ResNet 也借鉴于这种结构,它可以绕过某些单元从而记忆更长时间步的信息。因此,LSTM 在某种程度上可以克服梯度消失问题。
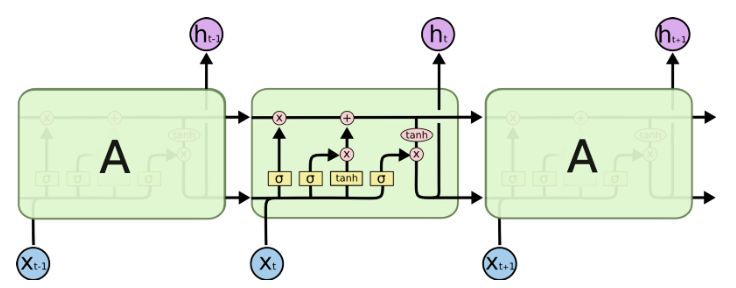
LSTM 中的序列处理过程,来自《Understanding LSTM Networks》
但这并不能完全解决该问题,如上图所示。LSTM 中仍然存在按顺序地从过去单元到当前单元的序列路径。实际上,现在这些路径甚至变得更加复杂,因为路径上还连接了加如记忆的分支和遗忘记忆的分支。毫无疑问,LSTM、GRU 和其变体能学习大量的长期信息
(参见《The Unreasonable Effectiveness of Recurrent Neural Networks》),
但它们最多只能记住约 100s 的长期信息,而不是 1000s 或 10000s 等。
并且,RNN 的一大问题是它们非常消耗计算资源。即如果需要快速训练 RNN,需要大量的硬件资源。在云端上运行这些模型的成本也很高,随着语音到文本的应用需求快速增长,云计算资源目前甚至赶不上它的需求。
解决方案是什么?
如果序列处理无可避免,那么我们最好能找到可向前预测和向后回顾的计算单元,因为我们处理的大多数实时因果数据只知道过去的状态并期望影响未来的决策。这和在翻译语句或分析录制视频时并不一样,因为我们会利用所有数据并在输入上推理多次。这种向前预测和后向回顾的单元就是神经注意力模块,下面将简要介绍这一点。
为了结合多个神经注意力模块,我们可以使用下图所示的层级神经注意力编码器:
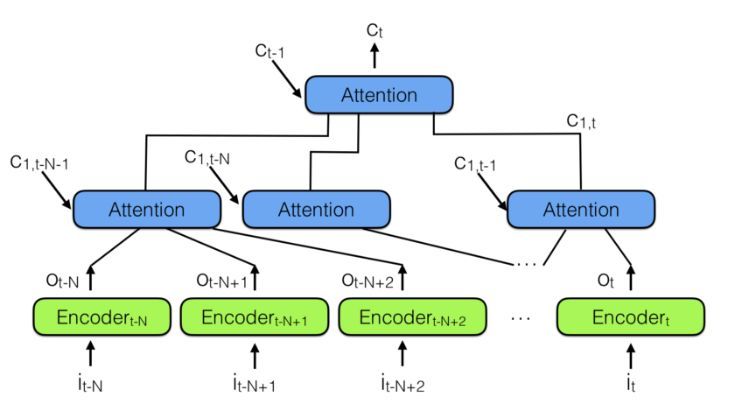
层级神经注意力编码器
观察过去信息的更好方式是使用注意力模块将过去编码向量汇总到上下文向量 C_t。请注意上面有一个层级注意力模块,它和层级神经网络非常相似。
在层级神经注意力编码器中,多层注意力可查看过去信息的一小部分,例如 100 个向量,而上面层级的注意力模块能查看到 100 个下层的注意力模块,也就是 100×100 个向量。即利用层级模块可极大地扩展注意力机制观察的范围。
这就是一种能回顾更多的历史信息并预测未来的方法。
这种架构类似于神经图灵机,但令神经网络通过注意力决定从记忆中需要读取什么。这意味着一个实际的神经网络将决定过去的哪个向量对未来的决策更重要。
但记忆的储存呢?与神经图灵机不同,上面的架构将会把所有的历史表征储存在记忆中。这可能是不高效的,若储存视频中每一帧的表征,而大多数情况下表征向量并不会一帧帧地改变,所以这导致储存了太多的相同信息。我们确实可以添加另一个单元来防止储存相关数据,例如不储存与之前太相似的向量。但这只是一种技巧,更好的方法可能是让架构自己判断哪些向量需要储存,而哪些不需要。这一问题也是当前研究领域的重点,我们可以期待更多有意思的发现。
所以,最后总结来说:忘了 RNN 和它的变体吧,你仅需要的是注意力机制模块。
目前我们发现很多公司仍然使用 RNN/LSTM 作为自然语言处理和语音识别等架构,他们仍没有意识到这些网络是如此低效和不可扩展。例如在 RNN 的训练中,它们因为需要很大的内存带宽而很难训练,这对于硬件设计很不友好。本质上来说,递归是不可并行的,因此也限制了 GPU 等对并行计算的加速。
简单来说,每个 LSTM 单元需要四个仿射变换,且每一个时间步都需要运行一次,这样的仿射变换会要求非常多的内存带宽,因此实际上我们不能用很多计算单元的原因,就是因为系统没有足够的内存带宽来传输计算。这对于模型的训练,尤其是系统调参是非常大的限制,因此现在很多工业界应用都转向了 CNN 或注意力机制。
论文:Attention Is All You Need

论文链接:https://arxiv.org/abs/1706.03762
在编码器-解码器配置中,显性序列显性转导模型(dominant sequence transduction model)基于复杂的 RNN 或 CNN。表现最佳的模型也需通过注意力机制(attention mechanism)连接编码器和解码器。我们提出了一种新型的简单网络架构——Transformer,它完全基于注意力机制,彻底放弃了循环和卷积。两项机器翻译任务的实验表明,这些模型的翻译质量更优,同时更并行,所需训练时间也大大减少。我们的模型在 WMT 2014 英语转德语的翻译任务中取得了 BLEU 得分 28.4 的成绩,领先当前现有的最佳结果(包括集成模型)超过 2 个 BLEU 分值。在 WMT 2014 英语转法语翻译任务上,在 8 块 GPU 上训练了 3.5 天之后,我们的模型获得了新的单模型顶级 BLEU 得分 41.0,只是目前文献中最佳模型训练成本的一小部分。我们表明 Transformer 在其他任务上也泛化很好,把它成功应用到了有大量训练数据和有限训练数据的英语组别分析上。

媒体合作请联系:
邮箱:contact@dataunion.org



