谷歌开源语义图像分割模型DeepLab-v3+ | 附代码
安妮 编译自 谷歌官方博客
量子位 出品 | 公众号 QbitAI
今天,谷歌宣布开源语义图像分割模型DeepLab-v3+。
据谷歌在博客上的描述,DeepLab-v3+模型是目前DeepLab中最新的、执行效果最好的语义图像分割模型,可用于服务器端的部署。
此外,研究人员还公布了训练和评估代码,以及在Pascal VOC 2012和Cityscapes基准上预训练的语义分割任务模型。

DeepLab已三岁
虽然有“Lab”这个单词,但DeepLab真的不是谷歌的某个实验室啊喂~
这是三年前谷歌提出的一个语义分割模型,它改进了卷积神经网络(CNN)的特征提取器,能更好地对物体建模,对上下文信息的理解也较为准确。经过多次训练后,改进版的DeepLab-v2和DeepLab-v3相继诞生。
而DeepLab-v3+模型就是DeepLab模型最新的改进方案。
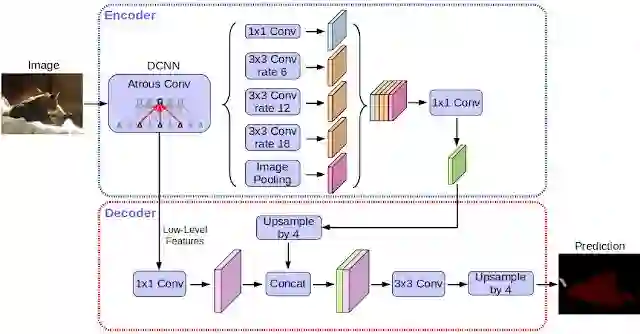
研究人员通过添加一个简单的解码器模型扩展DeepLab-v3,用于细化分割结果,在物体边界的划分上甚是有用。
之后,他们还进一步将深度可分离的卷积应用到spatial pyramid pooling和解码器模型中,构建出更厉害的编码-解码器网络进行语义分割模型。
相关资源
想了解DeepLab-v3+的更多技术细节,可移步官方博客:
https://research.googleblog.com/2018/03/semantic-image-segmentation-with.html
或前往代码地址一探究竟:
https://github.com/tensorflow/models/tree/master/research/deeplab
— 完 —
活动报名

加入社群
量子位AI社群13群开始招募啦,欢迎对AI感兴趣的同学,加小助手微信qbitbot4入群;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进群请加小助手微信号qbitbot5,并务必备注相应群的关键词~通过审核后我们将邀请进群。(专业群审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态



