子词技巧:The Tricks of Subword
被吃掉的超链接还请点击原文,文中如有错误或不足之处还请指出,感谢!

最近读到篇关于 NLP 中 Subword(子词)挺有意思的论文,BPE-Dropout: Simple and Effective Subword Regularization,对 BPE 技巧进行 dropout 改进,就获得很大提升。
因为一般神经网络做 NLP 需建立词向量表,每个不同词都对应一个不同向量,即使两个词看起来相近,但在为经过训练的词向量表中可能没有任何关系。这就导致一个单词因为不同形态会产生各种不同词,特别对于某些形态学(Morphology)丰富语言(比如德语)尤为明显,这就造成了大词汇量问题。
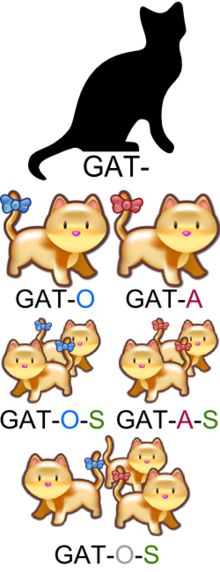
而大词汇量又带来两个问题:
稀疏问题,某些出现频率低的词得不到充分训练;
过大计算量,对计算资源的浪费。
为解决这个问题,就要用到子词技巧了。什么是子词,就是将一般的词,比如 unigram 分解成更小单元,uni+gram,而这些小单元也有各自意思,同时这些小单元也能用到其他词里去。打个好理解的比方就是,一个会背单词的童靴,一般都会将单词分成词根词缀这些更小组成部分来背,而不是死背单词,这样可以使需要背的东西大大减少。因此同理通过将词分解成子词,也能将模型词汇量大大降低。
子词技巧可大致分成两个大的方向,一是如何分解成子词,二是如何在训练中用。
首先说如何将词分解成子词,因为不同角度可以有不同方案,所以也就产生了几种主流方法。
Byte Pair Encoding (BPE) 法
WordPiece 法
Unigram Language Model
关于三种方法,Edward Ma 在其博客 3 subword algorithms help to improve your NLP model performance 有详细介绍,这里就提提我的理解,还有对里面的补充。
值得一提的是,现在主流的几种方法结果和语言学都没有太大的关系,反而都是统计学解决思路。
BPE 法

BPE 很早就有了,最早只是用于压缩的算法,而在 Neural Machine Translation of Rare Words with Subword Units 论文中在 NLP 领域得到推广。目前最流行方法,简单有效。
具体获得子词表的步骤是:
准备语料,分解成最小单元比如英文中26个字母加上各种符号,这些作为初始词表;
根据语料统计出现相邻符号对的频次;
挑出频次最高符号对,比如说 t 和 h 组成的 th,加入词表,训练语料中所有该相邻符号对融合(merge),这里即所有 t 和 h 都变成 th;
重复 2 和 3 操作,直到词表中单词数达到设定量,比如 32000。
WordPiece 法
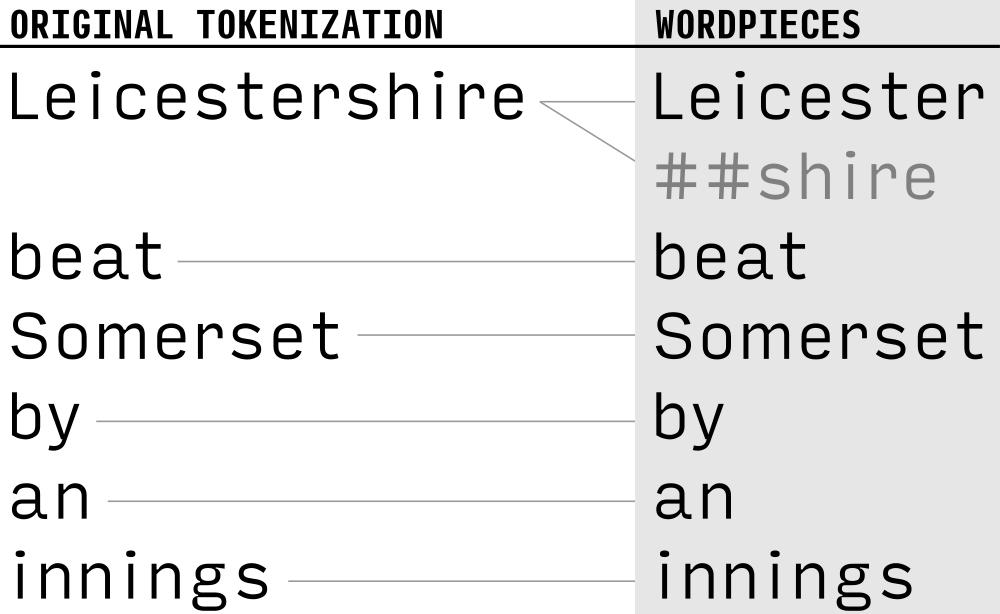
在12年神经网络方法尚未流行的时候,在 Japanese and Korean Voice Search 就有提出。整体和 BPE 法相同,唯一不同在第2步,BPE 是统计频次,而 WordPiece 则是获得似然(Likelihood),之后挑选最大似然的词对加入词表,完成 merge。
关于如何获得似然,先将整个语料按当前词表分解,接着在分解后的语料上训练语言模型,对整个语料获得一个似然值。之后在已有的词表上组合词对,获得新的词表,重新训练语言模型,对整个语料获得一个似然值。对比所有词对候选,挑选其中语言模型似然值提升最大的词对,将其正式加入词表。不断进行此操作,直到整个词表量达到设定值。
需详细解释的一点是关于训练细节,也是最开始我比较迷惑的地方。因为加入每个可能的词对都需重新训练语言模型,这样所要的计算资源会很大。读原文会发现,作者对这块特意进行了解释,通过以下策略来降低计算量:
只测试语料中出现的词对;
只测试有很大可能(高优先)是最好词对的候选;
同时测试几个词对,只要它们互不影响;
重训语言模型(并不需要是神经网络型),只重新计算受影响的部分。
因为 WordPiece 是谷歌内部库,所以相信谷歌也肯定设置了其他策略来改进 WordPice 方法。
上述两种方法都是增量法,即先初始化一个词表,再建立一个评估标准,每次挑最好的词对加入词表。而下来介绍的 Unigram Language Model 则可以当作是减量法。
Unigram Language Model 法
在论文 Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates 中提出。
关于此方法与其他方法的异同,首先它与 WordPiece 一样都用到语言模型来挑选子词,而不是像 BPE 统计频次,然后它和 BPE 以及 WordPiece 从表面上看一个大的不同是,前两者都是初始化一个小词表,然后一个个增加到限定的词汇量,而 Unigram Language Model 却是先初始一个大词表,接着通过语言模型评估不断减少词表,直到限定词汇量。
具体操作是:
先建立一个足够大的种子词表,可以用所有字符的组合加上语料中常见的子字符串(用 Enhanced Suffix Array 来枚举)。对于种子词表,也能用 BPE 法来生成。
固定词表,用 EM 算法来最优化当前词表在语料上的概率;
之后计算每个子词的 loss,对应的 loss 相当于该子词有多大可能使总的 loss 降低;
接着按照每个子词 loss 大小来排序,保留最大一定比例(比如说80%)的子词。
不断重复2到4,直到词表量减少到限定范围。
在论文中除了这个 Unigram Language Model 获得子词的方法,作者还提出了一套 Subword Regularization 的针对子词的训练正则法,这也是开头提到的如何在训练中用。
在介绍正则法之前,需要先提一下一般训练是如何融入上面的分词法。比如 BPE,因为已经获得一份词表,所以在训练时,先按照子词表将训练数据拆开,预测时也可以是预测子词而不是整词,最后按照 BPE 词表还原出整词就行。比如说训练时先把 unigram 拆成 uni## ##gram,这样获得结果时只需找到##符去掉就行。
子词正则
相对于上述 BPE 这样拆分子词确定了的训练,子词正则在不同情况用不同拆分方法来拆分一个词。因此在训练中,作者们会用 Viterbi(维特比) 算法来对当前如何分词进行采样,之后获得分完的子词。
这个方法给训练的分词过程带来了随机性,结果表明相比起只用一种方案的确定性分词法,子词正则能够获得很大的提升。但同时也正如看到的,子词正则加上 Unigram Language Model 法过于复杂,所以应用难度也相应增大,不像 BPE 应用广泛。
BPE dropout
该方法非常简单,采取和子词正则相同思路,对 BPE 算法训练做了些改进,加入了一定的随机性。具体在每次对训练数据进行处理分词时,设定一定概率(10%)让一些融合不通过,于是即使是相同词,每次用 BPE dropout 生成出来的子词也都不一样。

图中绿色是每次融合字符对成功的,而红色则是 dropout 掉的。
通过该方法,可假定模型通过不同的分词方案,来获得对整词更好更全面的理解,之后的分析实验也表明了这一点。
最后在实际翻译任务的评估发现,该方法虽然简单,但却能够带来很大的提升,比起 Subword Regularization 还要大。
子词实战
要用上面这些子词技巧,最简单的方法就是直接用谷歌的 SentencePiece 包,其中除了 BPE 和 unigram language model 法外,还支持字符和词级别分词。当然,BPE 也可以用最经典的 subword-nmt 包。
而 WordPiece 则是谷歌内部的子词包,没对外公开,BERT 最初一版用的就是 WordPiece 分词。
本文转载自公众号:安迪的写作间,作者:Andy
推荐阅读
T5 模型:NLP Text-to-Text 预训练模型超大规模探索
BERT 瘦身之路:Distillation,Quantization,Pruning
Transformer (变形金刚,大雾) 三部曲:RNN 的继承者
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。


