


1、韩语语音识别研究现状
引言
经过半个多世纪的发展,语音识别取得了大量令人欣喜的成果,系统已从少数孤立词识别演变为大词表连续语音识别,从单一语言识别演变为混合语言识别,从特定说话人识别演变为非特定说话人识别甚至交谈语音识别。
同时,语音识别的研究方向逐渐向复杂和多元化的任务发展。一方面,主流语音识别系统的速度和精度在持续提升。如加权有限状态机(Weighted Finite State Transducer,WFST)的使用为解码过程提供一种新的解决方案,大幅提高语音识别系统的运算效率。神经网络开始应用于声学模型和语言模型建模,并逐步替代了传统的隐马尔可夫模型方法。工业界上,谷歌CEO SundarPichai在2017年谷歌I/O大会上宣称,谷歌的语音识别技术现在错误率已降低到了4.9%。
另一方面,所识别语种不再局限于英语、汉语等主要国家的语言,像土耳其语、阿拉伯语、芬兰语等语言的语音识别系统也逐渐被开发出来。但由于这些语种积累的时间比较短,语料积累受限,本身又存在各种发音和文法特点,采用通用框架势和主流方法可能不会得到预期效果。
1、韩语语音识别研究现状
在语言学中,韩语属于黏着语,其自然词汇由大量词素聚集构成,同时语言具有丰富的音韵变化。黏着语是语言形态学中的一个语言类别,这一类别的语言需要大量依靠词素的屈折变化来表现文法关系。由于语音识别技术在发展历程中主要的研究对象是分析语或低屈折度语言,因此黏着特性对主流语音识别技术构成多项挑战。
带来的挑战主要有两点,第一个主要是语言模型方面,韩语的自然语言单元是由空格分割开的字和词,长度不固定,有可能是实体词加助词,也可能是单独的实体词,对应于英语中的几个单词。黏着语的特性使韩语词拥有大量的变化形式,常见的可达数百万,这一数量远远超过常规语音识别系统词典尺寸。即使把训练语料中出现的词都放进词典,还是会有大量集外词(Out of Vocabulary,OOV)。如果采用字作为语言模型基本建模单元,又会出现短视问题。目前一般采用基于数据驱动的方法生成一种介于字和词之间语言模型建模单元,称为融合单元,也有人叫词片。或者采用统计与规则相结合的方法生成词素级语言模型建模单元。
第二个挑战是声学模型建模,黏着特性导致严重的协同发音,从而使声学模型的混淆度大大提升。解决方案,可以通过引入同位音素的概念来削弱声学模型的混淆程度,但实验证明这一方法尽管在单音子(monophone)声学模型建模单元上效果较为显著,但在常规语音识别系统所使用的三音子(triphone)声学模型建模单元上效果并不理想。
2、韩语介绍
2.1 音节与音素
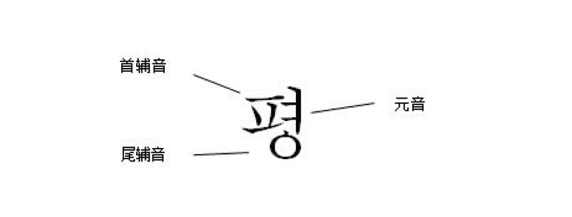
韩语所使用的文字称为谚文,谚文属于音型文字,就是你看到这个字的时候,即使不知道意思,也可以读出发音。在组字的时候以音节为单位,每一个文字表示一个音节。每个音节至多由三个音素构成,按照发音顺序,分别称为首辅音、元音和终尾辅音,此三部分遵循“从左到右,自上而下”的基本规则进行书写。
如果按照书写方式来分,在韩语中共有首辅音19 种,元音21种,尾辅音27种。由于韵尾可以省略,因此韵尾共有28 种形式,由此可以推算出谚文数量为19×21×28=11172个。就发音而言,每种首辅音和元音都有其独特的发音,但是首辅音o为不发声辅音,而27 种韵尾则被归结为7组,每组中所有的尾辅音都与一个特定的首辅音发音相同。同时考虑到不含韵尾的情况,朝鲜语音节数量共计19×21×8=3192。
韩语的变音情况太多,这里就不介绍了,常见的变化现象有连读、有气音化、紧音化等。
2.2 词汇
韩语词汇在句中以空格分隔,其由若干谚文构成,谚文数量可以是一个或者多个。下图给出了一些韩语词形态学变化和对应翻译。
大多数时候,韩语的训练语料非常有限,又由于韩语是音形字,所以有很多学者研究从韩语形态学分析发音,自动生成训练的语音。在unicode编码中,有特定编码段用以表示韩语字符。其中韩语音素所在码段为1100至11FF,包括66种韩语元音和辅音,以及部分现代韩语已经较少使用的音素。谚文所在的码段则为AC00至D7AF,包含全部11172个谚文。码段中以首辅音/元音/尾辅音为键值对谚文顺序编码,因此可以根据谚文字形简便获得其unicode编码。同理,我们可以通过韩文的unicode编码反推罗马读音,加上一些韩文的变音规则,在资源极度缺乏的时候,可以用来自动生成韩语的声学训练语料,从unicode编码反推罗马读音的代码。
base = 44032
df = int(integers[iElement]) - base
iONS = int(math.floor(df / 588)) + 1
iNUC = int(math.floor((df % 588) / 28)) + 1
iCOD = int((df % 588) % 28) + 1
3、韩语识别系统
3.1 语音识别系统框架
一个传统的语音识别系统主要由信号处理他和特征提取,声学模型,发音词表,语言模型,和解码搜索几个大部分构成。具体就是讲音频信号作为输入,通过信号处理和特征提取、消除噪声和信道失真,将信号从时域转化为频域,为声学模型提取相应有代表性的特征。声学模型以特征提取部分生成的特征作为输入,生成可变长特征序列的声学得分。言模型估计通过从训练语料学习词之间的相互关系,来估计假设词序列的可能性,输出语言模型得分。解码搜索对给定的特征序列和若干假设词序列计算声学模型分数和语言模型分数,将总体输出得分最高的词序列当作识别结果。在我们的韩语识别系统里,声学模型部分采用的是传统hmm框架结合深度学习模型,用深度学习模型估计HMM state 类的后验概率,经过实验,我们选用了效果最好的LSTM+DNN模型。
3.2 韩语扩展音素集
如前文介绍,韩语属于音形文字,根据字形共可转化出19种首辅音、21种元音以及27种尾辅音。其中每种首辅音和元音均具有独立发音,而尾辅音则与一种首辅音发音相同,共分为7种。作为一种特殊情况,音素o作为首辅音时将不发音,仅作为尾辅音时正常发音。鉴于这种统一的发音方式,先前的研究者通常将相同的发音首辅音和尾音归为同一音素,此种方法韩语音素集按照理论发音构建,包含18个首辅音、21个元音和1个尾辅音,共计40个音素。也有一些研究者使用国际音标。然而,尽管尾辅音在理论上与一种首辅音发音相同,但鉴于其在音节中所处的位置与首辅音完全不同,因此其协同发音的情况也有很大差异。其中一些比较显著的差异已被先前的研究所记载。因此,考虑将部分或全部尾辅音作为独立音素处理不失为一种恰当的做法。
3.3 韩语识别决策树的创建
在HMM模型中,一般通过决策树来实现高效的tri-phone 对senone的选择,通过回答一系列前后音所属类别的问题(元辅音、清浊音),最终确定其HMM状态对应使用哪个senone。决策树问题集人工设计可以获得更好的效果,但是需要涉及到大量语言学和形态学知识。所以在韩语识别中,采用半自动生成决策树。具体方法如下:
1 聚类时采用48个monophone类别加1个静音一共49个类别作为每个节点的候选问题集。
2 由于声学模型的内容相关性,计算时考虑中心phoneme附近个phoneme,其中w为音素的最大上下文宽度。
3 预备聚类的状态集放在决策树的根节点上并计算其对数似然值。
4 对每个节点、每个问题:计算在这个问题下分裂成的yes和no子节点的对数似然值比父节点的对数似然值增加值,像二叉树一样分裂成两个相继的节点。
5 然后再以相继的节点为根节点,继续向下分裂,直到叶子节点数目达到达到聚类要求,或者满足给定的终止条件。
4、实验
4.1数据集
韩语实验数据主要采集自真实场景下,桌面和手机数据皆有,共2000多人的2000h数据,主要为16k采样率多通道数据。语言模型大约为100G的韩语文本语料,发音词典大约20w。
4.2 实验结果
声学模型方面,初始特征被选取为52维PLP特征,包括12维基本特征外加能量,取3阶差分,最后通过HLDA方法降至40维。声学模型共享状态数被选取为8000,同时每个状态具有64个高斯分量,最后加入鉴别训练MMI。NN部分采用3层lstm加2层dnn,lstm采用1024个cells,projection为512。
实验比较的是使用音素集为标准音素集,包含共计40个音素,和扩展因素集的结果,实验从2000多个人中选取部分人作为测试集,其他人作为训练集。
音素集 |
字错误率wer |
40基础音素集 |
14.5 |
扩展音素 |
9.16 |
5、总结
由于韩语属于黏着语,又有相应特殊的发音和书写特点。所以我们在传统的语音识别框架上做了一些调整,其实还有很多工作是花在韩语数据的采集、筛选和预处理上,比如语言模型语料中对助词的处理,不符合规则发音的筛选。
在声学模型建模方向,除了传统的HMM框架,也可以尝试最近比较火的End to End的识别系统,比如用LSTM接CTC,采用粗粒度的建模单元。
总体来说,业界对韩语语音识别的研究整体上仍处于起步阶段,仍然有很多工作需要细化与深入。在之后的文章中我们还将介绍 CNN 在语音识别中的应用,敬请期待哦!

 微信ID:WeChatAI
微信ID:WeChatAI
 长按左侧二维码关注
长按左侧二维码关注



