因果推断入门:为什么需要因果推断?

©作者 | Zihao
单位 | 香港中文大学(深圳)
研究方向 | 可信AI
本文是 Brady Neal 推出的因果推断课程 Introduction to Causal Inference 的中文笔记,主要是参考 Lecture Notes 加上一些自己的理解。

Lecture Note:
课程视频:

为什么需要因果推断
1.1 辛普森悖论
首先,考虑一个与现实情况很相关的例子:针对某种新冠病毒 COVID-27,假设有两种疗法:方案 A 和方案 B,B 比 A 更稀缺(耗费的医疗资源更多),因此目前接受方案 A 的患者与接受方案 B 的患者比例约为:73%/27%。想象一下你是一名专家,需要选择其中一种疗法,而这个国家只能选择这一种疗法,那么问题来了,如何选择才能尽量少的减少死亡?
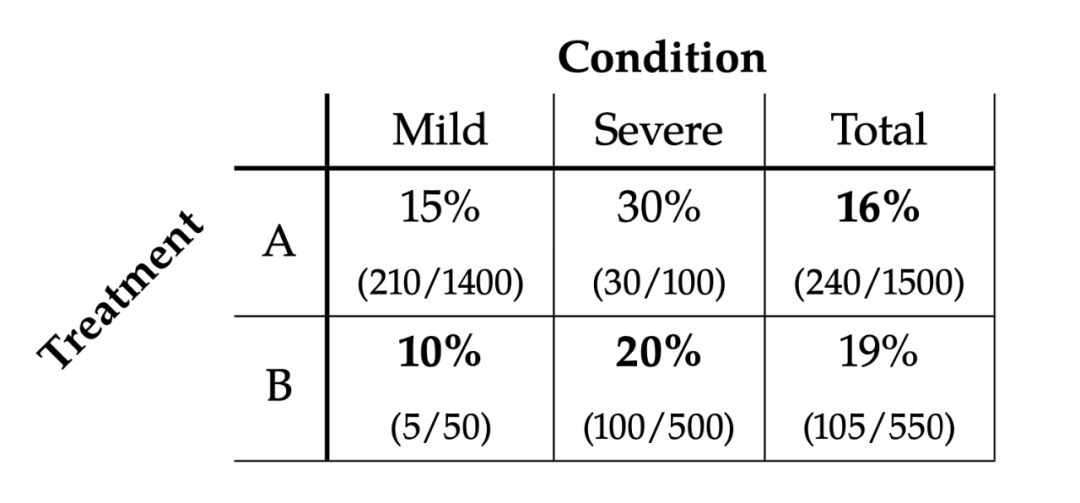
▲ 表1.1
假设你有关于死于 COVID-27 的人的百分比数据(表1)。他们所接受的治疗是与病情的严重程度相关的,mild 表示轻症,severe 表示重症。在表 1 中,可以看到接受方案的人中总共有 16% 的人死亡,而接受 B 的死亡率是 19%,我们可能会想更贵的治疗方案 B 比便宜的治疗方案 A 的死亡率要更高,这不是离谱吗。然而,当我们按照轻症、重症分别来看(Mild 列和 Severe 列),情况确是相反的。在这两种情况下,接受 B 的死亡率比 A 都要低。
此时神奇的悖论就出现了。如果从全局视角来看,我们更倾向于选择 A 方案,因为 16%<19%。但是,从 mild 和 severe 视角来看,我们都更倾向于方案 B,因为 10%<15%,20%<30%。此时你作为专家给出了一下结论:“如果能判断患者是轻症或者重症,就用方案 B,如果判断不了就用方案 A”,此时估计你已经被人民群众骂成砖家了。
导致出现辛普森悖论的关键因素是各个类别的非均匀性。接受 A 治疗的 1500 人中有 1400 人病情轻微,而接受 B 治疗的 550 人中有 500 人病情严重。因为病情轻的人死亡的可能性较小,这意味着接受治疗 A 的人的总死亡率低于如果病情轻和病情重的人各一半的情况。治疗 B 的情况则相反,这就导致了 Total 一列 16%<19%。
其实,方案 A 或方案 B 都可能是正确答案,这取决于数据的因果结构。换句话说,因果关系是解决辛普森悖论的关键。在下文,我们会首先从直觉上给出什么时候应该偏向于方案 A,什么时候应该偏向于方案 B。更理论的解释会放到后面再讲。
Scenario 1
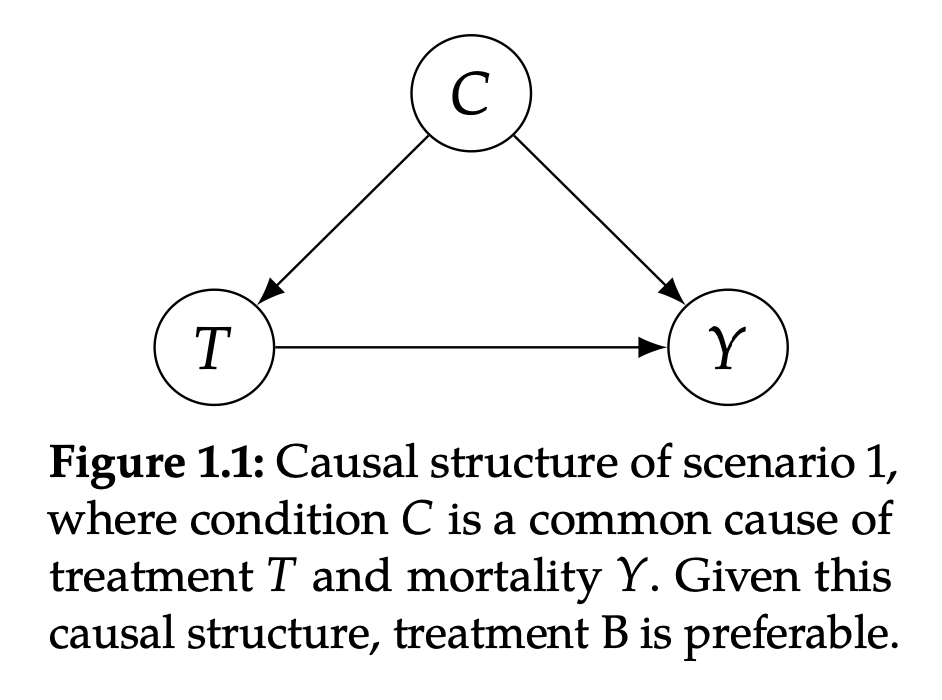
▲ 图1.1
如图 1.1 所示,C(condition)是 T(treatment)和 Y(outcome)的共同原因。这里 C 代表病情轻重,T 代表治疗方案,Y 代表是否死亡。这个 Graph 的意思是说病情轻重会影响医生给你用哪种方案,而且病情轻重本身也会导致是否死亡。治疗 B 在降低死亡率方面更有效。
在这种情况下,医生决定给大多数病情轻微的人提供 A 方案,而把更昂贵、更有限的 B 治疗方法留给病情严重的人。因为病情严重的人更有可能死亡(图 1.1 中的 C→Y ),并导致一个人更有可能接受 B 治疗(图 1.1 中的 C→T)。因此,总体 B 的死亡率更高的原因仅仅是选择方案 B 中的人大多数(500/550)是重症,而重症即使用了更贵的方案 B,死亡率 100/500=20% 也比轻症用方案 B 的死亡率 5/50=10% 要高,最终混合的结果会更偏向于重症的结果。
在这里,病情 C 混淆了治疗 T 对死亡率 O 的影响。为了纠正这种混杂因素,我们必须研究相同条件的病人的 T 和 Y 的关系。这意味着,最好的治疗方法是在每个子群体(表1.1 中的“mild”和“severe”列)中选择低死亡率的治疗方法:即方案 B。
Scenario 2
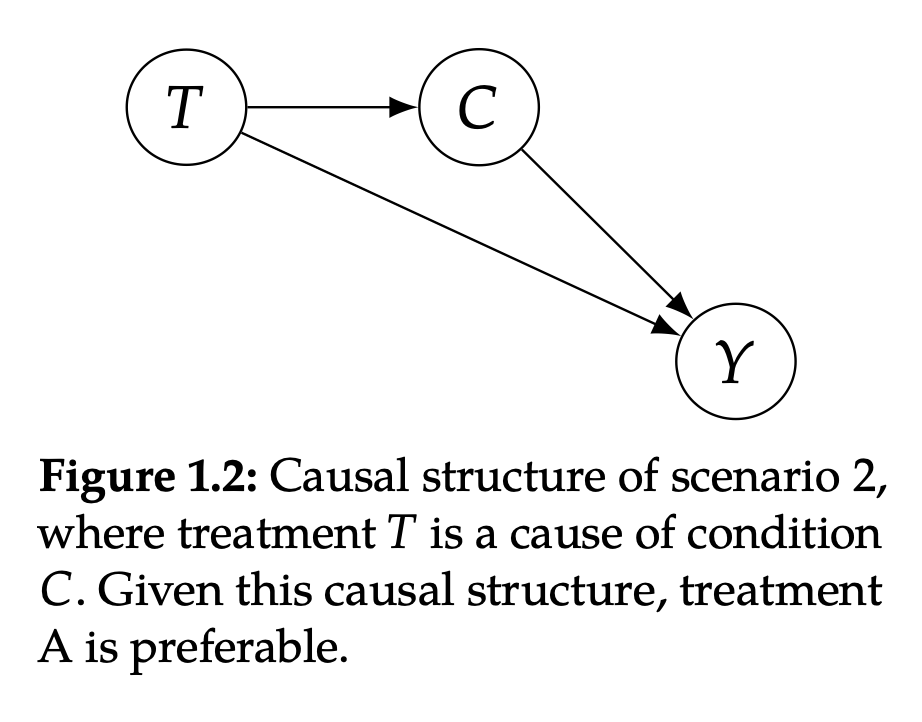
▲ 图1.2
如图 1.2,T(治疗方案)是 C(病情轻重)的原因,C 又是 Y(死亡与否)的原因。这种情况的实际场景是:方案 B 非常稀缺,以至于患者在选择接受治疗后需要等待很长时间才能实际接受治疗,而选择 A 的患者很快就会得到治疗。在这种情况下,治疗方案是与病情无关的,而情境一,病情会决定方案。
由于 COVID-27 患者的病情会随着时间的推移而恶化,方案 B 实际上会导致病情较轻的患者发展为重症,从而导致更高的死亡率。因此,即使 B 一旦用药就比 A 更有效(图1.2 中的正面作用 T→Y),由于方案 B 的长时间等待会导致病情恶化(图1.2 中的负面作用 T→ C →Y)550 个选择 B 的人里面有 500 人因为等的时间长变重症了,而只有 50 人是轻症,因此 total 的结果 19% 会更偏向于 B 的重症死亡率 20%。同理,Total A 的死亡率 16% 会更偏向于 A 的轻症死亡率 15%。
此时,最优的选择是方案 A,因为 total 的死亡率更低。而实际表格的结果也符合,因为 B 治疗更贵,所以以 0.27 的概率选择方案 B,而以 0.73 的概率选择 A。
总之,更有效的治疗完全取决于问题的因果结构。在情景 1 中(图1.1), B 更有效。在情景 2 中(图1.2)的一个原因, A 更有效。没有因果关系,辛普森悖论就无法解决。有了因果关系,这就不是悖论了。
1.2 因果推断的应用
因果推断对科学来说是至关重要的,因为我们经常想提出因果要求,而不仅仅是关联性要求。例如,如果我们要在一种疾病的治疗方法中进行选择,我们希望选择能使大多数人得到治愈的治疗方法,同时又不会造成太多的不良副作用。如果我们想让一个强化学习算法获得最大的回报,我们希望它采取的行动能使它获得最大的回报。如果我们研究社交媒体对心理健康的影响,我们就会试图了解造成某一心理健康结果的主要原因是什么,并按照可归因于每个原因的结果的百分比排列这些原因。
因果推断对于严格的决策至关重要。例如,假设我们正在考虑实施几种不同的政策来减少温室气体排放,但由于预算限制,我们必须只选择一种。如果我们想最大限度地发挥作用,我们应该进行因果分析,以确定哪种政策将导致最大的减排。再举一个例子,假设我们正在考虑采取几项干预措施来减少全球贫困。我们想知道哪些政策将最大程度地减少贫困。
既然我们已经了解了辛普森悖论的一般例子以及科学和决策中的一些具体例子,我们将转向因果段与预测的不同之处。
1.3 相关性
≠
因果关系
许多人都会听过“相关并不意味着因果(correlation does not imply causation)”的口头禅。首先通过一个例子解释为何会这样。
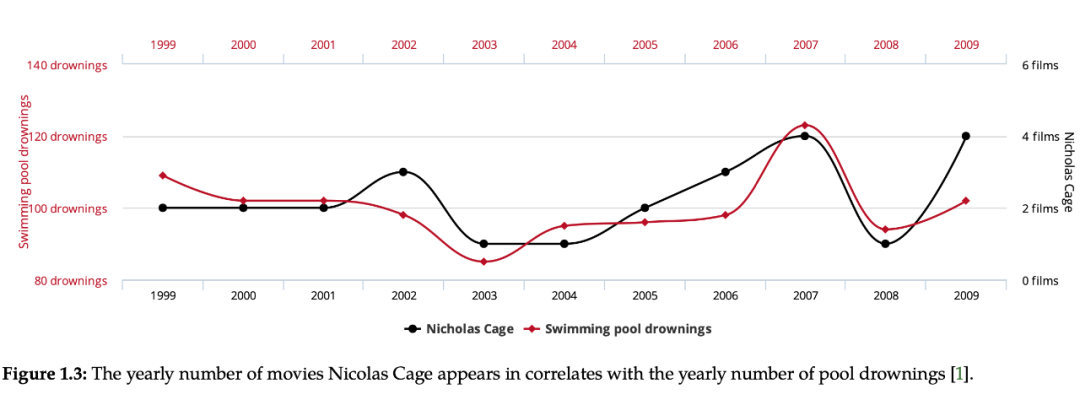
▲ 图1.3
如图 1.3,每年因落入游泳池而溺水的人数与 Nicolas Cage 每年出演的电影数量具有高度相关性。如果只看这张图可以得到以下几种解释:(1)Nicolas Cage 在他的电影中鼓励糟糕的游泳者跳进游泳池。(2)当 Nicolas Cage 看到那一年发生了多少溺水事件时,他是更有动力去出演更多的电影。(3)也许尼古拉斯凯奇有兴趣增加他在因果推理从业者中的知名度,所以他回到过去说服他过去的自己做正确数量的电影让我们看到这种相关性,但又不完全匹配,因为这会引起怀疑,从而阻止他以这种方式操纵与数据的相关性。
但是,只要是个有常识的人都知道上述解释都是不对的,两者没有因果关系,因此是一种虚假的相关性。从这个简单的例子我们可以直观的理解“相关性并不等于因果关系”。
1.3.1 为什么关联不等于因果
注意:“相关性 (Correlation)”经常被口语化地用作统计依赖性(statistical dependence)的同义词,然而,“关联”在理论上只是对 linear statistical dependence 的一种衡量。在以后,我们将统一使用关联(association)一词来表示 statistical dependence。
对于任何给定数量的关联,并不是“所有的关联都是因果关系”或“没有任何关联是因果关系”。有可能存在大量的关联,而其中只有一部分是因果关系。”关联不等于因果“只是意味着关联的数量和因果的数量可以是不同的。
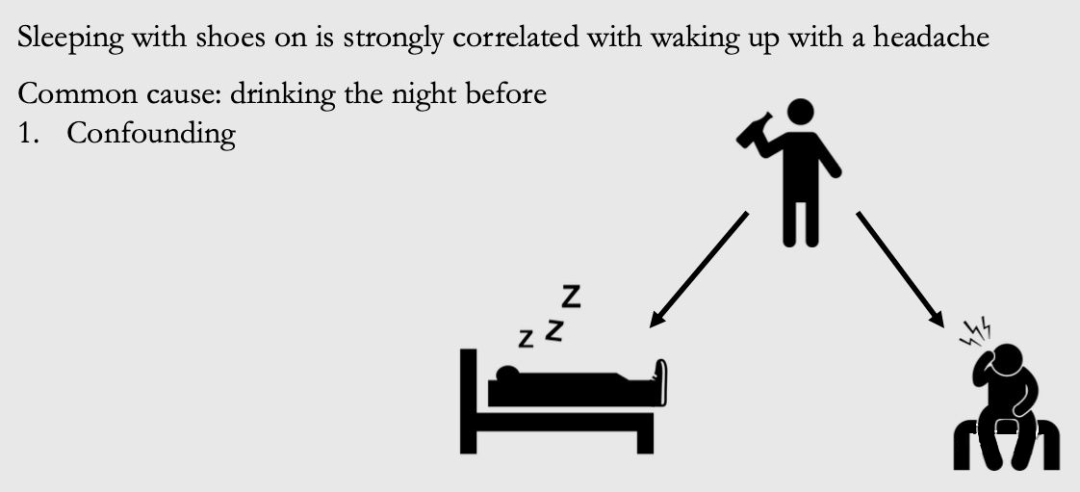
再考虑一个例子,假设我们有穿鞋睡觉和醒来后头痛的数据。结果发现,在大多数情况下,如果有人穿鞋睡觉,醒来后会头痛。而在大多数情况下,如果不穿鞋睡觉,醒来后不头痛。如果不考虑因果,人们把这样有关联的数据解释为“穿鞋睡觉会导致人们醒来头痛”,尤其是当他们在寻找一个理由来证明不穿鞋睡觉是合理的。
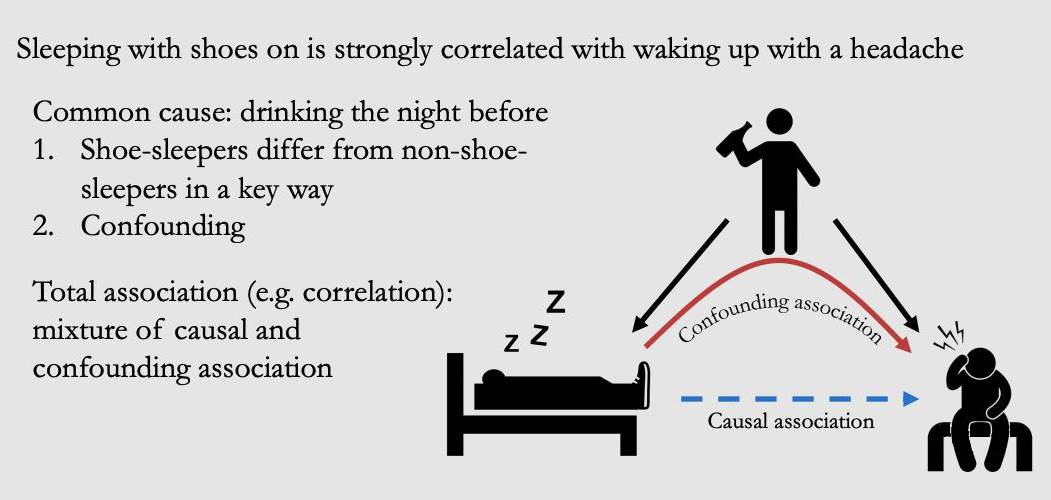
▲ 图1.4
事实上,它们都是由一个共同的原因引起的:前一天晚上喝酒(喝醉了大概率才会穿鞋睡觉)。如图 1.4 所示,这种变量被称为“混杂因子(confounder)”或“潜伏变量(lurking variable)”。我们将由 confounder 引起的关联称为 confounding association,其实是一个虚假的关联。
观察到的 total association 可以由混杂关联 confounding association(图中红色箭头)和因果关联 causal association(图中蓝色箭头)组成。可能的情况是,穿鞋睡觉确实对醒来后的头痛有一丢丢的因果关系。那么,总的关联将不只是混杂关联,也不只是因果关联,它将是两者的混合。例如,在图 1.4 中,因果关系沿着从穿鞋睡觉到头痛醒来的蓝色箭头流动。而混杂关联则沿着从穿鞋睡觉到喝酒再到头痛的红色路径流动。我们将在第三章中对这些不同种类的关联做出明确的解释。
1.4 涉及的一些概念
Statistical vs. Causal 即使有无限量的数据,我们有时也无法计算一些因果量。相比之下,许多统计数据都是关于解决有限样本中的不确定性。当给定无限数据时,没有不确定性。然而,关联是一个统计概念,并不是因果关系。即使拥有无限数据,在因果推断方面还有更多工作要做。
Identification(识别)vs. Estimation(估计)识别因果关系是因果推理的特有内容。即使我们有无限的数据,这也是一个有待解决的问题。然而,因果推理也与传统的统计学和机器学习有着共同的估计。我们将主要从因果关系的识别开始(第2、4 和 6 章),然后转向因果关系的估计(第 7 章)。
Interventional(干预)vs. Observational(观察)如果我们能够进行干预/实验,因果关系的识别就相对容易。这是因为我们可以实际采取我们想测量因果关系的行动,并简单地测量我们采取该行动后的因果关系。然而,如果只有观察性数据,识别因果关系比较困难,因为会有前面提到的 confounder 的存在。

潜在结果potential outcome
2.1 潜在结果 & 独立因果效应
首先通过两个例子引入这两个概念。
Scenario 1:假设你现在很不开心。而你正在考虑是不是要养一只狗来变得开心些。如果你在养狗后变得开心,这是否意味着是狗狗使你变得快乐?而如果你没有养狗,你同样也变得开心了呢?在这种情况下,狗并不是使你开心的必要条件,所以狗对你开心与否有因果效应的这个说法是不太对的。
Scenario 2:另一种情况是,如果你在养狗后变得开心。但是如果你没有得到一只狗,你依然会不开心。在这种情况下,狗狗对与你的开心就有很强的因果效应。
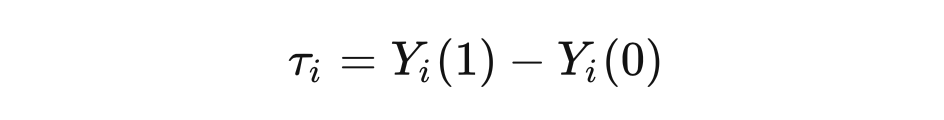
2.2 因果推断中的基本问题
2.3 如何解决基本问题
2.3.1 平均因果效应 & 缺失数据解释
既然无法得到独立因果效应,那么能否得到平均因果效应(Average Treatment Effects,ATE)呢?理论上可以通过求期望来得到:
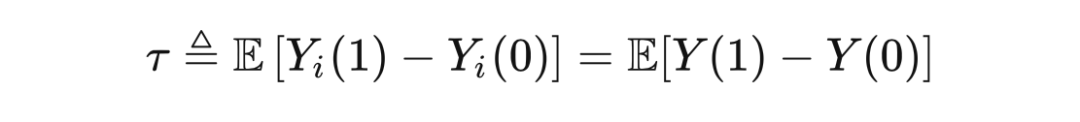
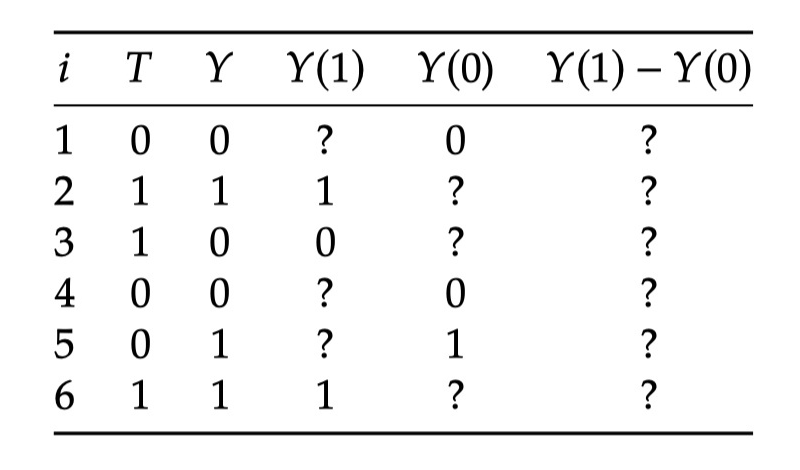
▲ 表2.1
但我们实际上如何计算 ATE 呢?让我们看一下表 2.1 中的一些捏造的数据。我们把这个表作为整个 population of interest。由于因果推断的基本问题,导致有些缺失数据。表中所有的?都表示我们没有观察到这个结果。
从这张表中,我们很容易计算出 associational difference(通过 T 列和 Y 列):
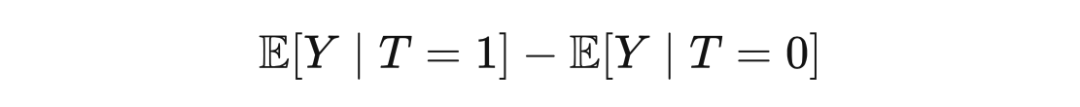
通过期望的线性运算法则,ATE 可以写成:
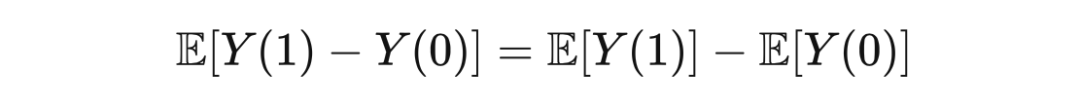
乍一看,你首先可能会直接得到
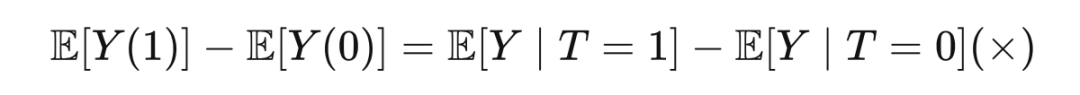
但其实这是错误的做法。如果这个公示成立,则意味着“因果就是关联”,这个观点我们在第一章已经反驳过了。
以第一章中穿鞋睡觉是否会导致第二天头痛的例子为例

T=1 中,绝大多数都是喝了酒的,而 T=0 中绝大多数都是没喝酒的。T=1 和 T=2 这两个 subgroub 是 uncomparable 的,E[Y|T=1] 肯定是要大于 E[Y(1)] 的,因为喝酒才会更容易头疼。
那么 comparable 的两个 group 长什么样呢?就如下图所示,这时候两个式子之间就可以划等号了。
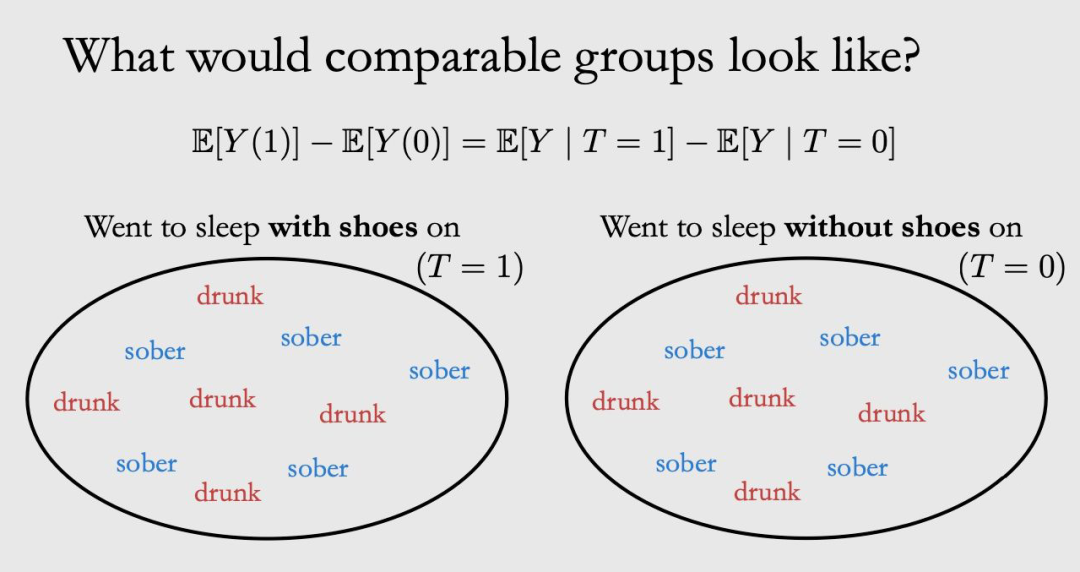
2.3.2 Ignorability & Exchangeability
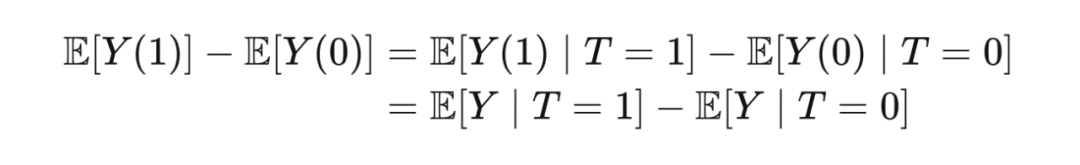
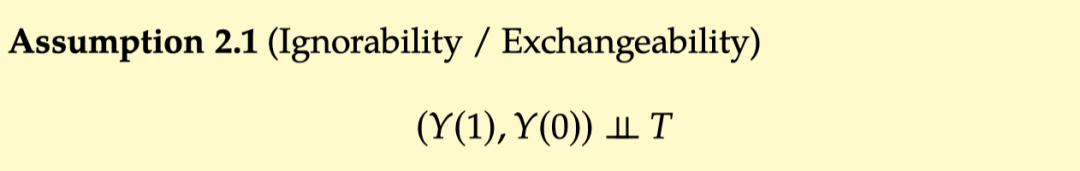
可以从两个方面来理解假设 2.1 中的独立性:Ignorability 和 Exchangeability。
Ignorability:
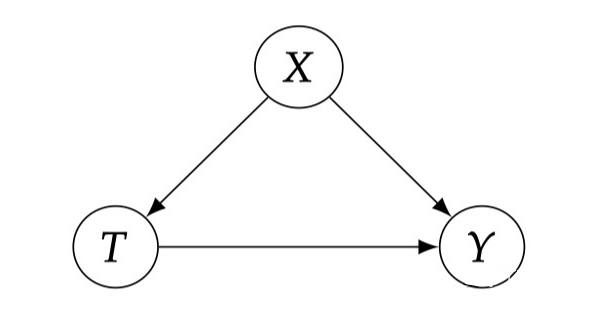
▲ Fig 2.1
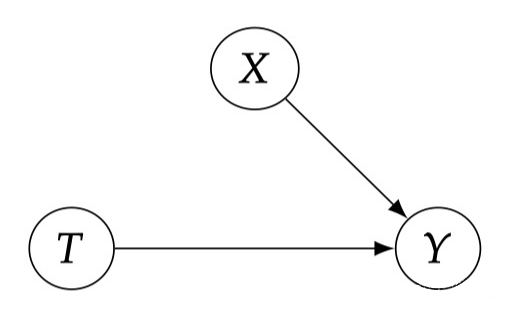
▲ Fig 2.2
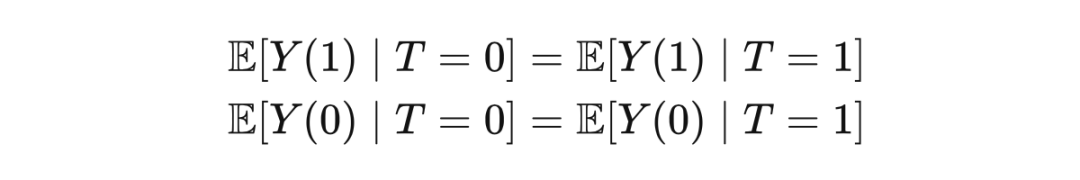
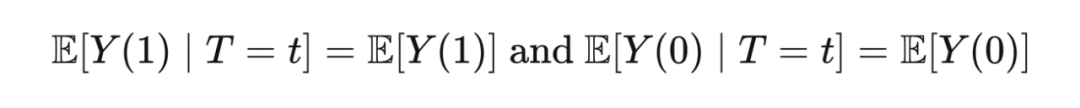
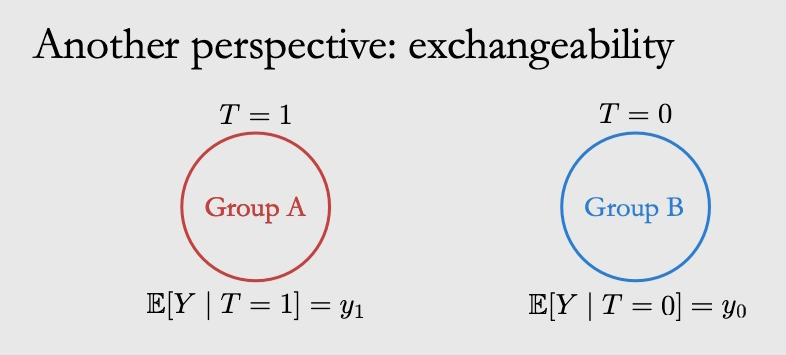
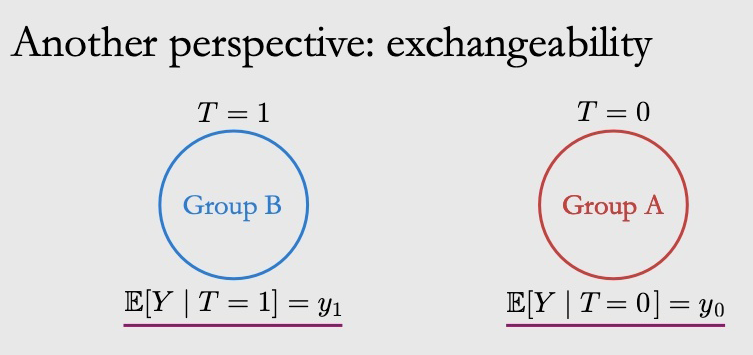
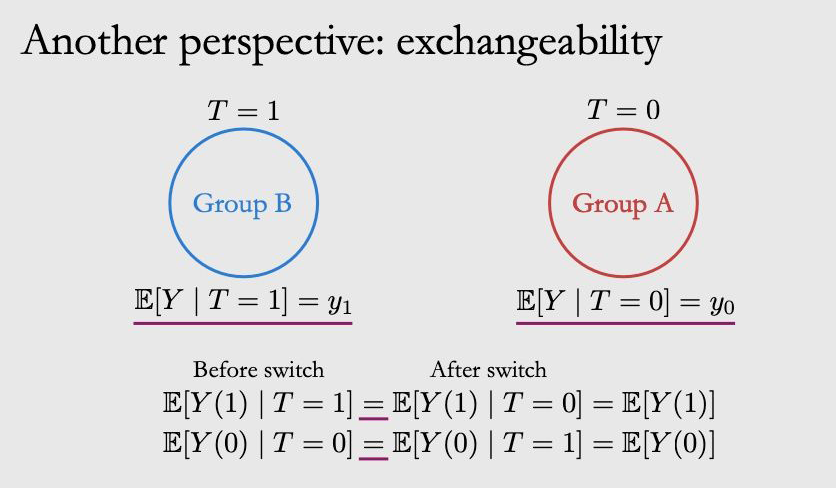

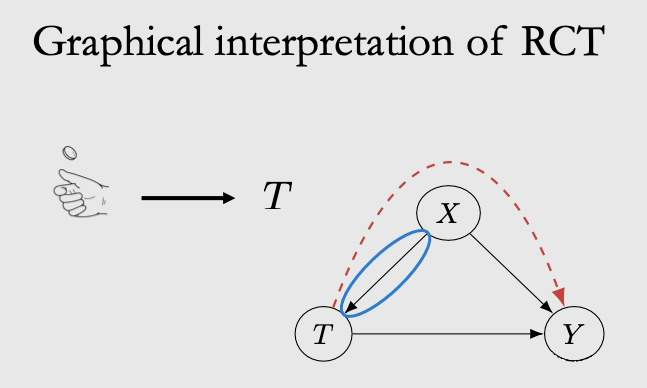
2.3.3 Conditional Exchangeability & Unconfoundedness
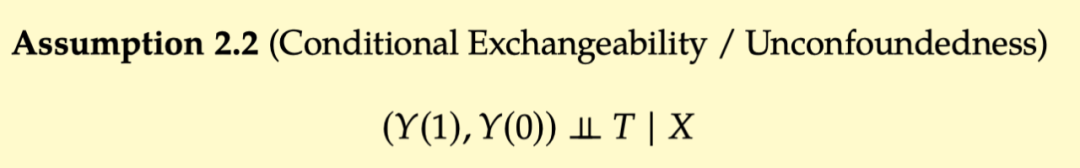
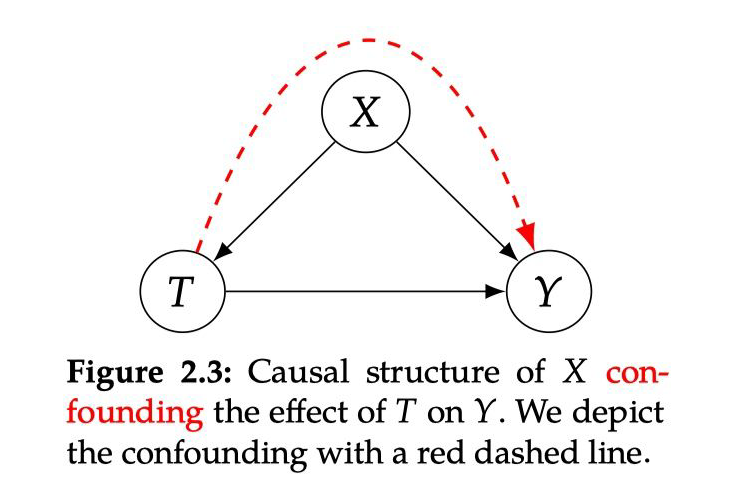
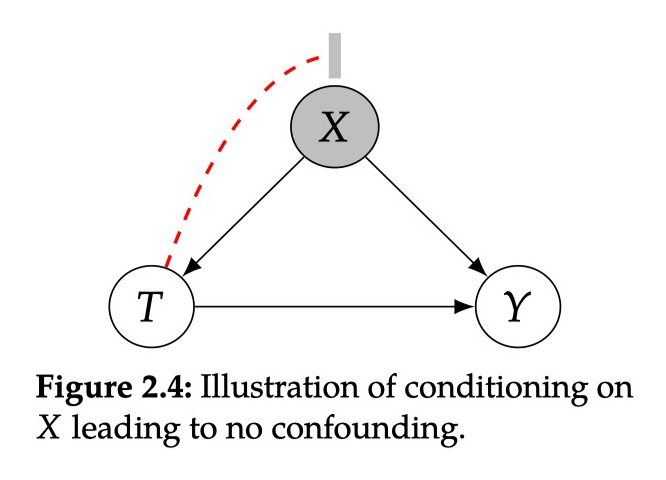
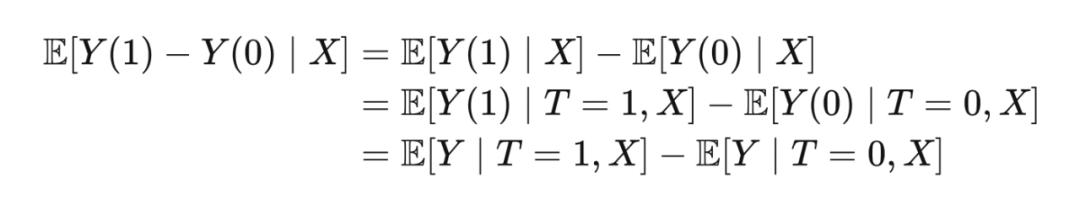

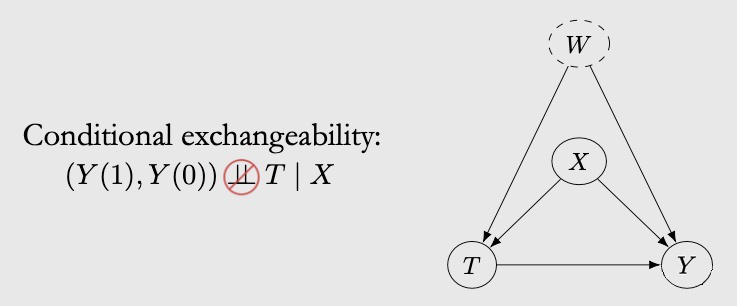
2.3.4 Positivity/Overlap and Extrapolation
虽然想象中对许多协变量进行 condition 可以实现 unconfoundedness,但它实际上可能是有副作用的。这与另一个我们尚未讨论的假设有关:Positivity 积极性。Positivity 是指具有不同协变量值 X=x 的任何 group 都有一定的概率接受任何 value 的 treatment。即 。为了好理解把原文也贴出来,建议大家停下来仔细回味一下 Positivity 的意思。
Positivity is the condition that all subgroups of the data with different covariates have some probability of receiving any value of treatment. Formally, we define positivity for binary treatment as follows.
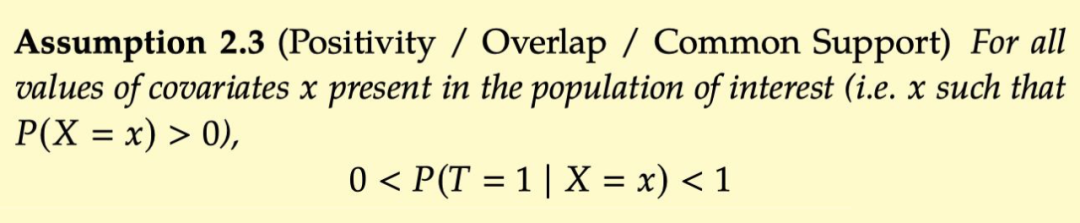
下面解释 positivity 为啥重要,首先回顾下调整公式:
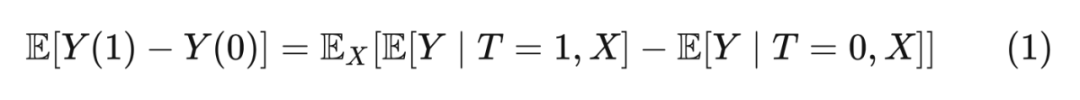
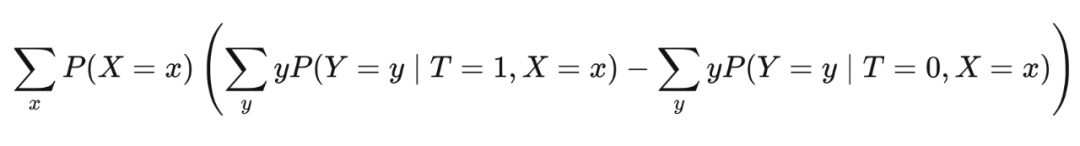
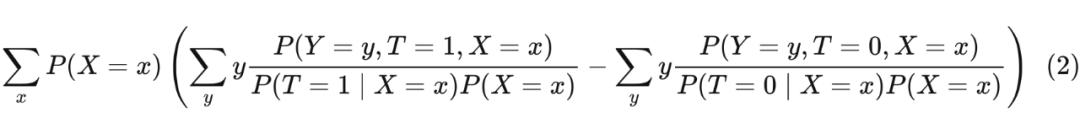
The Positivity-Unconfoundedness Tradeoff:
尽管 condition on 更多的协变量可能会有更高的机率满足 unconfoundedness,但同样会有更大的机率违反 Positivity。随着我们增加协变量的数量,每个 subgroup 越来越小,整个 subgroup 得到同样 treatment 的可能性越来越高。例如,一旦任 subgroup 的大小减少到 1,肯定不会满足 Positivity。
2.3.5 No interference, Consistency, and SUTVA
这一小节再介绍几个其他的概念:
No interference:
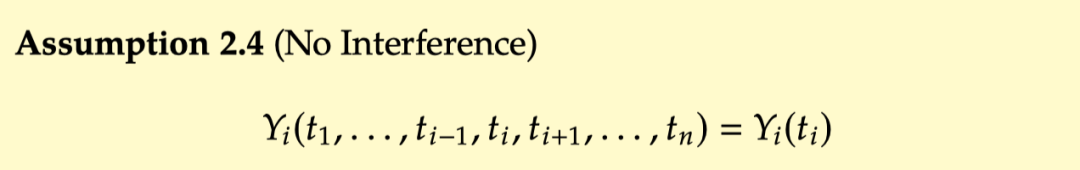
No interference 指的是每个个体的 potential outcome 只和当前这个个体所接受的 treatment 有关,和其他个体的 treatment 无关。
Consistency:

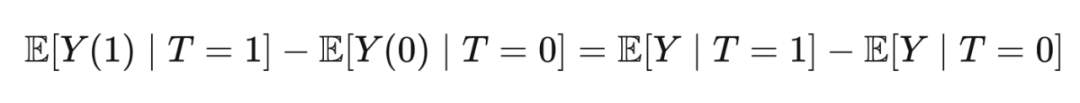
2.3.6 Tying It All Together
搞明白上述假设后,我们再来回顾下调整公式,这一次在每个等式后把需要的假设列了出来:


图中的因果流和关联流
3.1 什么是图?
我猜看这系列文章的朋友对图 Graph 的概念已经再熟悉不过了,这里就不费口舌细说了。图是由节点 node 和边 edge 组成的一个数据结构,下面放几张普通类型图的示例:
3.2 贝叶斯网络
因果图模型的许多工作是在概率图模型的基础上完成的。要了解因果图首先要了解一下什么是概率图模型,虽然两者有着很大差别。贝叶斯网络是最主要的概率图形模型,因果图模型(因果贝叶斯网络)继承了它们的大部分属性。
联合概率分布可以通过 chain rule 写成如下形式:
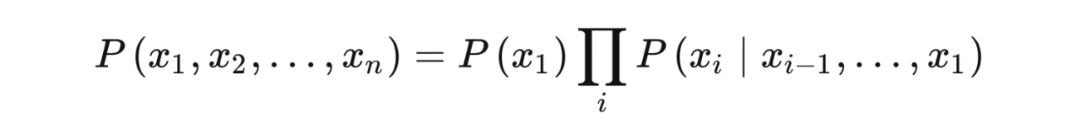
如果直接对上面公式建模的话,参数数量会爆炸


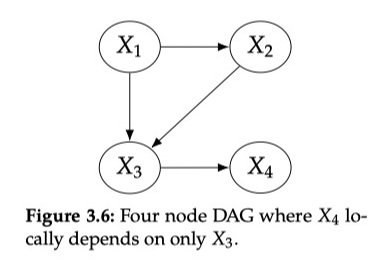
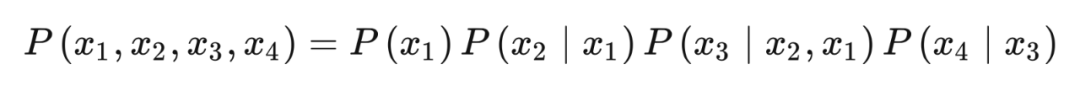


3.3 因果图


3.4 最简单的结构
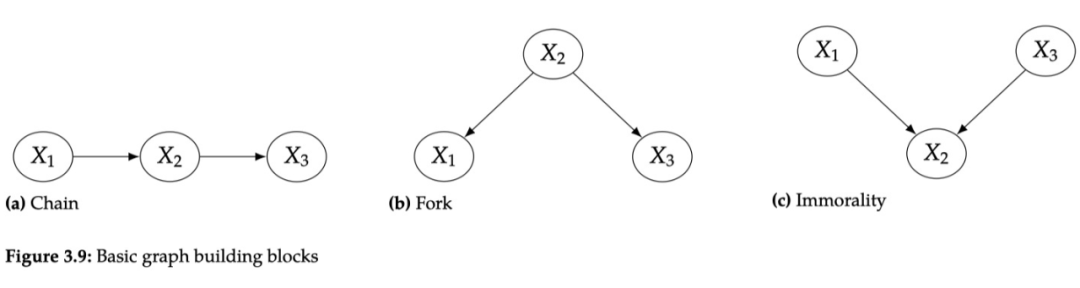
3.5 链 & 叉子结构
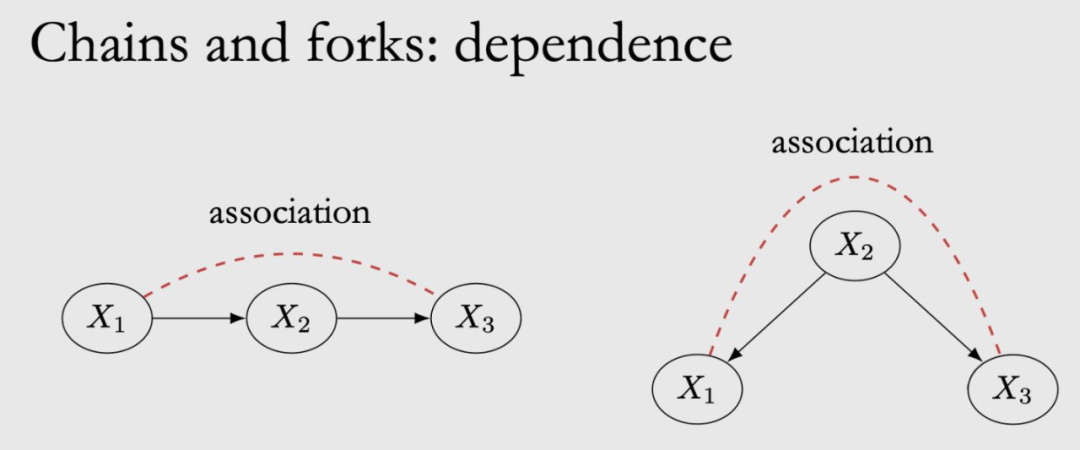
相关性:
在 chain 中,x1 是 x2 的原因,x2 是 x3 的原因,那么 x1 和 x2 是相关的,x2,x3 是相关的,x1 和 x3 也是相关的。
在 fork 中,x2 是 x1 和 x3 的共因,x1 和 x3 也是相关的。这个可能有点反直觉,x1,x3 之间明明没有边,为啥也是有关联的呢?举个例子:温度升高会导致冰淇淋销量上升,同时也会使犯罪率上升,从冰淇淋销量和犯罪率的数据上来看,他们有着相同的趋势,因此是相关的,尽管他们之间并没有因果关系。
关联流 associate flow 是对称的,x1 和 x3 相关,x3 也和 x1 相关,即图中红色虚线部分。而因果流是非对称的,只能沿着有向边流动,即 x1 是 x3 的原因,x3 不是 x1 的原因。
独立性:
chain 和 fork 也有着相同的独立性。如果我们把 x2 固定住,即 condition on x2,那么 x1 和 x3 的相关性就会被阻断 block,变的独立。
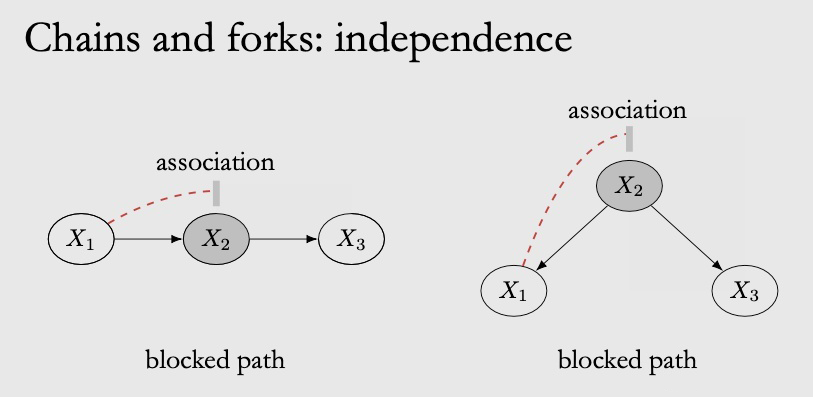
在 chain中,如果把 x2 固定成一个定值,x1 做任何改变,都不会影响 x2 的变换,因为已经被固定了,那么 x3 也不会发生变化,因此 x1,x3 变的独立。
Proof:
chain 的联合概率分布如下:
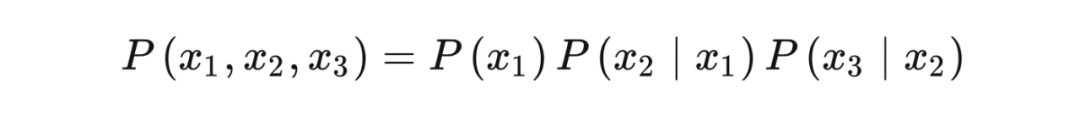
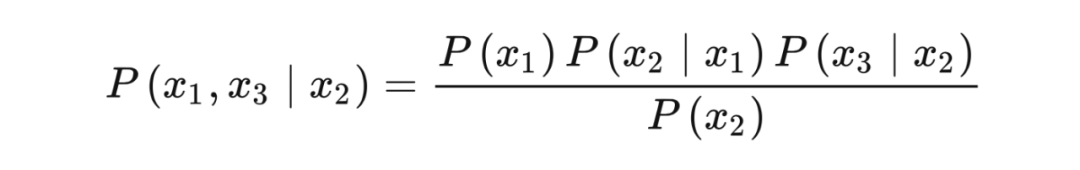
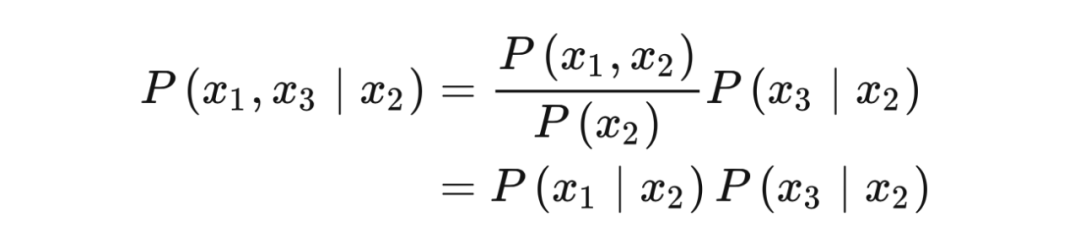
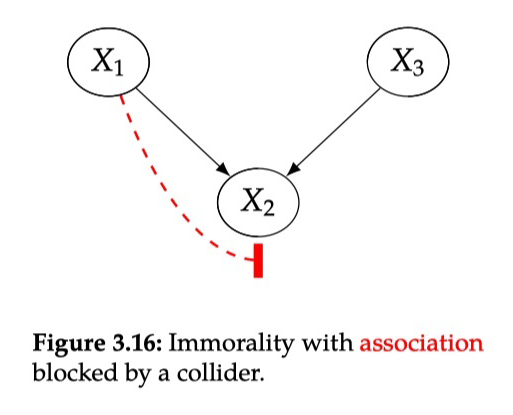
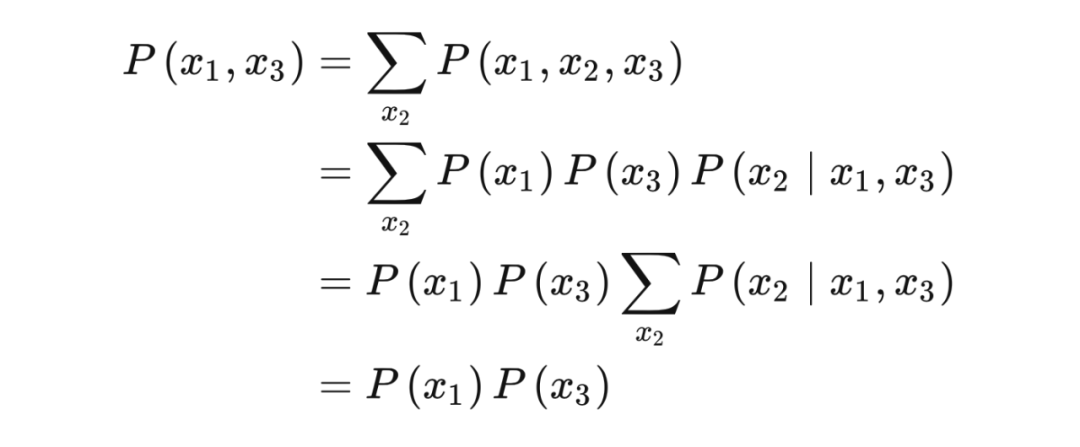
3.7 d-分离
-
这条路径存在 chain( )或者存在 fork( ),且 condition on W( ) -
这条路径存在一个 collider W( ),并且并且 W 的所有后代节点也不固定( )

同理,unblocked path 的定义与 block path 相反。blocked path 中不存在从 X 到 Y 的 association flow,被 block 掉了。unblocked path 中存在从 X 到 Y 的 association flow。
下面给出 d-分离的概念:


小练习:
3.8 因果流和关联流

因果模型、do算子、干预
4.1 do算子和干预
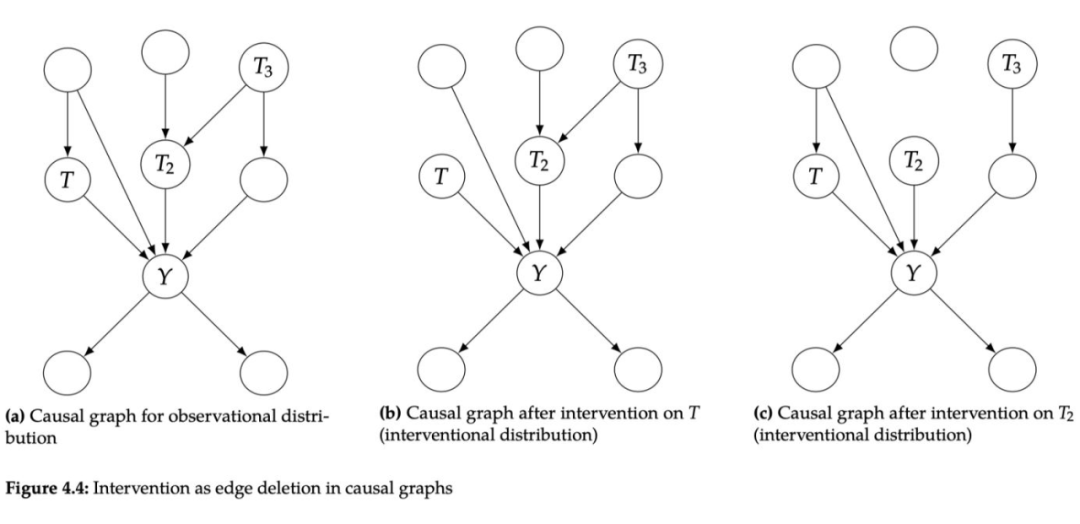
在概率中,我们有以... 为条件的概念(condition on),但这与干预不同。以 为条件仅意味着我们将关注点限制在 整体人群中接受 treatment=t 的这一部分人群。相比之下,干预 intervention 是让整体人群都接受 treatment=t,而不管观察到的其本身的 treatment 是否为 t。通常用 do 算子表示干预操作,即让整体人群都接受 treatment=t 等价于 。可以对照图 4.2 加深理解,subpopulations 表示观察到的数据中蓝色部分是 T=0 的集合,红色部分是 T=1 的集合。Conditioning 表示我们只关注其中的蓝色部分或红色部分。do(T=1) 是指让本身 T=0 的蓝色部分也变成 T=0,即红色。

还记得第二章讲的潜在结果 potential outcome 吗, 和 是等价的。 的分布可以写成:
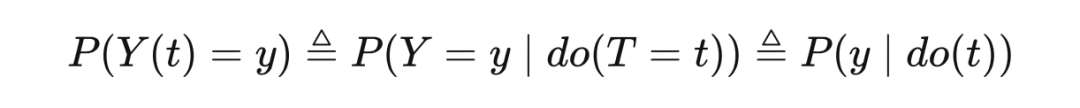
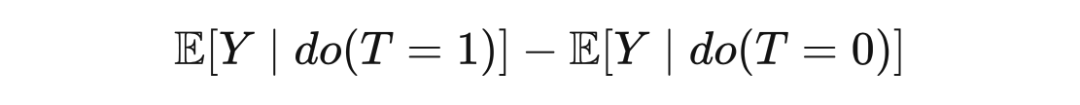
4.2 Modularity模块化假设
在介绍这个非常重要的假设之前,我们必须指定因果机制是什么。有几种不同的方法可以考虑因果机制。在本节中,我们将产生 的因果机制指定为 的条件概率分布 。正如图 4.3 所示,产生 的因果机制是所有 的父节点及其指向 的边。
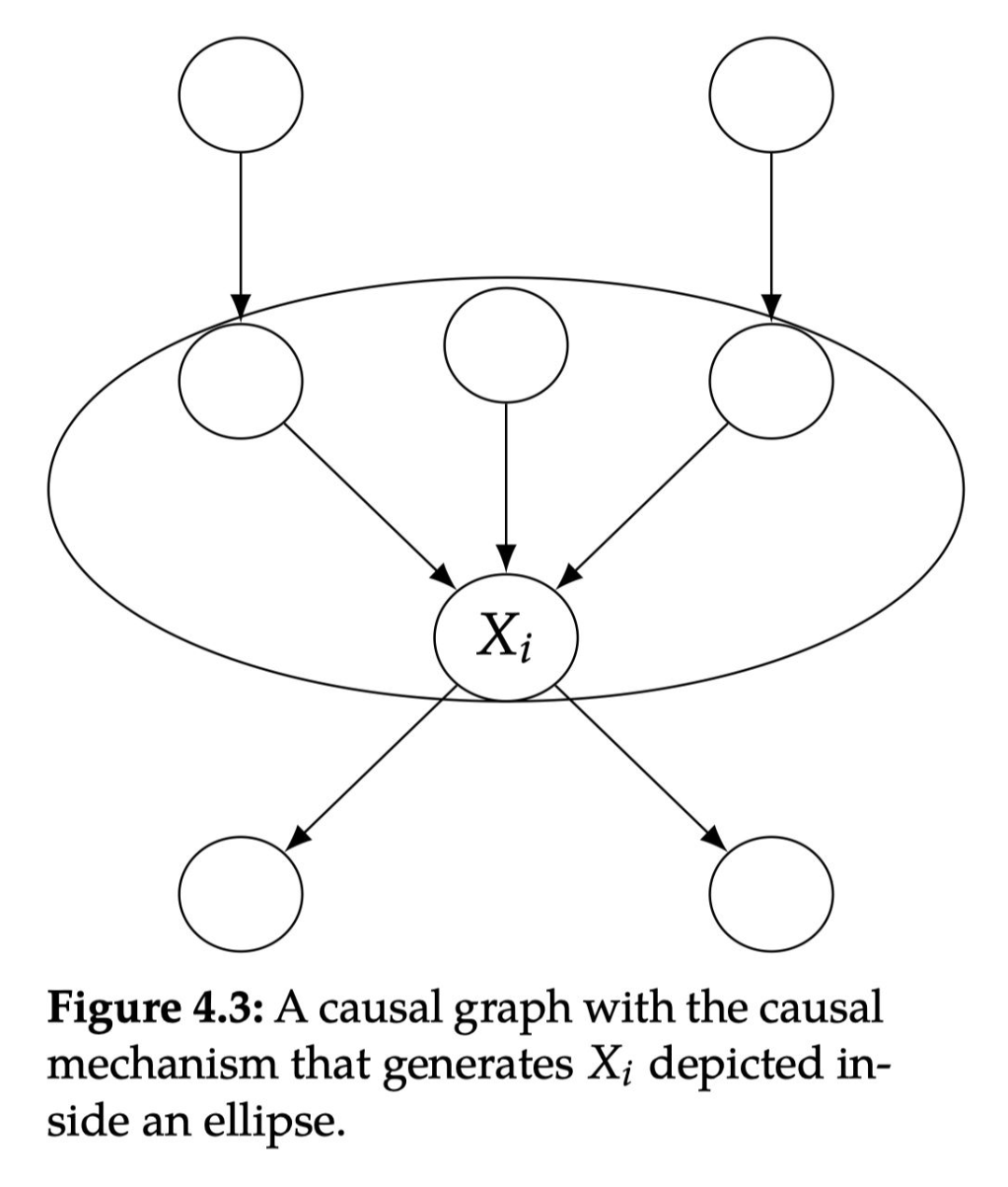
模块化假设是指:假设对变量 干预只会改变 的因果机制,只局限在图中椭圆内,不会改变生成任何其他变量的因果机制。从这个意义上讲,因果机制是模块化的。模块化假设的明确定义如下:

如果节点 i 不在集合 S 中,那么其条件概率分布保持不变
-
如果节点 i 在集合 S 中,如果 是变量 被干预后指定的值, 那么 一定为 1,否则为 0。
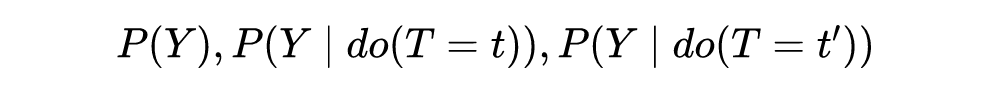
4.3 截断因式分解
回顾下贝叶斯网路中联合概率分布的分解形式:
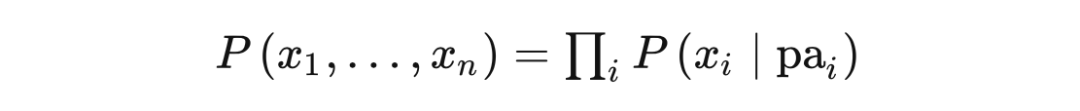
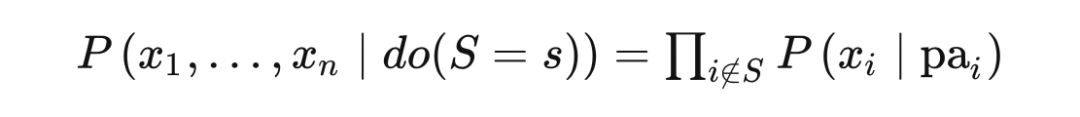
4.3.1 Example
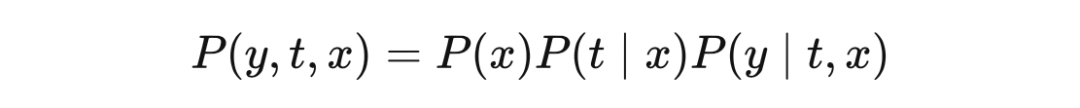
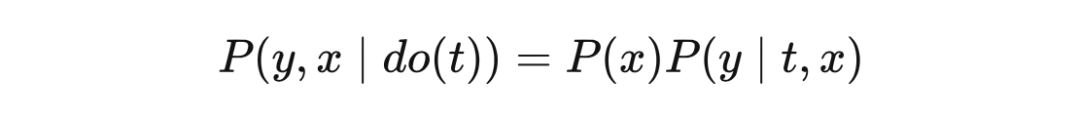
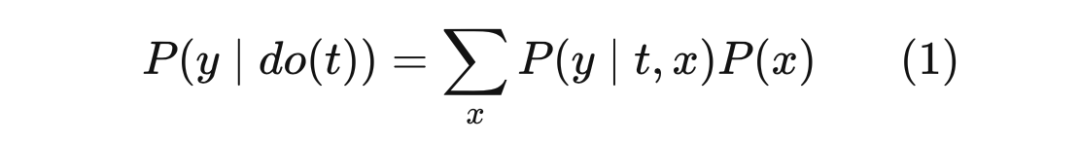
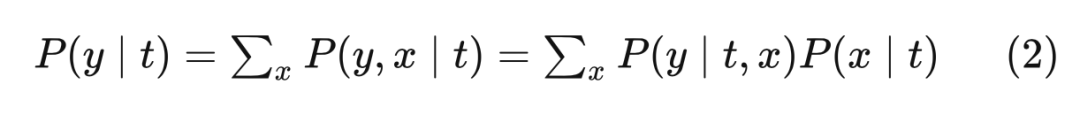
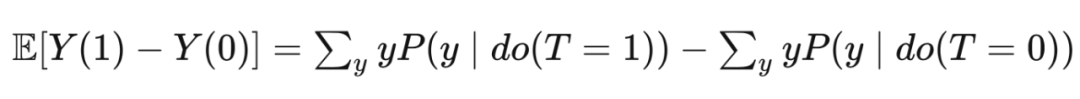
4.4 后门调整
4.4.1 后门路径
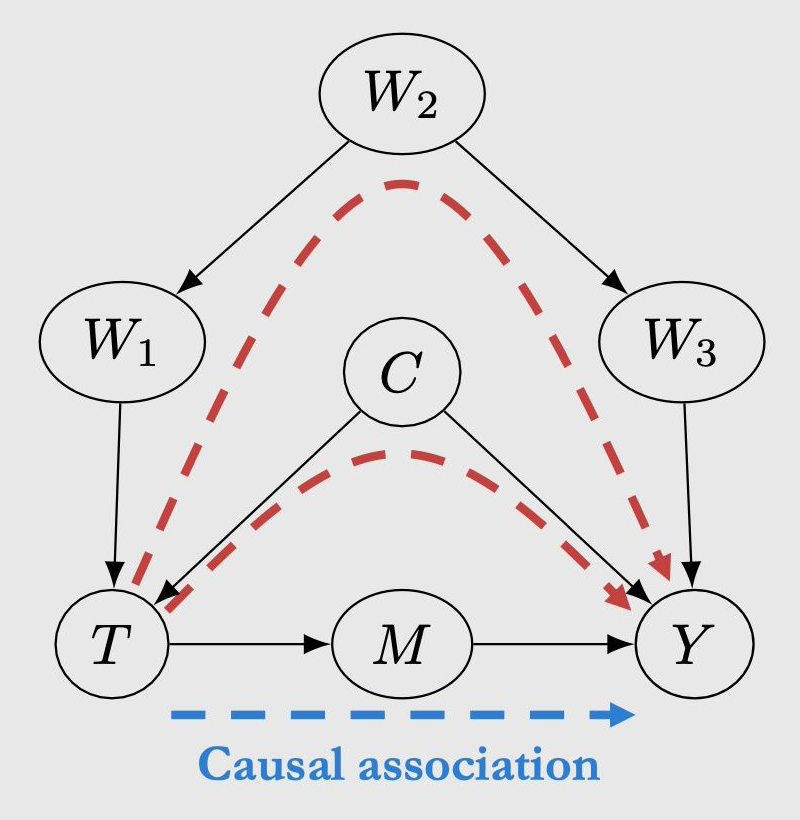
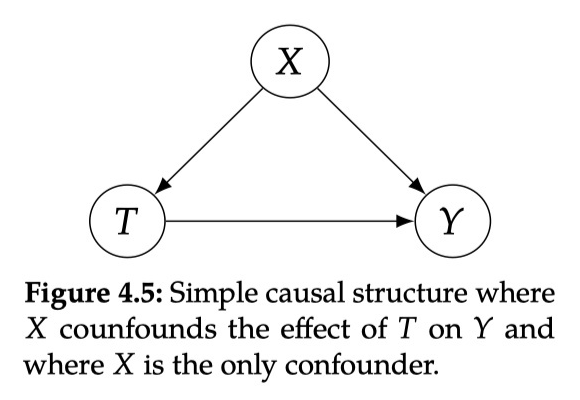
以上图为例,回顾第三章,从 T 到 Y 存在两种 association,其中一种是 的因果关联,另一种是 和 的非因果关联,也称这两条路径是 unblocked(因为都是叉结构,且没有 condition on)。后门路径的含义就是,如果一条从 T 到 Y 的路径是 unblocked,且有指向 T 的边(即 ),则称这条路径是后门路径。为什么叫后门呢,因为本身这条路径是没有从 T 到 Y 的有向边的,但是因为有一条指向 T 的边,相当于进入了 T 的后门,这条路径就被打通了。
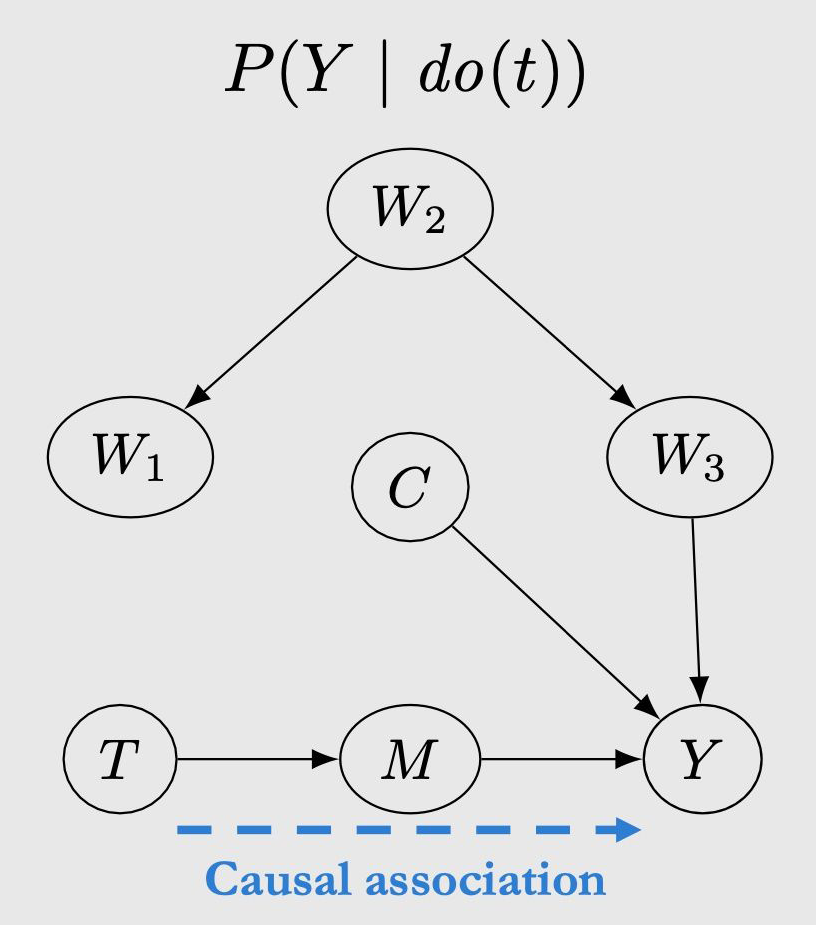
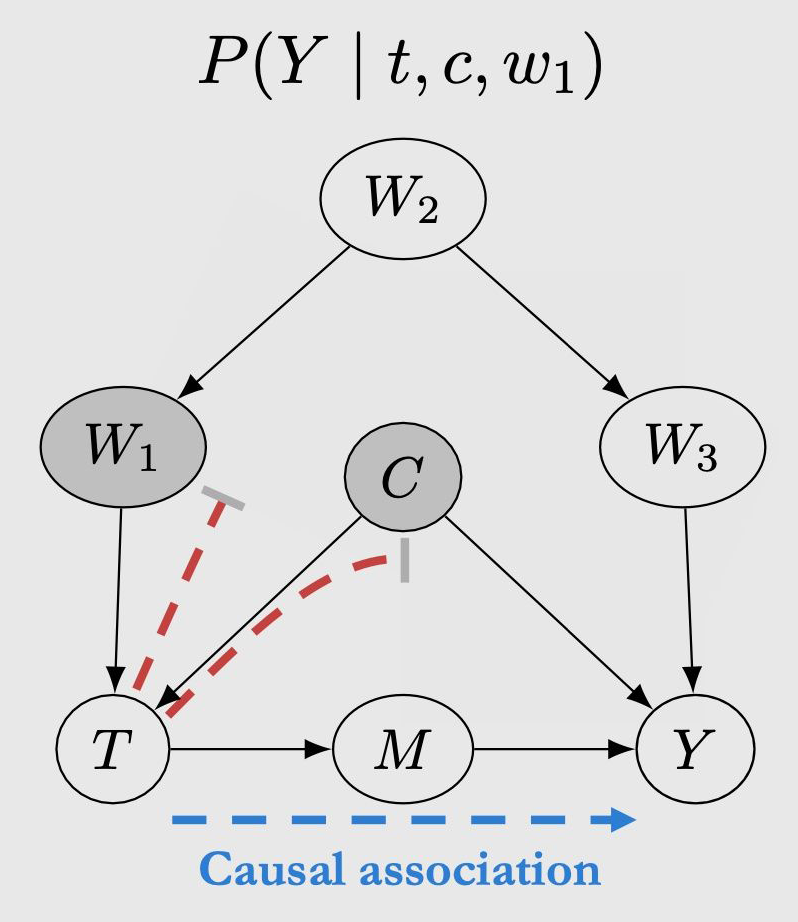
4.4.2 后门准则,后门调整
如果我们想将 完全写成概率的形式,则需要假设 W 满足后门准则。
-
condition on W 可以阻断 T 和 Y 之间的所有后门路径
-
W 不包括 T 的所有子孙节点

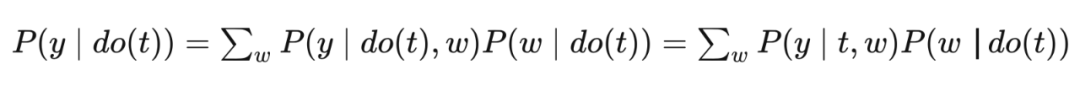
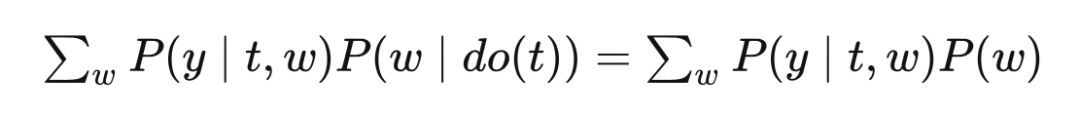
这就是后门调整公式。

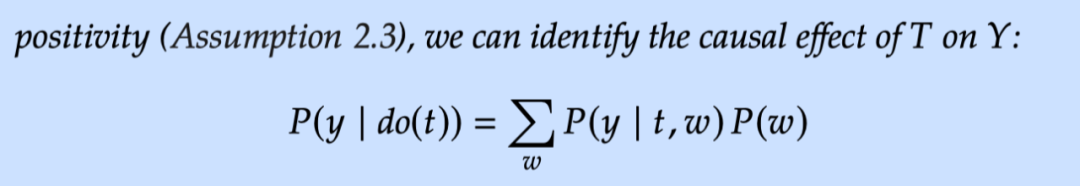
4.4.3 Relation to Potential Outcomes
还记得第二章介绍过的调整公式吗:
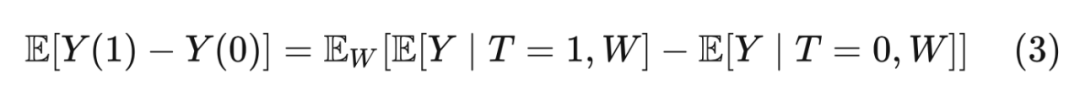
既然都叫调整公式,后门调整和 Eq(3) 有什么联系吗?对干预后的 Y 求期望:
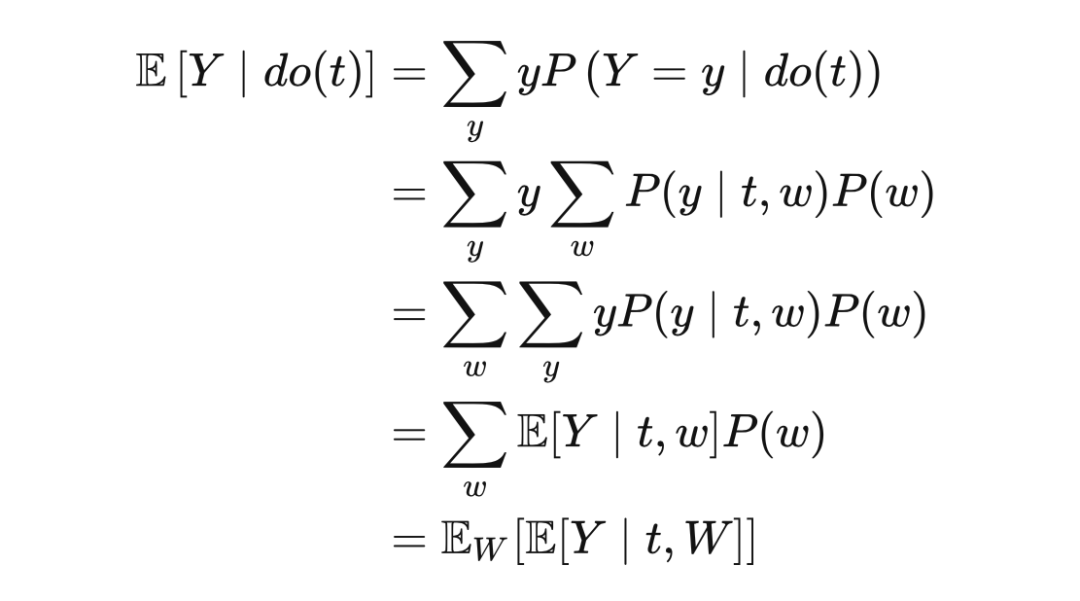
把 T=1 和 T=0 代入得:
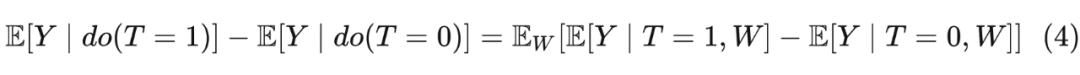
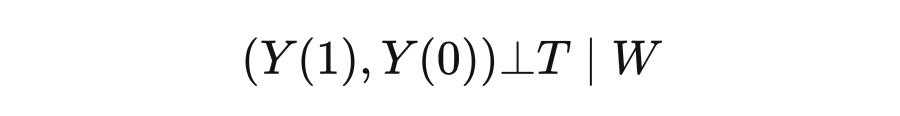
4.5 结构因果模型
本节我们将从因果图模型转到结构因果模型。相比于比较直观的图模型,结构因果模型可以更详细清晰的解释什么是干预和因果机制。
4.5.1 结构等式
Judea Pearls 说过,数学中的“=”不包含任何因果信息, 和 表示的都是同一个意思,“=”是对称的。但是为了表达因果,需要有一个非对称的符号。如果 A 是 B 的原因,那么改变 A 一定会改变 B,但是反之不成立,我们可以用结构等式 structural equation 来表示:
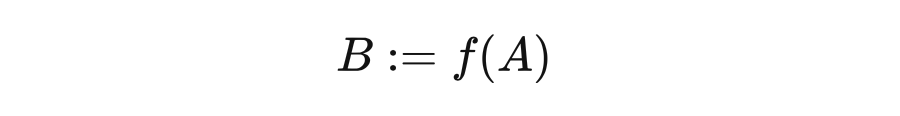
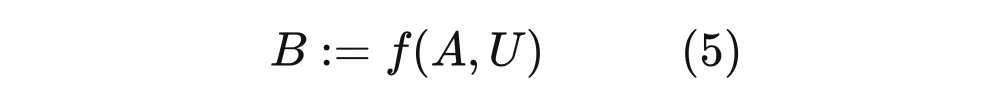
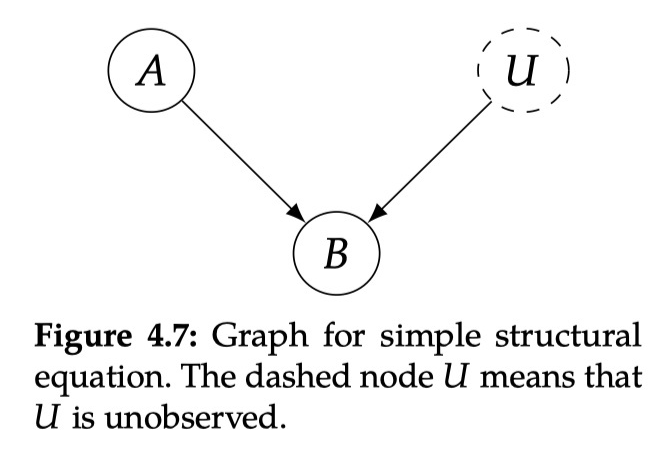
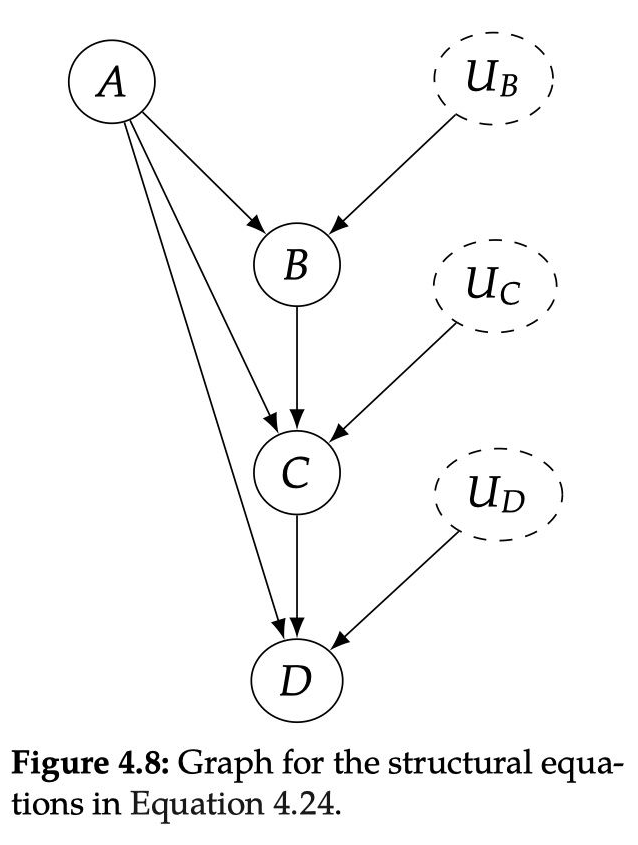
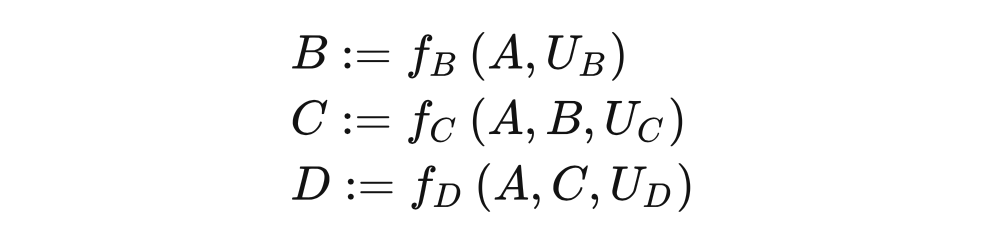

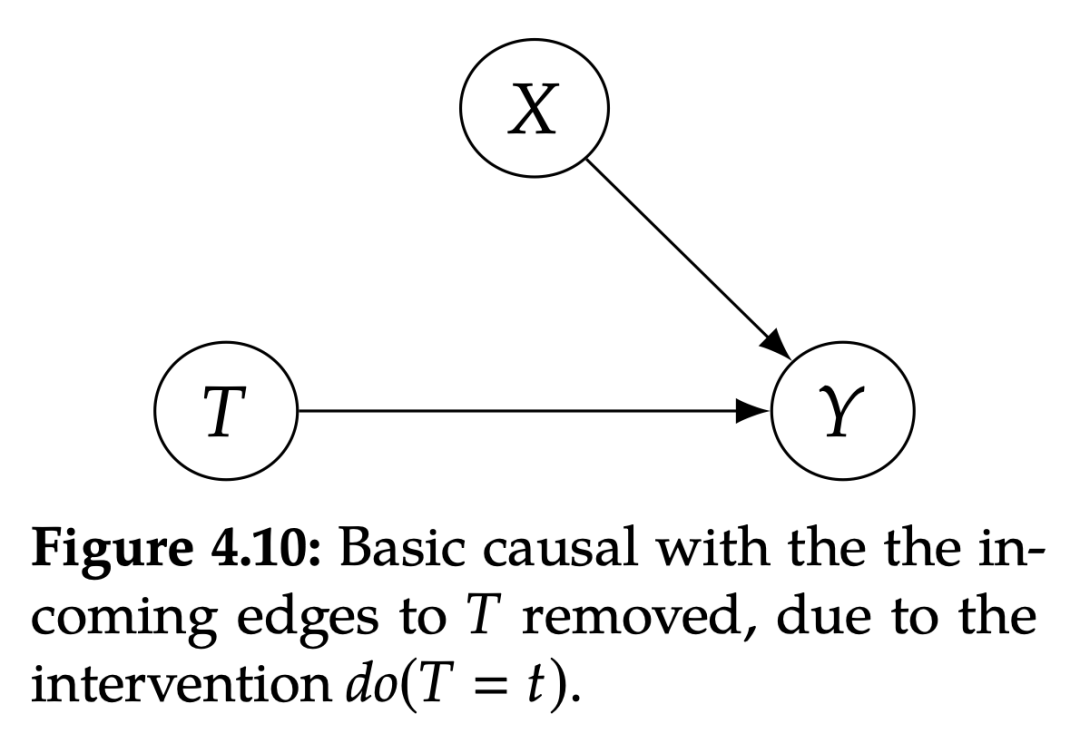
4.5.2 干预
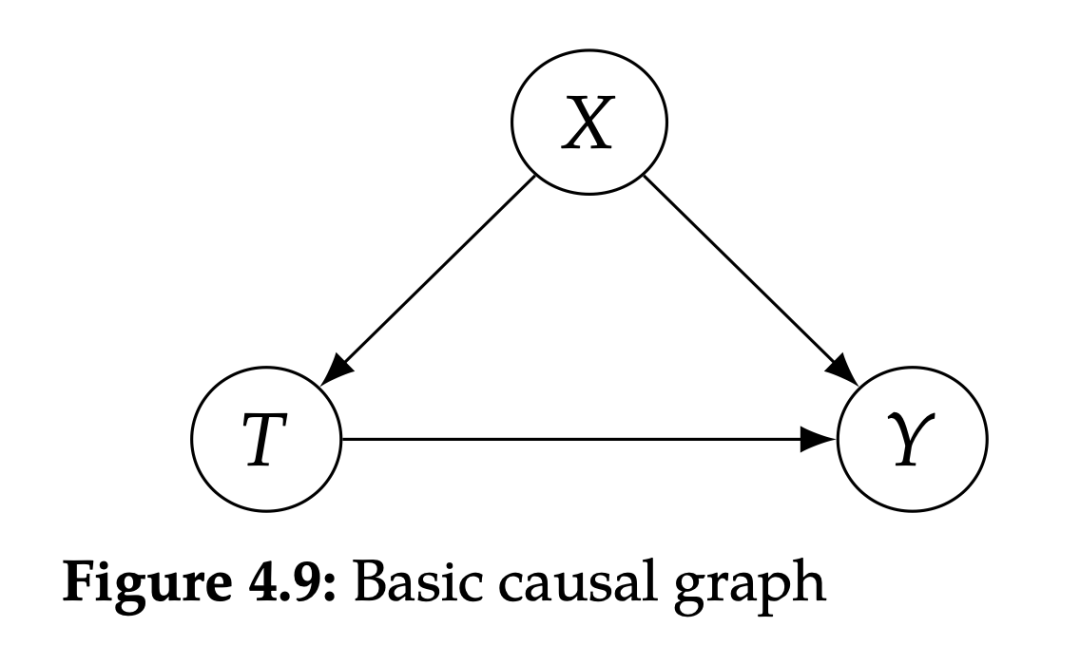
从 SCM 的角度来描述干预会非常简单。对 T 进行干预 相当于将 T 的结构等式替换成 。例如,图 4.9 对应的 SCM 为:
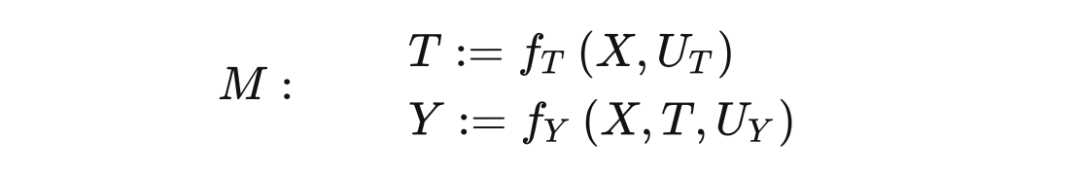
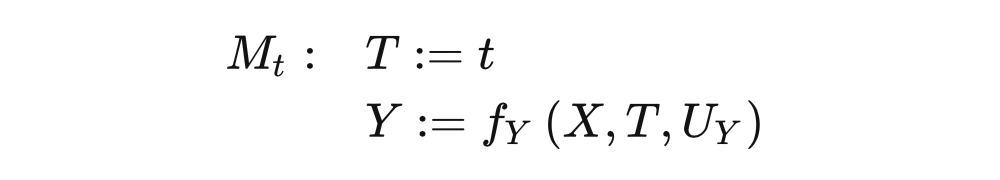


参考文献
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧


