CMU基于话题模型,用整篇文档解决词义消歧问题
词义消歧(WSD)的目的是将语境中有歧义的词映射到正确含义。WSD在自然语言处理(NLP)中是一个重要问题,不仅仅是因为它是一项先进的技术,而且它的发展对机器翻译、信息提取和检索以及回答问题等都有促进作用。
虽然目前我们可以粗略地区分监督式和无监督方法,但是监督式方法需要带有注释的训练数据,一般适用于词汇样本WSD任务,系统需要辨别有限的目标词汇。然而,监督式系统的性能在全字(all-word)的任务中是有限制的,因为完整的词典标记数据非常分散,并且难以获取。由于全字的WSD任务更难且应用场景更多,因此开发无监督的基于知识的系统是非常关键的。
于是,卡内基梅隆大学的研究人员们为全字的任务提出了一种新颖的基于知识的WSD算法,将整篇文本,而非词语所在的某句话,当做该词的语境。另外,他们还利用隐含狄利克雷分布(LDA)的变体,对整个WSD文档建模。

WordNet
大多数WSD系统使用词义库(sense repository)获得每个单词所有的意思。WordNet是英语语言综合词汇数据库,通常用作WSD系统中的词义库。它为语言中的每个实词(名词、动词、形容词、副词)提供所有可能的意义,并通过POS标签为它们分类。例如,“cricket”作为名词有两种可能的意思:“蟋蟀”、“板球”。作为动词,“cricket”还可以表示“打板球”。此外,WordNet还将同义词集合起来,生成同义词组(synset),每个synset还包含注释和示例。
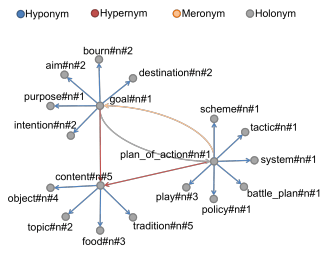
WordNet还包含了不同同义词组之间不同类型的语义关系信息,例如上下位关系、部分-整体关系等。图一展示了WordNet的一个子集,图中节点表示同义词组,线条表示它们之间的语义关系。
具体方法
在寻找解决方法之前,我们需要明确问题。研究人员们用具体的例子来阐释了这一问题,例如:
They were troubled by insects while playing cricket.
这句话中,每个实词(wi)的意思xi可以从词义库(yi)中找到ki个可能的意思。具体看图二。
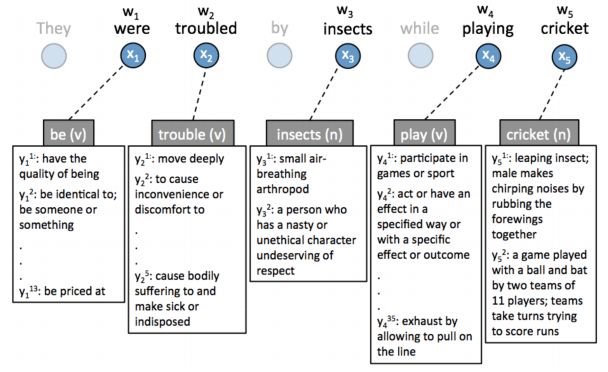
W5“cricket”一词,既能表示蟋蟀,又能表示板球。在这句话中,显然第二个解释更恰当。这样在文本中为每个实词找到正确的意思就是全字WSD的目标。
语义
接下来,研究人员介绍了他们所提出的方法的基本语义思想,以及它们是如何被纳入到模型之中的。
利用整个文档作为WSD的语境:使用隐含狄利克雷分布(LDA)建模;
同义词组中的一些单词比其他单词使用得更频繁:用非同一的先验为同义词组分布进行建模;
有些同义词组比其他同义词组使用得更频繁:使用逻辑正态分布对文章中同义词的比例进行建模。
文本语境
我们知道,一篇文章中的每个句子都是相互关联的。除了单词所在的句子之外,其他地方的单词也有助于词义消歧。例如:
He forgot the chips at the counter.
这里“chips”一词可以指“薯片”、“微型芯片”或者“扑克牌的筹码”。如果不看上下文,就很难消除歧义。在这篇文章中,出现了“赌场”、“赌徒”等词语,所以上文中的“chips”很有可能指的是“筹码”。
话题模型
为了用整篇文章作为某个词的语境,研究人员希望对此进行建模,而符合这一目的的只有话题模型(topic models),其中最基础的例子就是隐含狄利克雷分布(LDA)。
当有多义词出现时,LDA可以分辨出不同意思。但是由于WSD中的每个词是要展现出来的,而LDA无法做到这一点,所以研究人员对其进行了改进。
同义词组分布
由于不同的词典规模不同,研究人员在LDA的模型中添加了可交换的狄利克雷先验(Dirichlet prior)。在狄利克雷分布中,参数向量中的每个元素地位都相同。但是这在同义词组中却不适用。例如,表示“(比赛或履行的)目的地”的单词有:“goal”、“destination”、“finish”等。另外,其他词组中,有很多同义词的使用频率高于其他词。例如,表示“参与者或某项运动的老手”一词中,“player”就比“participant”更常用。所以,研究人员决定对同义词组的分布改为非统一先验(non-uniform prior)。
同义词组的文本分布
LDA模型使用狄利克雷分布作为文本的话题模型。在这一分布下,话题模型中的元素几乎是独立的,这就会导致模型做出不真实的假设,即现有的话题与另外的话题没有关联。不过,在这一项目中,同义词组是相互关联的。
例如,在表示“倾斜的土地”一词中,“bank”比“river”出现的频率更高。但是在表示“财务状况”的意思里,bank出现的频率就比其他词低了。于是,研究人员将各同义词组之间的联系用逻辑正态分布(logistic normal distribution)表示。
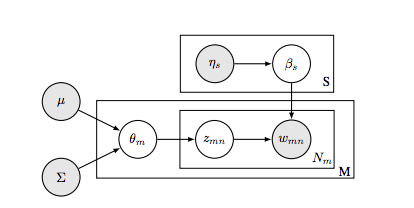
提出模型
1. 对于每个同义词组,s∈{1,...,S}
(a)提取词的分布βs~Dir(ηs)
2. 对于每个文本,m∈{1,...,M}
(a)选取αm~N(µ, Σ)
(b)将αm转换成同义词组部分θm=f(αm)
(c)对于文本中的每个词n∈{1,...,Nm}
i. 提取同义词组Zmn~Mult(θm)
ii.从指定词组中提取单词Wmn~Mult(βZmn)
其中softmax函数为:

图三是模型的生成过程:
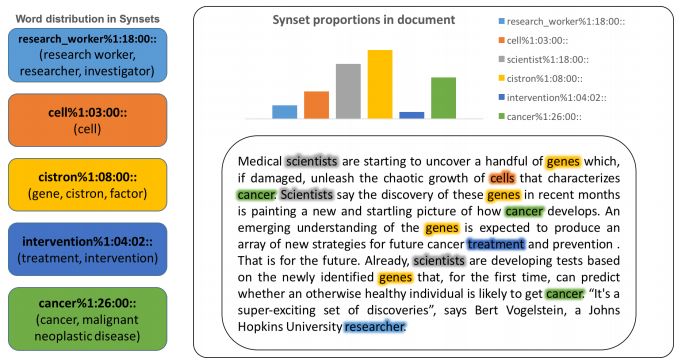
图四是同义词组中的词语分布,以及模型生成的同义词组在文本中的分布。
实验与结果
为了评估该模型,研究人员利用英语语言WSD的基准数据库SensEval-2、SensEval-3、SemEval-2007、SemEval-2013以及SemEval-2015。下表是WSD-TM与无监督方法以及监督式方法的F1分数结果比较,每一栏中最高分均加粗表示:
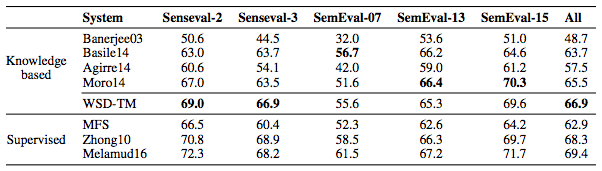
相比现有的其他技术,WSD的总体F1分数为66.9,具有明显优势。
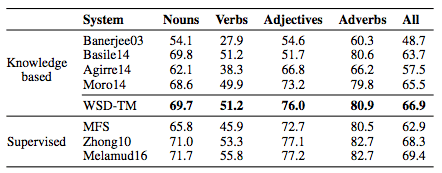
另外,研究人员还比较了不同词性的F1分数。他们所提出的模型完胜其他无监督模型。
结语
用整篇文档作为词义消歧的语境到底有什么好处呢?以下就用一个例子来说明。
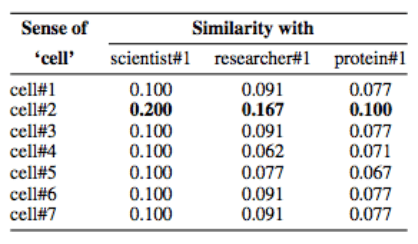
再回过头看图三中的那段话,我们能从高亮的词语中推断出这是一段有关生物的文字,在这之中的大多数词语都是单义同义词(monosemous)。然而我们注意到其中的“cell”一词在WordNet中拥有七种不同的意思:

而在下表中,可以看到“cell”的正确意思“cell#2”与其他三个单词“scientist#1”、“researcher#1”和“protein#1”的相似度最高。在整个文档中,“cell”出现了21次,但是除了这三个单词之外,其他几处语境均无法准确判断“cell”的意思是什么。
原文地址:arxiv.org/abs/1801.01900




