从语言学角度看词嵌入模型

本文为 AI 研习社编译的技术博客,原标题 :
Moving beyond the distributional model for word representation.
作者 | Tanay Gahlot
翻译 | 乔叔叔
校对 | 酱番梨 整理 | 菠萝妹
原文链接:
https://towardsdatascience.com/https-medium-com-tanaygahlot-moving-beyond-the-distributional-model-for-word-representation-b0823f1769f8
注:本文的相关链接请点击文末【阅读原文】进行访问
从语言学角度看词嵌入模型

在任何一个基于机器学习的自然语言处理(NLP)流水线中,词的向量化是其中典型的一个步骤,因为我们不能直接给计算机“喂单词”。在词的向量化过程中,我们为一个单词指定一个N维的向量,用来表示它的词义。结果,这成了处理过程中最为重要的一个步骤之一,因为一个“坏的”表示会导致失败以及为接下来的NLP任务带来不愿看到的影响。
在词向量化的最常用的技术之一就是词的分布式表示模型。它基于的一个假设是一个词的意思能够从它所在的上下文中推断出来。大部分深度学习论文使用基于该分布式理论而来的词向量,因为它们是“任务普适”(它们不是针对特定任务)而且“语言普适”(它们不是针对特定语言)。不幸的是,分布式方法并不是词向量化任务的魔效武器。在本博文中,我们会指出这个方法的一些问题并提供一些潜在的解决方案,以改善词向量化的过程。
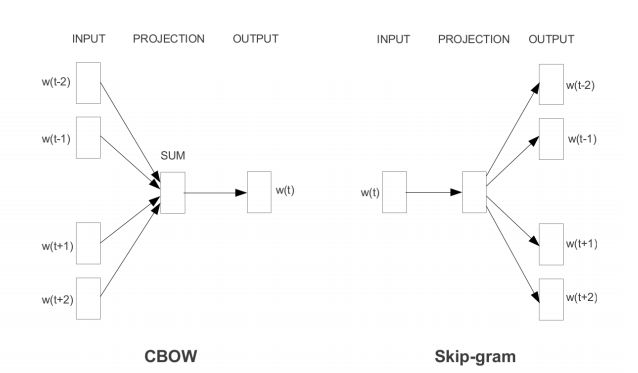
分布式表示模型有以下的问题,让人感觉非常痛苦:
罕见词:对于在语料中出现频率较低的词,它们无法通过分布式表示学习得到一个很好的表示。
多义混同:它们将一个词的所有词义混成一个表示。例如,单词“bank”,在英文中可以指“河岸”或者是“金融机构(银行)”。分布式模型却将所有的这些词义混合在一个表示中。
形态缺失:在表示学习的时候,它们并没有考虑一个单词多种形态。比如,“evaluate”和“evaluates”具有相似的意思,但是分布式表示模型却将它们视为两个不同的单词。(译者注:在英语中,一个单词可能有多种形态,特别是动词,有时态、人称、主动被动等对应的不同形态。在本例中evaluates是evaluate的第三人称单数的一般现在时的形态。)
幸运的是,为了解决这些问题,大家进行了非常广泛的研究。大致上,这些解决办法可以分为3个主要类别。我们将会按照下面的顺序一一介绍:
形态敏感嵌入
在词嵌入中,将语言或功能约束进行增强。
多词义处理
形态敏感嵌入
这些技术在学习词嵌入的时候,将词的形态进行了考虑。Fasttext就是这种技术的一个典型代表。它将一个单词表示成了n-grams(n元模子)字符的汇总。例如单词where就可以表示成
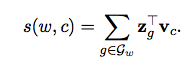
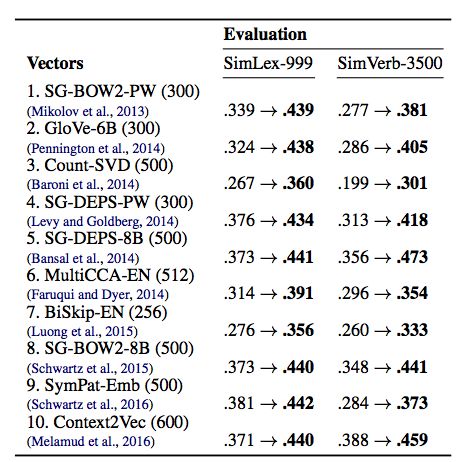
在使用这种方法(下表的sisg)对一些词汇形态丰富的语言,比如德语(De)、法语(FR)、西班牙语(ES),俄语(RU)和捷克语(Cs),进行语言建模的时候,经评估,相较于没有使用预训练词向量的LSTM,以及使用了预训练词向量却没有相关词根信息的LSTM模型(下表的sg),效果都有了改善。
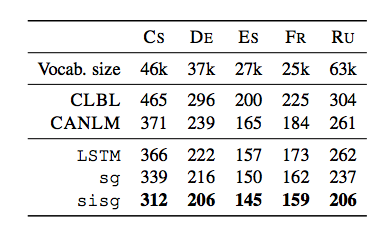
而且,既然fasttext将单词表示为n元字符(n-gram)的组合,因此它就能为那些语料库中从来没有出现过的词提供嵌入。在一些领域如生命科学领域,由于词汇表非常有限(长尾现象),语料中大部分的单词都归入到未知类别中,该技术就显得尤其有用。
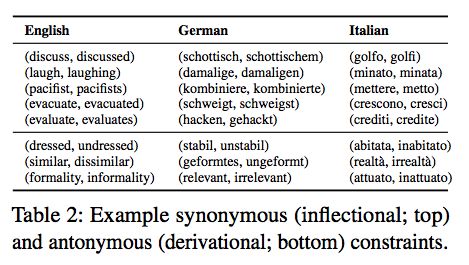
Morphfitting提供了另外一个技术选项用来将词的形态输入到词嵌入模型中。在这项工作中,他们用“相吸相斥”(Attract-Repel)方法来“后处理”(post-process)词嵌入,该方法“吸引”曲折形态(通过词的形式变化来表达有意义的句法信息,比如动词时态,却不改变词义),而“排斥”派生形态(新形式的单词出现同时词义也发生迁移变化)。在下一部分我们会详细讨论“相吸相斥”方法。
通过注入语言形态学的约束,Morphfitting在SimLex和SimVerb两个数据集上的相关系数评估中都超过了下表给出的10个标准嵌入模型。
在词嵌入中,将语言或功能约束进行增强
另外一类词空间定义的方法是在词嵌入的后处理中进行语言/功能约束。在上一节中我们已经看到这类方法的一个例子—Morphfitting。在这一节,我们将会探索一下Morphfitting中使用的定义词嵌入的方法—相吸相斥法(Attract-Repel)。
相吸相斥法(Attract-Repel)是一种后处理技术,它根据语言约束将预训练的词嵌入进行进一步定义。例如,在Morphfitting中,语言约束是以两种集合的形式来表达,再次给出表格2如下:
表格的上半部分是“相吸集合”(译者注:由多个词义相同的单词对组成的集合),下半部分是“相斥集合”(译者注:由多个词义不同的单词对组成的集合)。利用这些集合,一个迷你批次就形成了,它可以用来优化下面的损失函数:
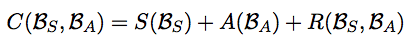
损失函数中的第一项对应的是相吸集合,第二项对应的是相斥集合。第三项则保留了分布式表示。而且,前面两项也会引入负样例,这是采用了PARAGRAM模型的主意。损失函数(又:成本函数)的前两项由下式给出:
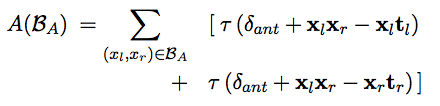
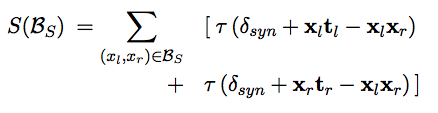
第三项由下式给出:
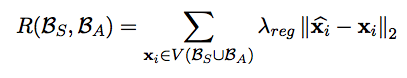
人们可以用“相吸相斥”法注入用相吸相斥集来表示的语言约束,比如“同义与反义”或者“曲折形态与派生形态”。而相应地,那些无法利用语言约束来表达的“相似性”或者“非相似性”,人们就不能进行词嵌入定义了。例如,不同“治疗”类型的关系,就无法用相吸相斥法来捕获。为了适应这样的功能关系,我们介绍另外一种方法叫做“功能改装”(Functional Retrofitting)。
在功能改装方法中,关系的语义学习与词空间的学习是同步进行的。而获得这一点的方法,主要是将相吸相斥法中的点积替换成一个优化学习过程得来的函数。
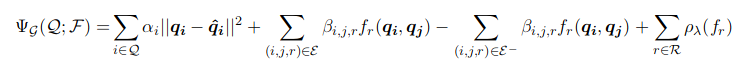
上式中的第一项保留了分布式嵌入,第二项和第三项则引入了知识图谱中的正向关系空间(E+)与负向关系空间(E-)(译者注:负向关系空间是没有在知识图谱中标明的关系的集合),最后一项在学习函数中执行正则化功能。
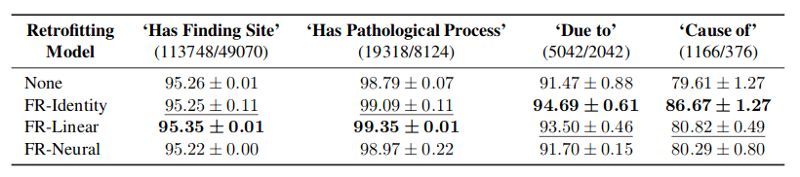
通过在国际系统医学术语集(SNOMED-CT)之上预测两个实体(i,j)之间的关系(r)而做的链路预测,功能改装方法的语义学习效果得到了验证。四种不同类型的功能改装方法分别对四种关系( “具有发现部位Has Finding Site”、 “具有病理过程Has Pathological Process”、 “诱因Due to”、 “症状Cause of”)进行了预测,其结果如下表所示:
更多关于功能改装的信息,你可以参考一篇由Christopher Potts写的优秀blog。如果你需要功能或语言约束来进一步定义你的词嵌入,请试用Linked Open Data Cloud上优秀的、具有互联关系的本体汇编。
上述的方法更新了各次汇报的词嵌入。如果你对定义整个词空间感兴趣,你可以用反向传播来这么做,正如Ivan Vulić和Nikola Mrkšić在EMNLP 2018论文中建议的那样(Adversarial Propagation and Zero-Shot Cross-Lingual Transfer of Word Vector Specialization)。
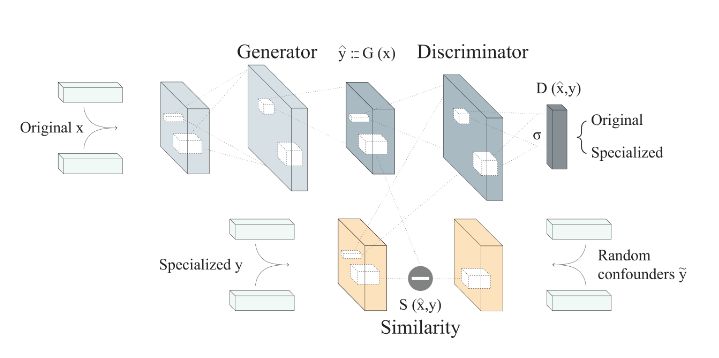
多词义处理
最后一类词嵌入定义技术是考虑词的多义性,或者是考虑词的上下文,或者是利用词义库。让我们先从前一类方法开始 – ELMO。
在ELMO中,词是基于上下文而被向量化的。因此为了能够用向量表达一个词,人们也需要指定某个词出现的上下文。与那些没有考虑上下文的向量化技术相比较,这个方法已经证明是非常有效的。下例比较了ELMO(biLM)和Glove的最近邻。

ELMO背后的基本思想是得出双向语言模型(BiLM)各个中间层的内部状态加权汇总以及最后一层的字符卷积网络表示。
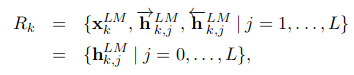
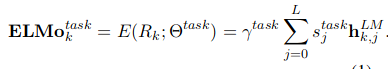
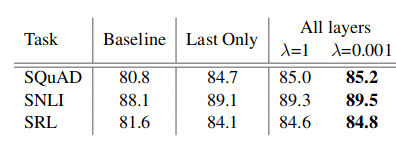
ELMO的词嵌入在三个下游任务SQuAD、SNLI和SRL中进行了测试,相较于基准它有了显著的改进。
更多关于ELMO的信息,请参考这篇AllenNLP写的博文。如果你想从分布式词表示中使用词汇资源来压缩语义,你可以用DECONF。在这个方法中,Mohammad Taher Pilehvar提出了一种机制来使用下面的优化标准,从而从分布式嵌入中压缩语义嵌入:
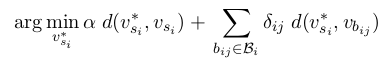
上式中,第一项保留了语义分布表示的近似,第二项会将词义嵌入向发生偏移的词义推得更加靠近一些。这个过程可以很清晰地用下图来描述。

偏移词集是用一个定制的Page Rank算法基于一个词汇术语(利用词汇资源创建而来)的语义网络计算而来的。
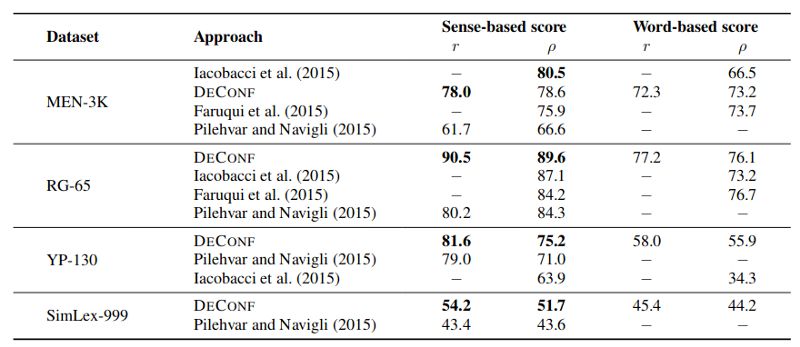
我们使用四个单词相似度基准方法分别做了皮尔森相关相关性和斯皮尔曼相关性评估,DECONF在绝大多数任务中都取得了最先进的结果,如下表所示:
结论
如果如处在没有足够训练数据来从头学习词嵌入的境况,我高度推荐使用上面提及的词表示的方法来取得一些百分比的改善。关于本话题更深入的讨论,我高度推荐Ivan Vulić在ESSLLI 2018中Word vector specialisation的课程。
想要继续查看该篇文章相关链接和参考文献?
长按链接点击打开或点击底部【阅读原文】:
https://ai.yanxishe.com/page/TextTranslation/1181
AI研习社每日更新精彩内容,观看更多精彩内容:
这5种计算机视觉技术,刷新你的世界观
迁移学习:如何将预训练CNN当成特征提取器
新手必看:深度学习是什么?它的工作原理是什么?
Python高级技巧:用一行代码减少一半内存占用
等你来译:
预训练模型及其应用
一文带你读懂线性分类器
(Python)3D人脸处理工具face3d
让你的电脑拥有“视力”,用卷积神经网络就可以!
独家中文版 CMU 秋季深度学习课程免费开学!
CMU 2018 秋季《深度学习导论》为官方开源最新版本,由卡耐基梅隆大学教授 Bhiksha Raj 授权 AI 研习社翻译。学员将在本课程中学习深度神经网络的基础知识,以及它们在众多 AI 任务中的应用。课程结束后,期望学生能对深度学习有足够的了解,并且能够在众多的实际任务中应用深度学习。

↗扫码即可免费学习↖
点击 阅读原文 查看本文更多内容↙

