因果推断在推荐系统中的应用总结
一、摘要
最近几年,因果推断开始被广泛运用在生物、金融、计算机领域中。在推荐系统领域,相比于更关注数据和目标之间的关联(assosiation)的监督学习,因果推断更关注数据和目标之间的因果(causalation),这让模型能具有更好的泛化性,所以有了越来越多的在推荐系统中运用因果推断的研究。本文并非综述性文章,主要目的是通过举例论证,总结因果推断的基本概念和使用方法,以及它在推荐系统的应用,回答以下问题:
什么是因果推断(causal inference)?
因果推断的的难点是什么?
如何在结果因果框架(SCM)下做因果推断?
如何在推荐系统里使用因果推断?
如果想要了解更理论或形式化的定义,可自行查阅笔者附在”参考“中的资料。
二、什么是因果推断?
1.因果不等与关联
在数据分析的场合,我们很容易混淆因果和关联的概念,所以在介绍因果推断前,辨析下两者的区别,以便加深对”因果“的理解。
贝叶斯网络和因果推断结构因果框架的创始人Pearl曾经说,“All the impressive achievements of deep learning amount to just curve fitting”,虽然有一丝嘲讽的意味,但是笔者觉得,如果说监督学习是一种curve fitting,倒也没有错,因为监督学习在刻画数据和目标之间的关联(association),但这并不是因果(causation),那么他们的区别是什么呢?笔者在这里举了两个例子,能够比较直观的感受两者的区别。
例子1:一个高压锅有一个精准的压力计,通过不断的调整高压锅中的压力(随机变量Y),我们得到不同的压力计数值(随机变量X),通过一组观测
,我们就能找到Y和X之间的关联关系,但是通过这组数据我们并不知道是X导致了Y,还是Y导致了X,不过根据我们的常识,我们知道改变Y,能导致X改变,但是反过来不行,Y导致了X这种单向关系是因果关系。
例子2:科幻小说《三体》里有个经典农场主假说,农场主每天11点给农场的火鸡喂食,火鸡有一名科学家在经过一年的观察后,宣布它发现了自己宇宙中的铁律:每天11点,就有食物降临。当它宣布这个定律的早晨,食物没有降临,农场主把它们抓去杀了。可惜的是,火鸡科学家发现的只是关联而非因果。
2. 因果推断是量化因果效应的方法
在因果分析领域,主要有两类问题:因果发现(causal discovery)和因果推断(causal inference)。因果发现不在本文的探讨范围内,因果推断是量化因果效应的一种方法,比如例子1中,我们知道高压锅中的压力值和压力计的数值存在因果关系,因果推断则是想要量化“改变高压锅的压力,能多大程度影响压力计的数值”。
我们可以用更形式化的定义([1])来描述关联和因果,通常用如下两种方式来表达:
1. 在机器学习领域,我们经常关注的是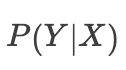
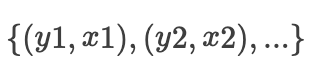
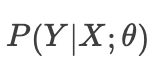
2. 在因果推断里,我们关注的是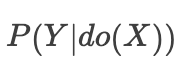
若想要了解更形式化的定义,请参考[1];笔者也强烈推荐参考[2]中的例子。
三、因果推断的难点是什么?
在第二节中,笔者提到,我们需要主动地获取数据来预估
例子3:该例子引用自[3],医院有两种药Treatment A和treatment B,有两个350个患者组成的实验组,其中,第一个实验组有年轻人(Young)270名,老年人(Older)80名,第二个实验组有年轻人87名,老年人263名,两个组的患者分别服用两种药,第一个实验组有234名年轻人被治愈,55名老年人被治愈,第二个实验组有81名年轻人被治愈,192名老年人被治愈。在这个数据中,最奇怪的点是,从观测数据中的overall部分可以看到,treatment A的治愈率高于treatment B,但是从年轻人和老年人的分层数据来看,treatment A的治愈率均低于treatment B。
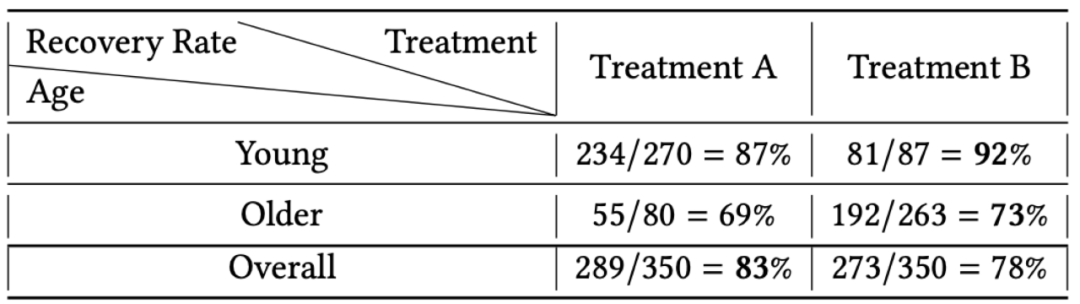
例子3中,之所以存在奇怪的悖论,是因为存在同时影响自变量(或原因)和因变量(或结果)的因素,这被称为cofounder。在这里例子中,因为年轻人比老年人更愿意吃treatment A,另外,年轻人的恢复力更强,所以无论吃什么药,治愈率都更高,所以age是同时影响了分组和治愈率的cofounder。在现实生活中,cofounder更加复杂,甚至无法被穷举,我们只能依靠主观经验来发现它,这就导致了很难消除cofounder来正确地估计因果效应。
当然,也存在成本非常高但是直接有效的量化因果效应的办法,那就是随机实验([1]),简单来说,如果能通过完全随机的抽样,让服用Treatment A和Treatment B的患者的特征在统计意义完全相同,比如两个组中的不同Age占比完全相同,则通过Overall计算出来的治愈率就能反应出Treatment A和treatment B的好坏了。
例子4:在推荐系统中,AB实验就是大家最熟悉的关于随机实验的例子,我们可以从因果推断的角度理解AB实验。在AB实验中,一般要求随机分配到实验组和基准组的用户画像在统计意义上完全一致,这样我们才可以度量出实验组上的策略的影响。
所以,cofounder是导致因果推断困难的原因之一,很多研究都是关于如何消除cofounder的影响(adjust cofounders),虽然随机实验是非常直接准确的解决方案,但奈何成本太高,在很多场合都并不适用。
四、如何在结构因果框架下做因果推断?
既然做随机实验([1])的成本很高,如何基于已观测到的数据分析因果推断呢?也就是如何计算
对于如何理解结果因果框架,笔者在这里引用一篇外国博主的好文(原文[4],知乎上的翻译[7]),这里简单的总结下:
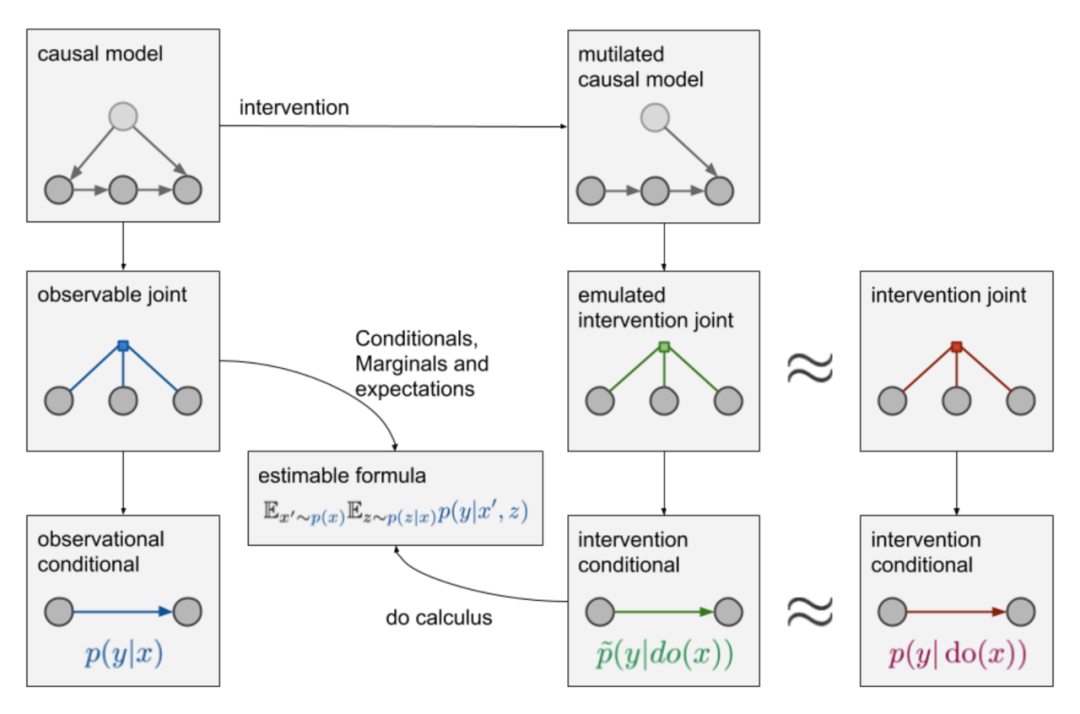
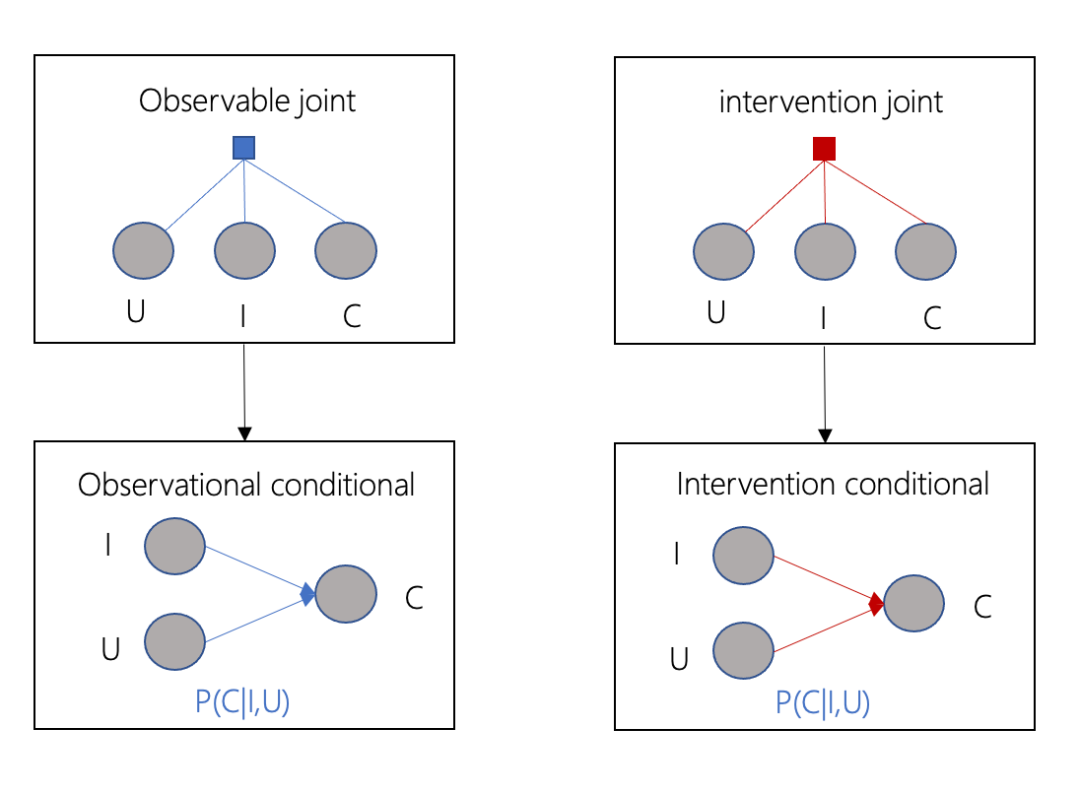
对于监督学习而言,我们根据多个变量的联合概率分布(observable joint,图中的三个圆点表示X,Y,Z三个随机变量)获得观测数据,求解模型
,学习其参数。
同理,如果我们能够根据干扰后的联合概率分布(intervention joint)获得观测数据,我们也能用监督学习的方式求解,但是实际上,我们并没有这样的数据,那么,基于人工经验,创造表示变量之间因果关系的causal graph,如果因果图比较正确,通过主动干预,我们能获得与intervention joint近似的联合概率分布(emulated intervention joint),从而得到
的近似计算结果
emulated intervention joint也只是我们假设出来的分布,我们仍然没有具体的数据,但是引入causal graph的好处是,基于这个先验知识,在满足一定假设时,我们就能够使用do-calculus[6],在仅有observable joint的情况下,求解
,也就得到了
的近似解。
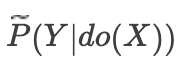
五、如何在推荐系统里使用因果推断?
最近几年,因果推断的技术被更多的用于推荐系统中,在这一节,笔者主要想讨论下,在推荐系统的消偏领域(debias),如何使用结构因果框架来做因果推断,来达到消偏的效果。
偏差广泛存在于推荐系统中([8]),比如样本选择偏差(Selection bias)、流行度偏差(popularity bias)、曝光偏差(exposure bias)等,笔者在例5中举了一个流行度偏差的例子。
例子5:以某短视频平台为例,头部创作者往往能获得更多的流量,而腰尾部创作者只能瓜分剩余的流量,这导致头部创作者相关的样本量占比远高于腰尾部创作者,在不考虑模型线上线下推断样本空间不一致的情况下,虽然短视频的曝光分布P(I)是符合平台现状的,但是对于单个用户U而言,其与短视频的联合概率分布P(U,I)也会更偏向于头部创作者,它会导致比较严重的马太效应,这其实不符合我们对去中心化的个性化推荐系统的期待。
笔者以论文《Causal intervention for leveraging popularity bias in recommendation》[9]为例,来分析如何使用因果推断来消除流行度偏差。
1.在短视频推荐系统里的典型场景是,给用户U展示短视频I,预估点击事件C发生的概率,它们三者构成了observable joint,推荐系统不断收集用户反馈,在观测到的数据上学习深度学习模型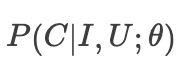
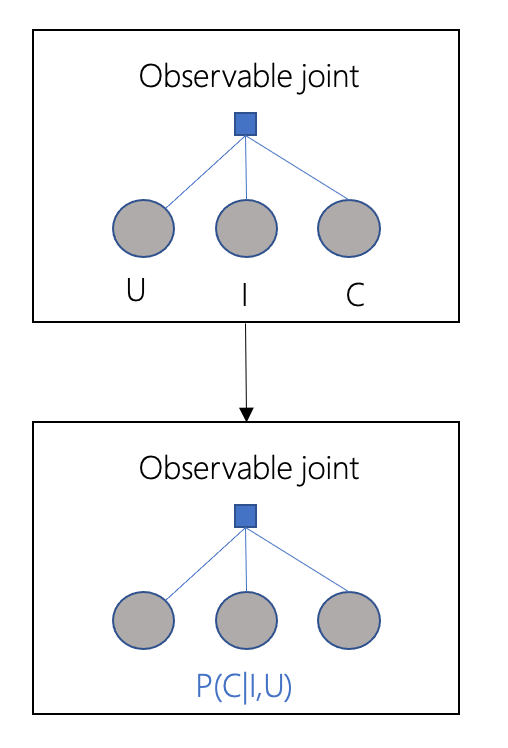
2.在第一步中,流行度(Z)没有被纳入联合概率分布,但它确实影响了数据收集的过程:一方面,热门的(Z)创作者创作的短视频(I)往往更受推荐系统的各个链路模型、策略的青睐而得到更多的曝光机会;另一方面,用户(U)也会因为从众心理,愿意看热门(Z)的短视频(I)。我们不禁想问,如果我们给用户展示一个他可能喜欢的非热门短视频,他会点击吗?当然,我们不可能按着用户的头说,“来,回到刚才,我们重新推荐一个,您看看喜不喜欢?“,为了回答这个问题,我们希望求解主动干预短视频(I)的曝光时的概率分布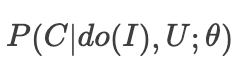
3.虽然我们无法直接获得干预后的分布(intervention joint),进而求解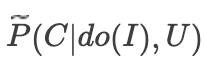
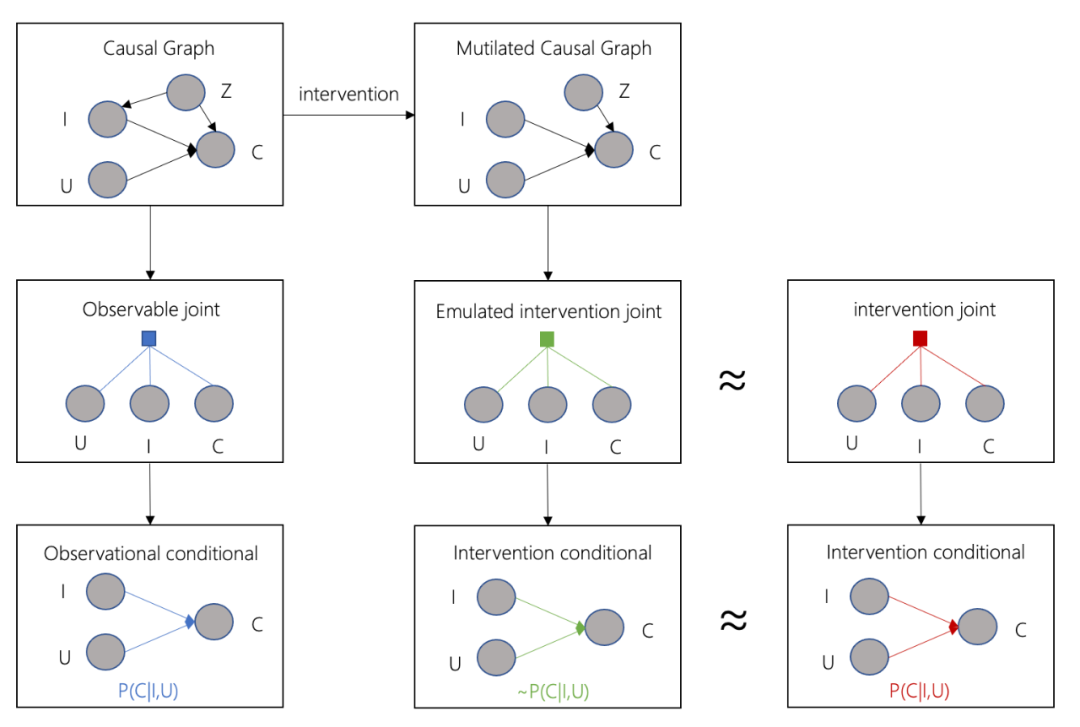
4. 第三步中近似解也不能被直接求解,但是通过引入causal graph,我们就能够使用do-calculus[6]的方式,获得仅用已知的条件概率分布来计算
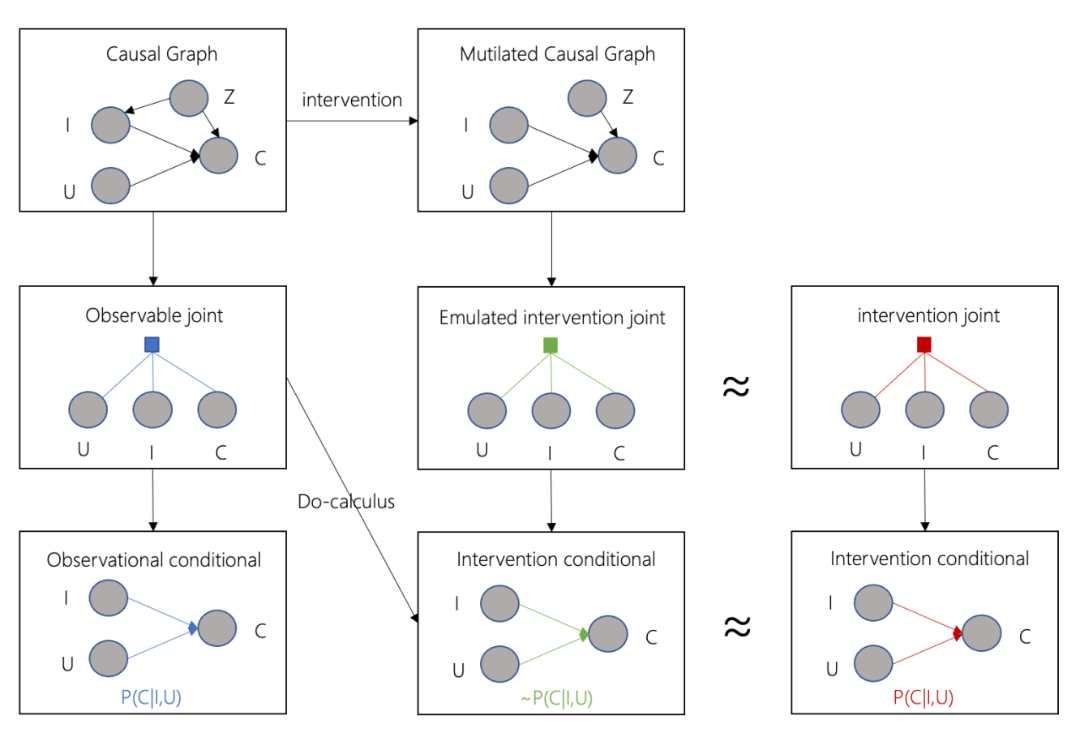
当然,笔者只是分析了因果推断的某一个使用场景,因果推断的想象空间远不止如此,想更多了解这个领域的读者可以看一下综述性的文章([3])。
六、总结
本文主要是通过举例论证,尝试回答因果推断的一些问题,自知不够全面,当做抛砖引玉之用:
因果推断用于发现和度量变量之间的因果关系。
Cofounder的存在是导致因果推断困难的原因之一。
在推荐系统中,结合结果因果框架做因果推断,可以有效缓解一些消偏领域常见的偏差。
更多关于推荐算法与因果推断相结合的工作可阅读最新综述 | 基于因果推断的推荐系统。
七、参考
Causal Inference,CMU, https://www.stat.cmu.edu/~larry/=sml/Causation.pdf
Causal Inference 2: Illustrating Interventions via a Toy Example,https://www.inference.vc/causal-inference-2-illustrating-interventions-in-a-toy-example/
Yao, L., Chu, Z., Li, S., Li, Y., Gao, J. and Zhang, A., 2021. A survey on causal inference. ACM Transactions on Knowledge Discovery from Data (TKDD), 15(5), pp.1-46.
ML beyond Curve Fitting: An Intro to Causal Inference and do-Calculus,https://www.inference.vc/untitled/
Judea, P., 2010. An introduction to causal inference. The International Journal of Biostatistics, 6(2), pp.1-62.
Tucci, R.R., 2013. Introduction to Judea Pearl's Do-Calculus. arXiv preprint arXiv:1305.5506.
告别曲线拟合:因果推断和do-Calculus简介,https://zhuanlan.zhihu.com/p/37423369
Chen, J., Dong, H., Wang, X., Feng, F., Wang, M. and He, X., 2020. Bias and debias in recommender system: A survey and future directions. arXiv preprint arXiv:2010.03240.
Zhang, Y., Feng, F., He, X., Wei, T., Song, C., Ling, G. and Zhang, Y., 2021, July. Causal intervention for leveraging popularity bias in recommendation. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval (pp. 11-20).
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。

