150亿参数大杀器!Facebook开源机器翻译新模型,同传人员或失业

新智元报道
新智元报道
来源:Facebook
编辑:QJP
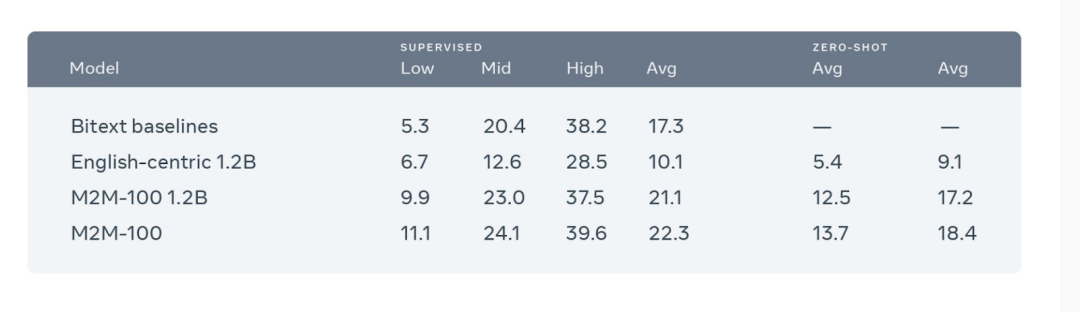
【新智元导读】Facebook 今日开源了一个多语种机器翻译模型「M2M-100」,这是首个不依赖英语数据就能翻译100种语言的模型,比如直接从僧伽罗语翻译成爪哇语。这种单一多语言模型与传统的双语模型性能相当,同时比以英语为中心的多语模型BLEU提高了10个点。
当把中文翻译成法文时,以前最好的多语种模型的方式是把中文翻译成英文,把英文翻译成法文,因为英语的训练数据是最多的。
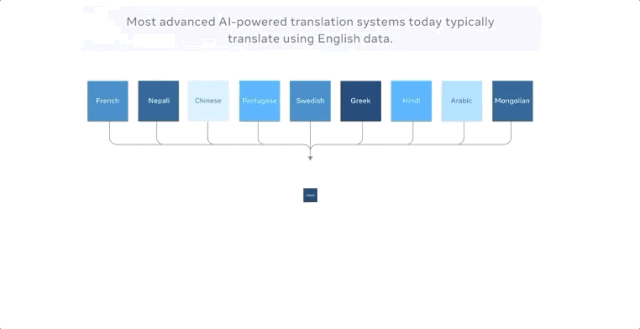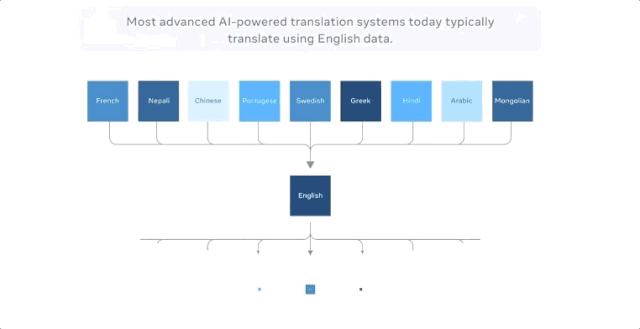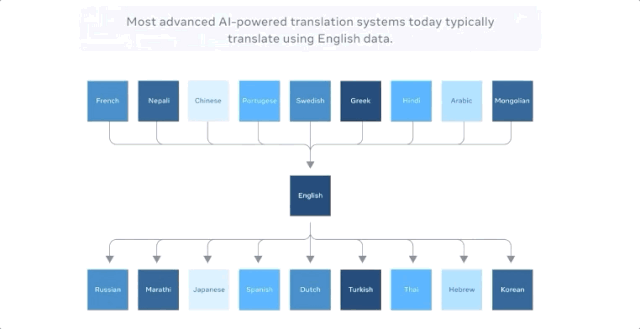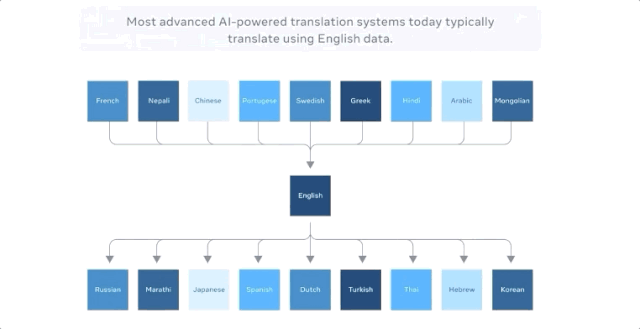
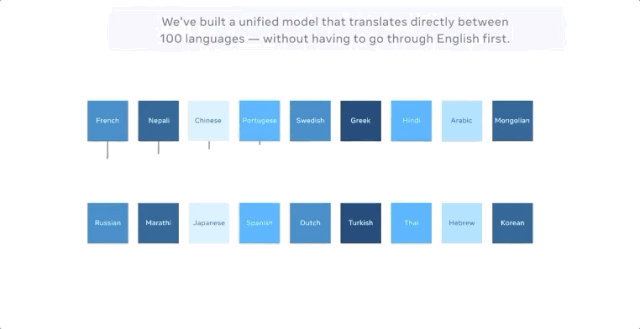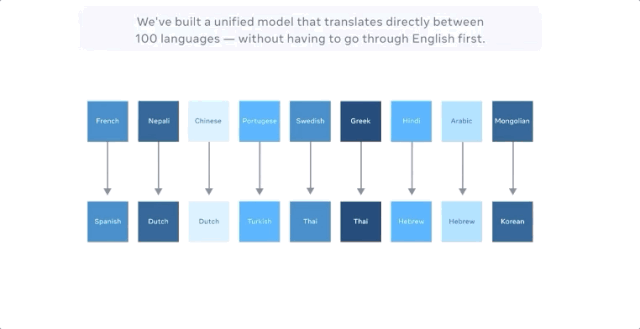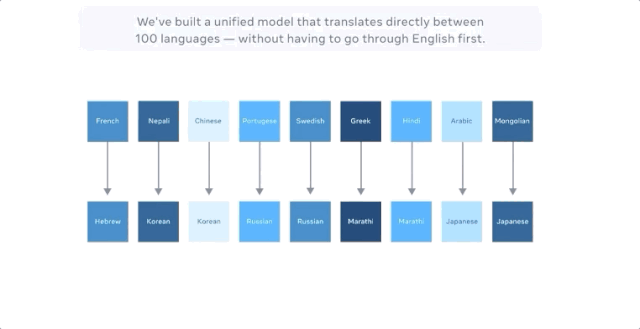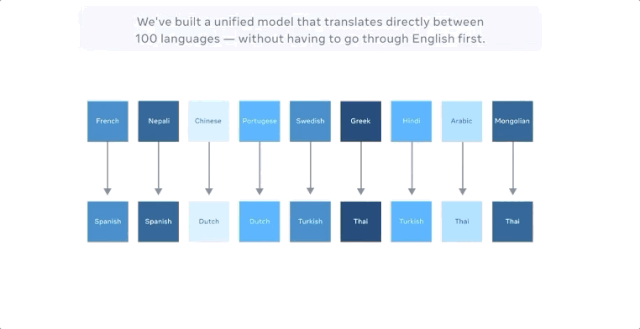 M2M-100共接受了2200种「语言对」的训练,比以往以英语为中心的最优的多语言模型多了10倍。
部署 M2M-100将提高数十亿人的翻译质量,尤其是对那些语言资源匮乏的人。
M2M-100共接受了2200种「语言对」的训练,比以往以英语为中心的最优的多语言模型多了10倍。
部署 M2M-100将提高数十亿人的翻译质量,尤其是对那些语言资源匮乏的人。
 典型的机器翻译系统需要为每种语言和每个任务建立单独的AI模型,但是这种方法在 Facebook 上并不能有效地扩展。
典型的机器翻译系统需要为每种语言和每个任务建立单独的AI模型,但是这种方法在 Facebook 上并不能有效地扩展。

挖掘数以亿计的句子,寻找数以千计的语言方向
挖掘数以亿计的句子,寻找数以千计的语言方向
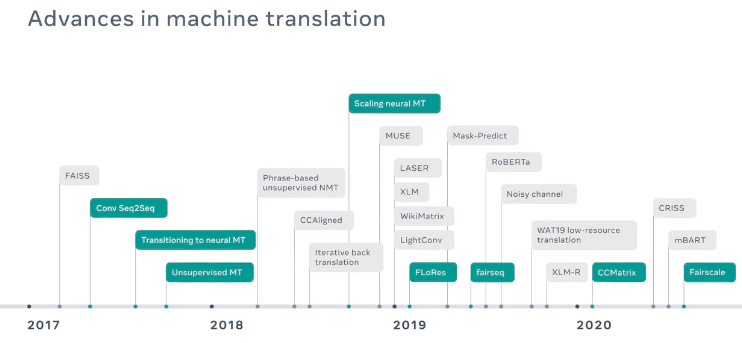
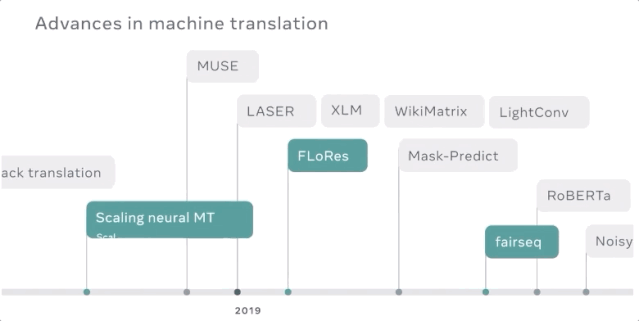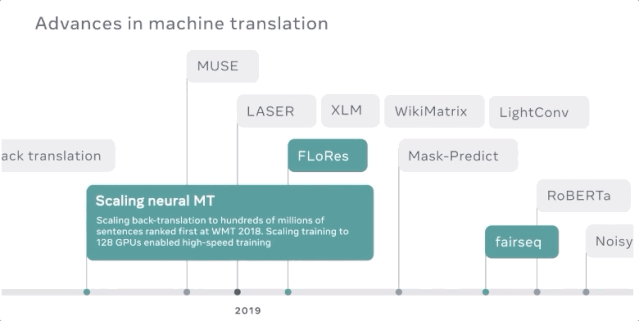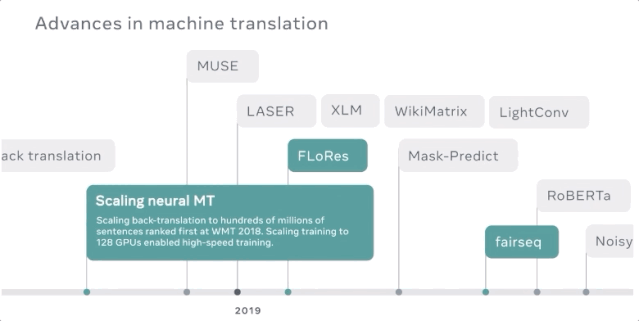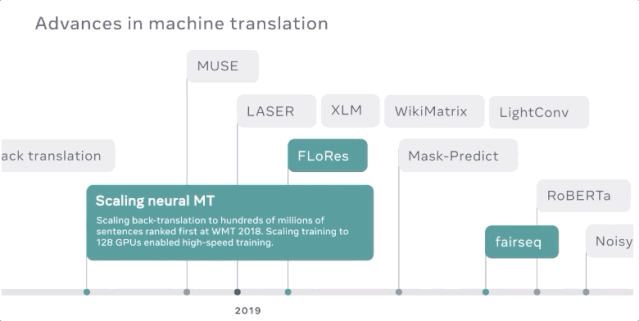
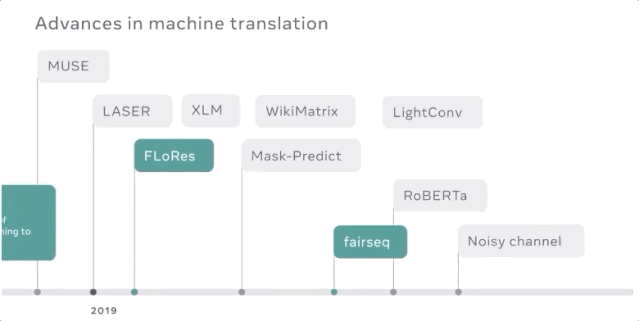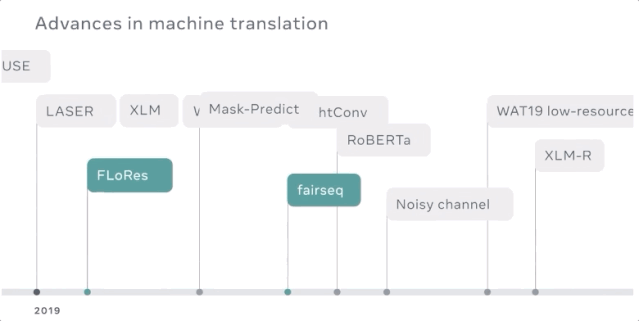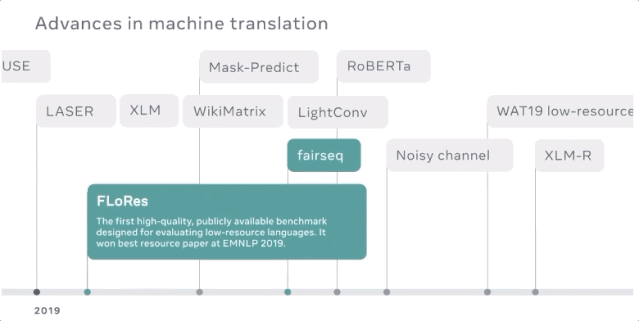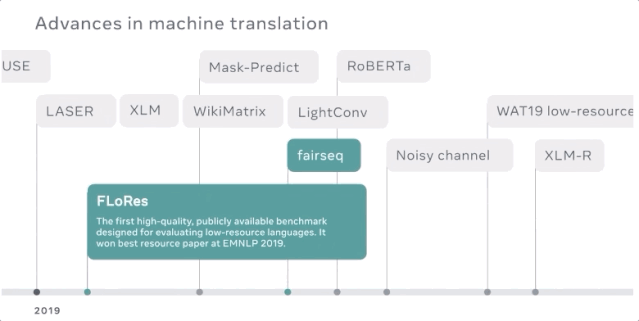
以高速度和高质量将机器翻译模型扩展到150亿参数
以高速度和高质量将机器翻译模型扩展到150亿参数


登录查看更多
相关内容

Arxiv
0+阅读 · 2021年1月22日
Arxiv
5+阅读 · 2018年4月16日




相关VIP内容
相关资讯