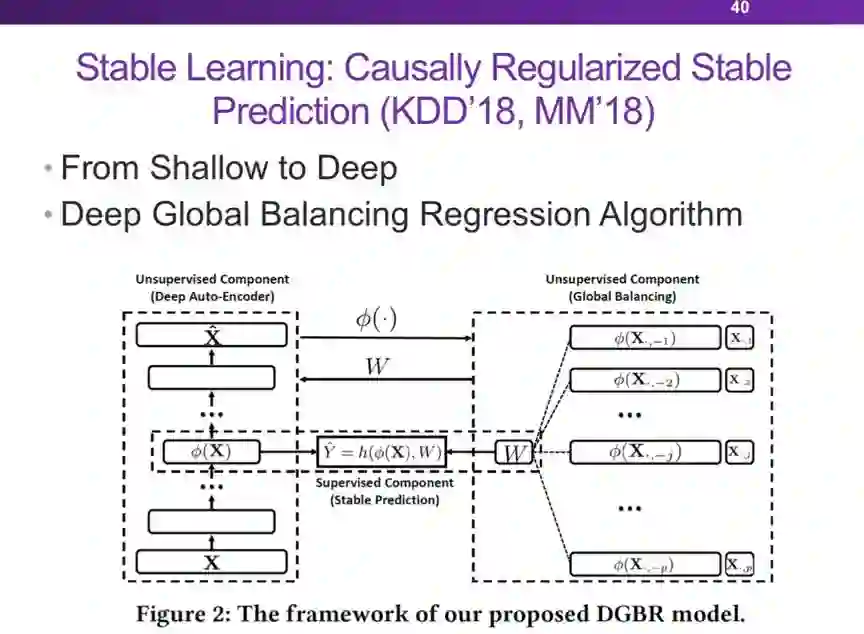
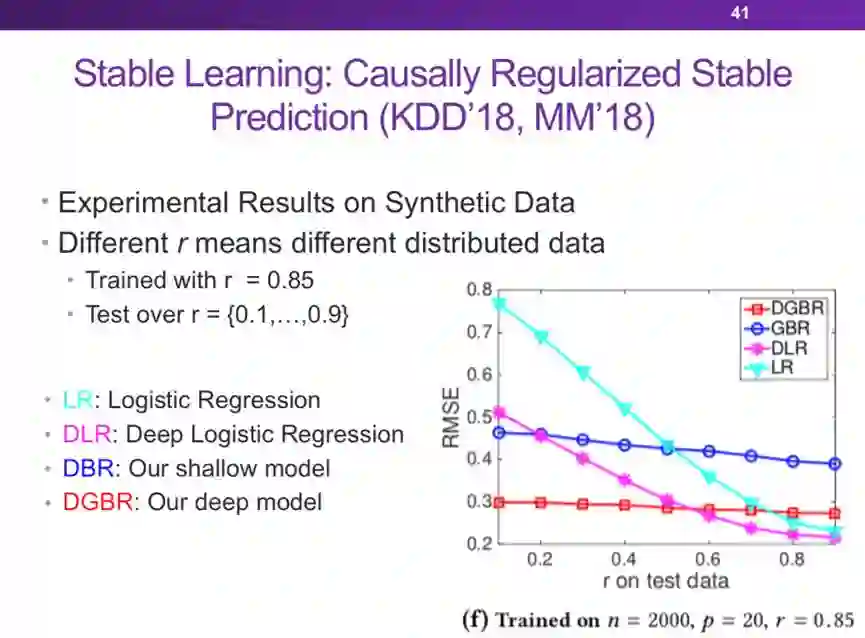
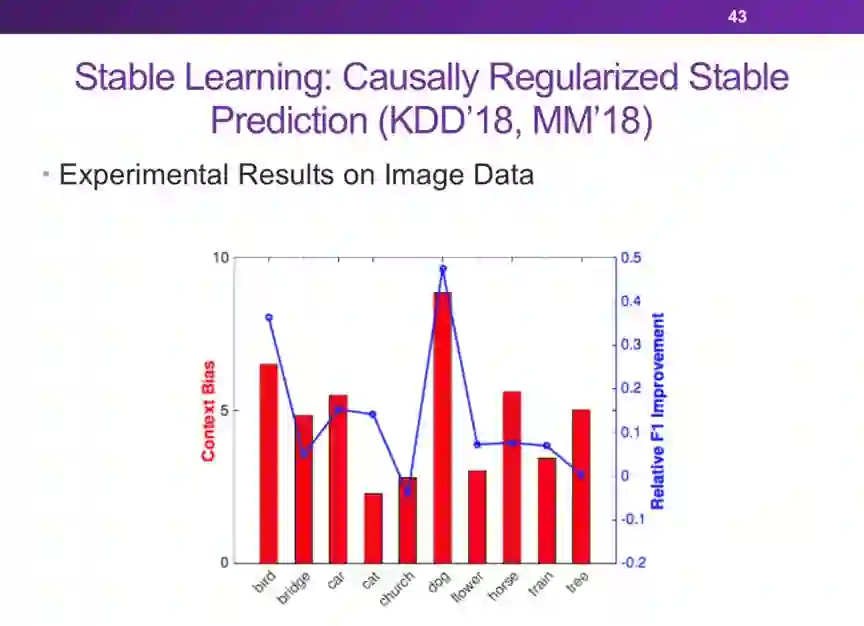
机器学习的可解释性:因果推理和稳定学习

分享嘉宾:况琨 浙江大学 助理教授
编辑整理:有感情的打字机、闫建飞
内容来源:将门线上直播178期
出品平台:将门、DataFun
注:欢迎转载,转载请留言。

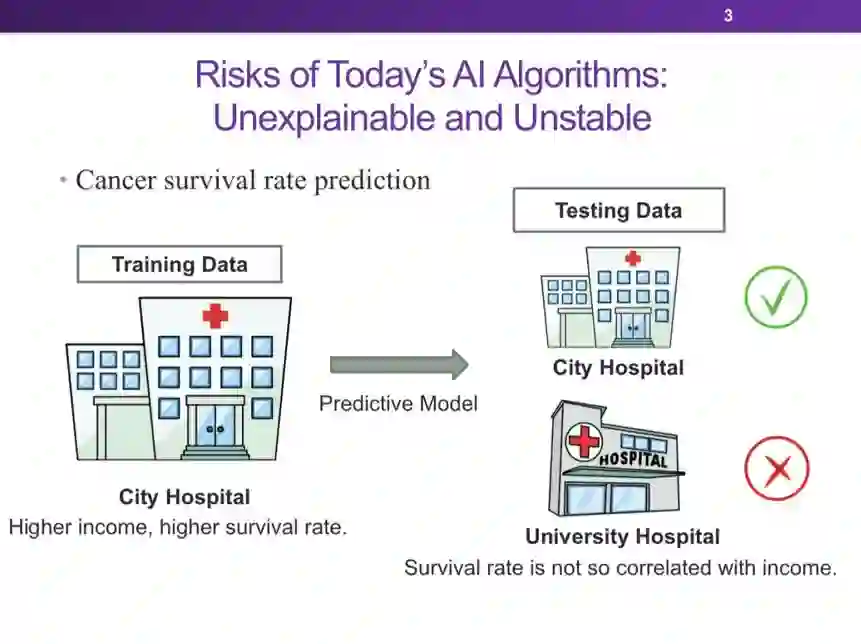


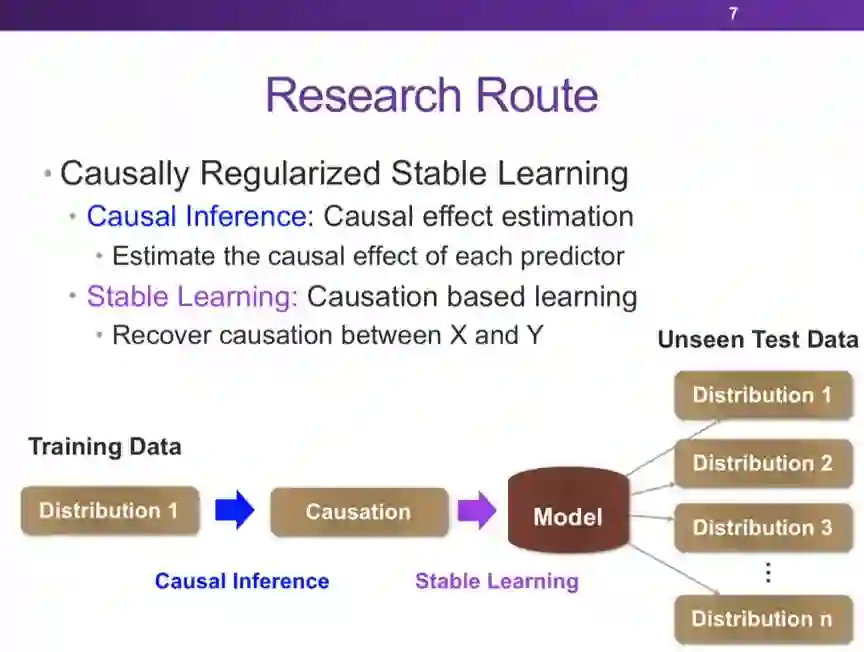

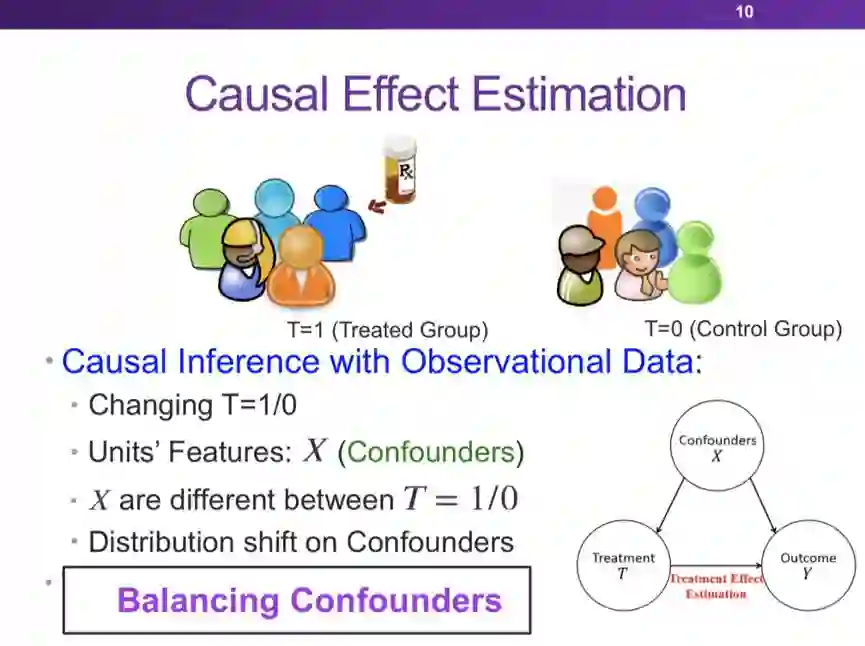


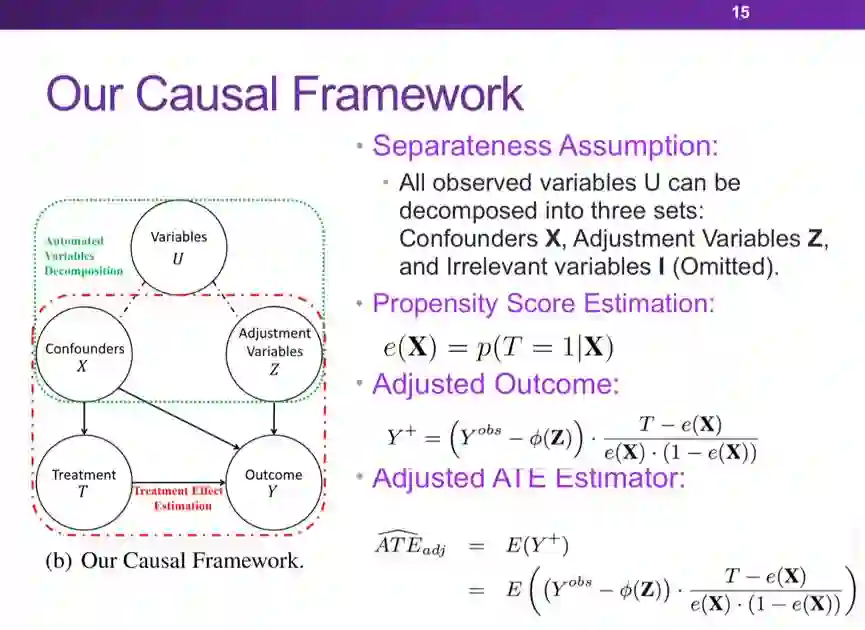


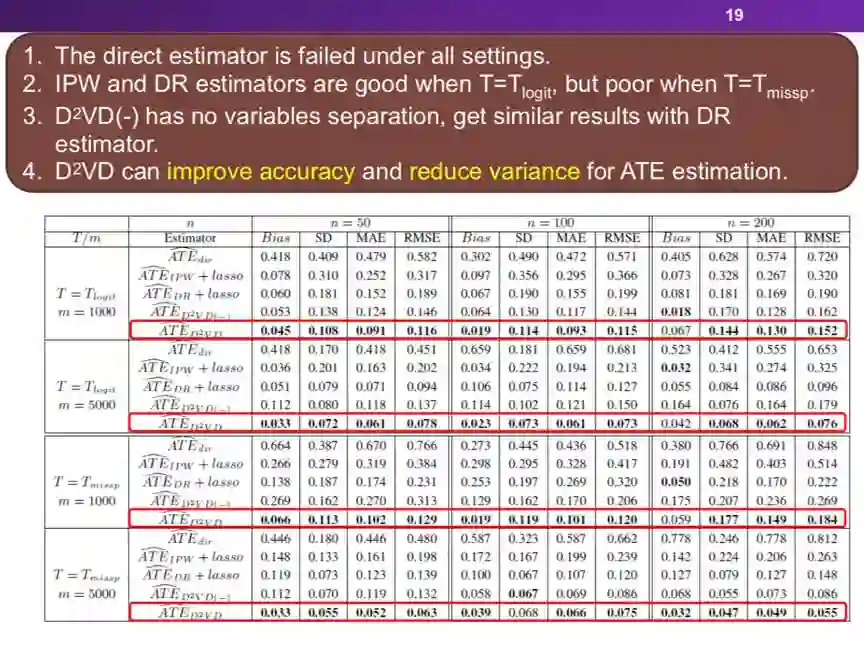

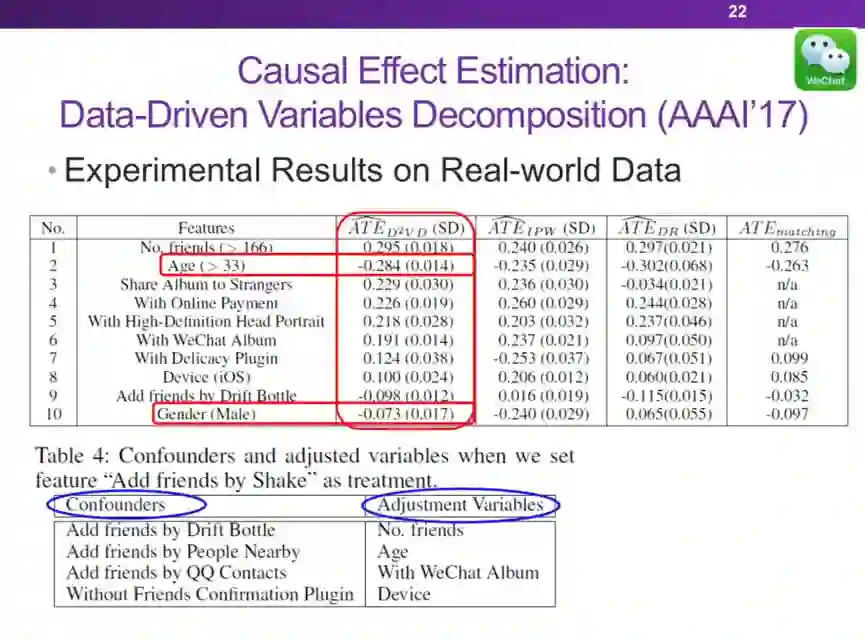


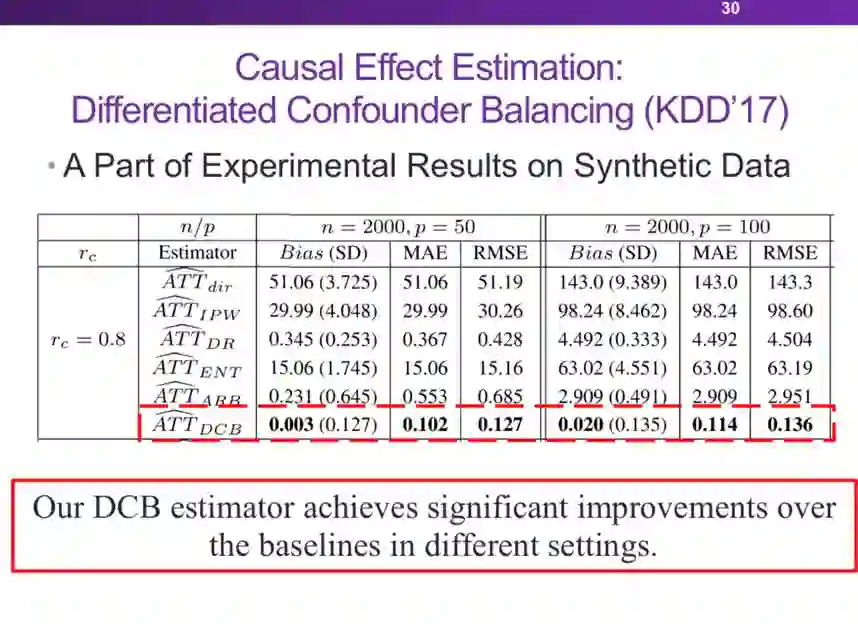



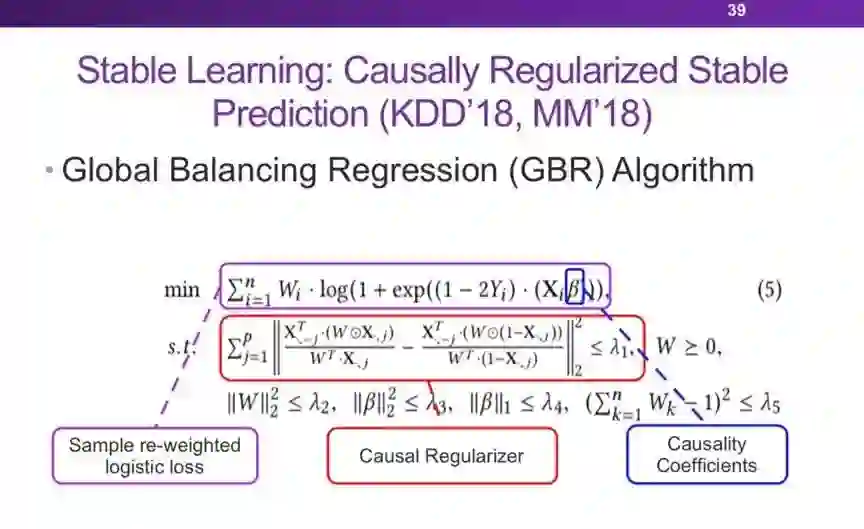



登录查看更多
相关内容
【2020密歇根大学论文】基于学习的序列决策算法的公平性综述论文,Fairness in Learning-Based Sequential Decision Algorithms: A Survey
专知会员服务
22+阅读 · 2020年1月15日
A Survey of Reinforcement Learning Techniques: Strategies, Recent Development, and Future Directions
Arxiv
80+阅读 · 2020年1月19日
Arxiv
4+阅读 · 2018年5月24日




相关VIP内容
【2020密歇根大学论文】基于学习的序列决策算法的公平性综述论文,Fairness in Learning-Based Sequential Decision Algorithms: A Survey
专知会员服务
22+阅读 · 2020年1月15日
相关资讯
相关论文
A Survey of Reinforcement Learning Techniques: Strategies, Recent Development, and Future Directions
Arxiv
80+阅读 · 2020年1月19日
Arxiv
4+阅读 · 2018年5月24日