SLAM后端优化中卡尔曼滤波的直观通俗解释
点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
本文由知乎 郑纯然 授权转载
原文链接:
https://zhuanlan.zhihu.com/p/146593826
先讨论滤波器的概念,滤波的意思是,让机器人在某个正确位置上对应的概率越高越好。也就是可以理解为:把错误位置上的概率滤低,把正确位置处的概率滤高。
假设一个机器人小R在如下场景中出现,他刚开始不知道自己在哪(小R还没看到他眼前的门),因此他在这个场景中任何位置的概率是相等的。如果此时纵坐标为机器人小R在对应位置处的概率,横坐标表示各个位置,应该是一条均匀分布的直线。

突然,机器人看到了眼前这个门,这里假设机器人提前知道一共有三个门,因此小R现在知道自己可能在任意一个门前,即三个门分别对应着一个正态分布。此时的概率波形可以理解为先验概率。

小R继续向前走到第二个门前,他通过自己身上安装的里程计发现自己走了d个单位。
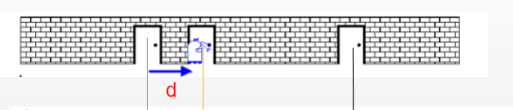
根据之前的概率分布,小R可以预测到,自己的位置应该向右平移了d个单位。那么可以将之前的概率分布向右平移d个单位,得到此时通过传感器得到的概率分布。此时的概率波形可以理解为似然概率。
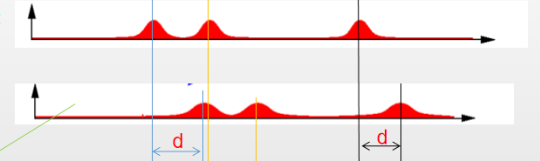
小R突然发现自己看到了第二扇门前,仅根据当前的观测,小R知道自己在三个门前的概率相同,又可以得到之前的三个正态分布。根据传感器预测得到的分布和根据先验信息得到的分布得:

两个波形信号可以做个卷积融合得到:

这样小R在第二扇门处(正确位置)的概率就变大了,在其他位置处的概率就变小了,进而达到了滤波的目的。
以上即是普通滤波器的直观解释,同样地,可以类比到卡尔曼滤波上。
我们假设机器人的状态xk 为 



由式(1)可知,新的最优状态估计是根据上一时刻最优估计预测得到的,并加上已知外部控制量的修正(比如控制油门加速)。

由式(2)可知,新的不确定性由上一时刻不确定性预测得到,并加上外部环境的干扰。这时我们对系统的变化有了模糊的估计,更新的状态(均值)和不确定性(协方差)分别如式(1)和(2),预测的过程相当于之前的波形向右平移d个单位的过程。
此时结合传感器数据会如何?再来谈谈测量模型,利用传感器我们可以猜到系统当前的状态,但由于传感器存在噪声,传感器读数(均值)和噪声(方差)为 

这时我们已经得到了两个高斯分布,类似于之前机器人小R在当前时刻得到的两个分布,将两个高斯分布融合的过程网上有很多推导,这里不多赘述,直接利用结果。
先计算卡尔曼增益K,如式(3)。

然后计算后验概率的分布:

式中Zk 表示实际的观测, 

得到的新的最优估计可以放到下一时刻不断迭代。
以上就是经典卡尔曼滤波器的五个公式,给出了线性高斯系统的最优无偏估计。我们可以用这些公式对任何线性系统建立精确的模型,对于非线性系统来说,我们使用扩展卡尔曼滤波,区别在于EKF多了一个把预测和测量部分进行线性化的过程。
此时再看这个高赞无公式推导的回答来回顾全局,一切豁然开朗:无公式直白解释卡尔曼滤波
假设你有两个传感器,测的是同一个信号。可是它们每次的读数都不太一样,怎么办?
取平均。
再假设你知道其中贵的那个传感器应该准一些,便宜的那个应该差一些。那有比取平均更好的办法吗?
加权平均。(乘卡尔曼增益 K)
怎么加权?假设两个传感器的误差都符合正态分布,假设你知道这两个正态分布的方差,用这两个方差值,(此处省略若干数学公式),你可以得到一个“最优”的权重。
接下来,重点来了:假设你只有一个传感器,但是你还有一个数学模型(指的是上文中的预测模型)。模型可以帮你算出一个值,但也不是那么准。怎么办?
把模型算出来的值,和传感器测出的值,(就像两个传感器那样),取加权平均。
OK,最后一点说明:你的模型其实只是一个步长的,也就是说,知道x(k),我可以求x(k+1)。问题是x(k)是多少呢?答案:x(k)就是你上一步卡尔曼滤波得到的、所谓加权平均之后的那个、对x在k时刻的最佳估计值。
于是迭代也有了。
这就是卡尔曼滤波。
(无公式)
利用滤波方法进行传感器融合方面的经典论文推荐:
[1] Bloesch M, Omari S, Hutter M, et al. Robust visual inertial odometry using a direct EKF-based approach[C]//2015 IEEE/RSJ international conference on intelligent robots and systems (IROS). IEEE, 2015: 298-304.
[2] Qiu X, Zhang H, Fu W, et al. Monocular Visual-Inertial Odometry with an Unbiased Linear System Model and Robust Feature Tracking Front-End[J]. Sensors, 2019, 19(8): 1941.
[3] Xiong X, Chen W, Liu Z, et al. DS-VIO: Robust and Efficient Stereo Visual Inertial Odometry based on Dual Stage EKF[J]. arXiv preprint arXiv:1905.00684, 2019.
[4] Bloesch M, Burri M, Omari S, et al. Iterated extended Kalman filter based visual-inertial odometry using direct photometric feedback[J]. The International Journal of Robotics Research, 2017, 36(10): 1053-1072.
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

投稿、合作也欢迎联系:simiter@126.com

长按关注计算机视觉life
PS:公众号最近更改了推送规则,不再按时间顺序推送,而是根据智能推荐算法有选择性向用户推送,有可能以后你无法看到计算机视觉life的文章推送了。
解决方法是看完文章后,顺手点下文末右下角的“在看” ,系统会认为我们的文章合你口味,以后发文章就会第一时间推送到你面前的,比心~






