【泡泡一分钟】通过排序序列进行无监督表示学习(ICCV2017-65)
泡泡一分钟,带你精读机器人顶级会议文章
标题:Unsupervised Representation Learning by Sorting Sequences
作者:Hsin-Ying Lee,Jia-Bin Huang,Maneesh Singh,Ming-Hsuan Yang,University of California, Merced,Virginia Tech,Verisk Analytics
来源:ICCV 2017
播音员:丸子
编译:王国芳(70)
审核:周平
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——通过排序序列进行无监督表示学习,该文章发表IEEE 2017。
我们提出了一个无监督的表示学习方法,这个方法使用没有语义标签的视频。我们通过将表示学习作为序列排序任务来利用时间相干性作为监督信号。我们将时间上混乱的帧(即,不按照时间顺序)作为输入并训练卷积神经网络来对混乱序列进行排序。类似于基于比较的排序算法,我们建议从所有帧对中提取特征并聚合它们以预测正确的顺序。由于对混乱图像序列进行排序需要了解图像的统计时间结构,因此使用这种代理任务进行训练可以让我们学习丰富且可概括的视觉表示。在高级别识别问题中,我们使用我们的方法作为预训练验证了该表示学习的有效性,实验结果表明,我们的方法在动作识别,图像分类和物体检测任务方面优于最先进的方法。
主要贡献
本文做出来如下贡献:
1、我们通过解决序列排序问题(把一个混乱序列变成一个有时间顺序列)提出了一种无监督的表示模型。
2、我们提出了一个序列预测网络架构用来方便训练。
算法流程
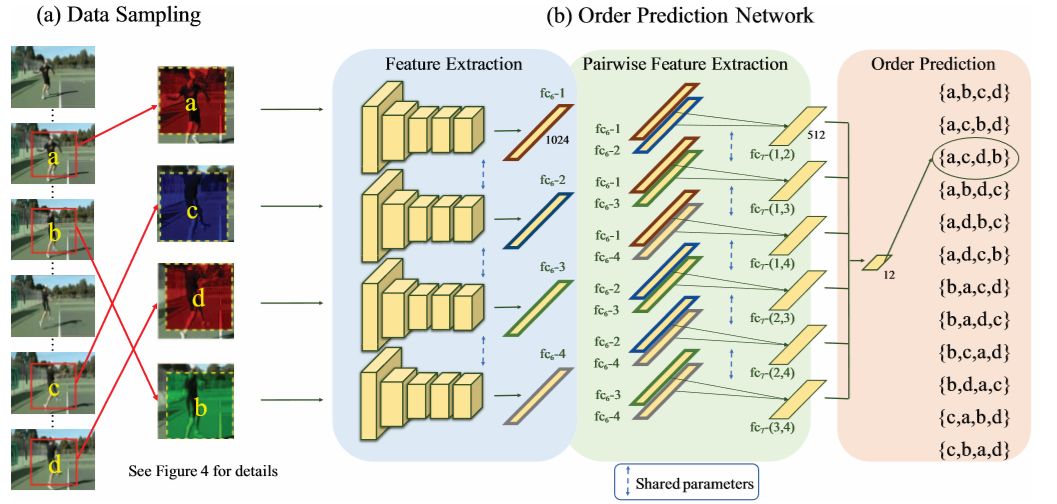
我们的训练方法主要包含两个步骤,(a)数据采样。我们根据运动幅度从输入视频中抽取候选元组。 然后,我们将空间抖动和通道拆分应用于选定的修补程序,以指导网络将注意力集中在图像的语义上,而不是固定在低级功能上。最后我们随机的混乱作为输入元组来训练CNN。(b)序列预测网络。我们提出的这个网络主要有以下三个部分组成:(1)特征提取,(2)成对特征提取,(3)序列预测。每帧的特征由卷积层编码。成对特征提取阶段然后从每一对帧中提取特征。然后我们有一个最终图层,它将这些提取的特征用于预测顺序。请注意,虽然我们为了演示而在三个单独的阶段中描述了架构,但网络培训是端到端的,没有阶段式优化。
主要结果
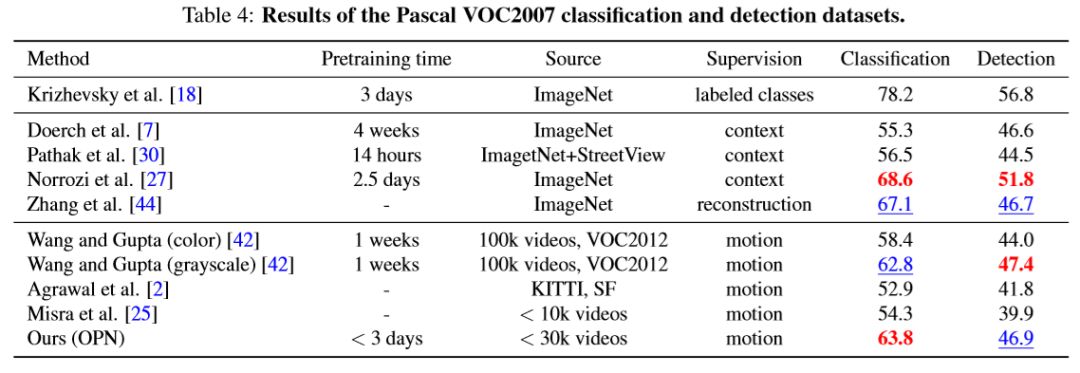
表4列出了使用静态图像的方法和使用视频的方法的总结。 虽然我们的表现很有竞争力,但使用ImageNet训练的方法比使用视频的方法更好。 我们将这种差距归因于这样的事实:训练图像是以对象为中心的,而我们的训练视频是以人为中心的(因此可能不包含通用对象的不同外观变化)。 在使用视频的方法中,我们的方法显示出竞争性。 但是,我们的方法需要相当少的培训时间和较少的培训视频。

不同采样策略的比较。 Motion使用光流的大小来选择色块。方向进一步限制了选定元组中光流方向的单调性。 结果表明,方向过度简化了问题,从而降低了性能。
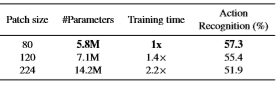
比较使用不同大小。 使用80×80在各方面都有优势。
空间抖动的影响。 对于三元组和四元组的情况,具有空间抖动的OPN表现更好。
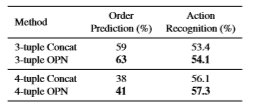
成对特征提取对顺序预测和动作识别的影响。 结果证明了两个任务之间的性能相关性,并表明OPN有助于特征学习。
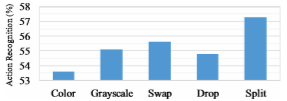
不同策略对色彩通道的影响。 建议的信道分裂优于其他策略。
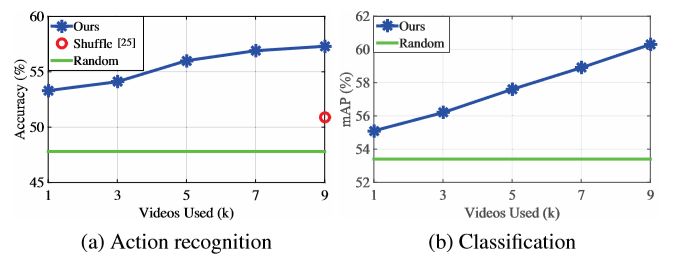
使用不同数量的视频进行性能比较。 结果显示,在使用更多视频进行培训时性能稳步提高。 我们还表明,无监督的预训练比随机初始化提供了显著的优势。

每行列出从VOC数据集激活特定单元的前5个。 虽然我们在UCF-101数据集上训练网络时未使用任何手动注释,但pool5特性激活对应于人头(第1行和第2行)和对象部分(第3行和第4行)。

Abstract
We present an unsupervised representation learning approach using videos without semantic labels. We leverage the temporal coherence as a supervisory signal by formulating representation learning as a sequence sorting task. We take temporally shuffled frames (i.e., in non-chronological order) as inputs and train a convolutional neural network to sort the shuffled sequences. Similartocomparison-based sorting algorithms, we propose to extract features from all frame pairs and aggregate them to predict the correct order. As sorting shuffled image sequence requires an understanding of the statistical temporal structure of images, training with such a proxy task allows us to learn rich and generalizable visual representation. We validate the effectiveness of the learned representation using our method as pre-trainingonhigh-levelrecognitionproblems. Theexperimental results show that our method compares favorably against state-of-the-art methods on action recognition, image classification, and object detection tasks.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com




