四个任务就要四个模型?现在单个神经网络模型就够了!

AI 科技评论按:顾名思义,「表示」(representation)就是指在网络中对信息进行编码的方式。为了让大家充分理解「表示」,本文作者尝试构建一个能同时完成图像描述,相似词、相似图像搜索以及通过描述图像描述搜索图像四项任务的深度神经网络,从实操中让大家感受「表示」的奇妙世界。
众所周知,神经网络十分擅长处理特定领域的任务,但在处理多任务时结果并不是那么理想。这与人类大脑不同,人类大脑能够在多样化任务中使用相同的概念。例如,假如你从来没听说过「分形」(fractal),不妨看一下下面这张图:
在看到张分形图像后,人类能够处理多个与之相关的任务:
在一组图像中,区分出分形图像和一只猫的图像;
在一张纸上,粗略地画出分形图的样子(它不会很完美,但也不会是随意的涂鸦);
将类似分形的图像与非分形图像进行分类(你会毫不犹豫地将图像按最相似到最不相似的方式进行分类);
闭上眼睛,想象一下分形图像是什么样子的(即使现在不给你一张现成的分形图象,你也可以在看过它一次之后,就想象出它的样子,是不是很棒!)
那么,你是如何完成这些任务的呢?你的大脑中是否有专门负责处理这些任务的神经网络?
现代神经科学对此给出了答案:大脑中的信息是跨不同的部位进行分享和交流的。大脑究竟怎样完成这些任务只是研究的一个领域,而对于这种执行多任务的能力是怎样产生的,我们也有一些线索——答案可能就存在于如何在神经网络中存储和解释数据。
「表示」的奇妙世界
顾名思义,「表示」(representation)就是指在网络中对信息进行编码的方式。当一个单词、一个句子或一幅图像(或其他任何东西)被输入到一个训练好的神经网络时,随着权重与输入相乘并进行激活操作时,它就能在连续的层上实现转换。最后,我们在输出层中得到一串数字,我们将其解释为类标签或股价,或网络为之训练的任何其他任务。
这种神奇的输入->输出转换因连续层中发生的输入转换得以实现。输入数据的这些转换即称为「表示」。它的一个重要思想是,每一层都让下一层更容易地执行任务。这个过程让连续层的存在变得更容易,进而也使得激活(特定层上输入数据的转换)变得有意义。
我所说的有意义是指什么呢?让我们看下面的示例,其展示了图像分类器中不同层的激活:

图像分类网络的作用是将像素空间中的图像转化为更高级的概念空间。例如,一张最初用 RGB 值表示的汽车图像,首先在第一层用边缘空间表示,然后在第二层被表示为圆圈和基本形状空间,在倒数第二层则开始使用高级对象(如车轮、车门等)表示。
随着表示(由于深度网络的层次性而自动出现)日益丰富,图像分类的任务也变得微不足道。最后一层要做的就是权衡车轮和车门的概念更像汽车以及耳朵、眼睛的概念更像人。
表示能够运用在哪些方面?
由于这些中间层存储有意义的输入数据编码,所以可以对多个任务使用相同的信息。例如,你可以使用一个语言模型(一个经过训练、用于预测下一个单词的循环神经网络),并解释某个特定神经元的激活以预测句子的情绪。
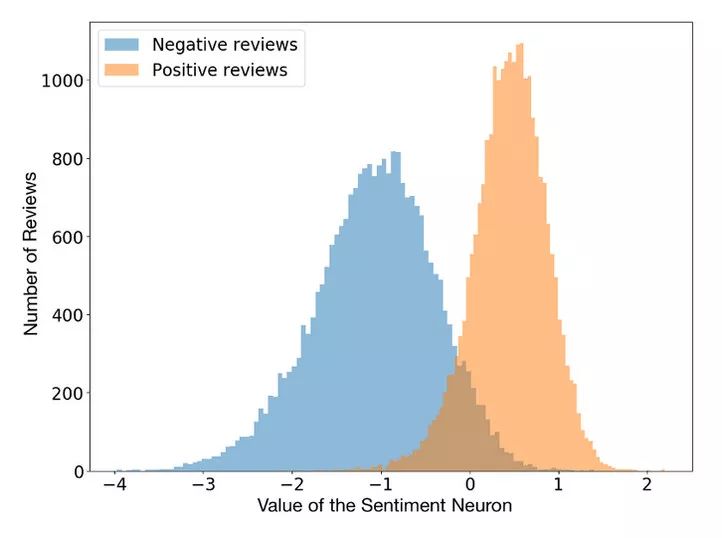
(via Unsupervised Sentiment Neuron)
一个令人惊讶的事实是,情感神经元是在无监督的语言建模任务中自然出现的。(相关文章请参阅:https://rakeshchada.github.io/Sentiment-Neuron.html)。网络经过训练来预测下一个单词,然而在任务中我们没有要求网络预测情绪。也许情感是一个非常有用的概念,以至于网络为了更好地进行语言建模而创造了它。
一旦你理解了「表示」这个概念,你就会开始从完全不同的角度来理解深层神经网络。你会开始将表示(sensing representations)视作一种能够让不同网络(或同一网络的不同部分)之间实现通信的可转换的语言。
通过构建一个「四合一」的网络来探索表示
为了充分理解「表示」,让我们来构建一个能同时完成四个任务的的深度神经网络:
图像描述生成器:给定图像,为其生成标题
相似单词生成器:给定一个单词,查找与之相似的其他单词
视觉相似的图像搜索:给定一幅图像,找出与之最相似的图像
通过描述图像描述搜索图像:给出文本描述,搜索具有所描述的内容的图像
这三个任务中的每一个本身都是一个项目,一般来说需要三个模型。但我们现在要用一个模型来完成所有这些任务。
该代码将采用 Pytorch 在 Jupyter Notebook 中编写,大家可以前往这个存储库进行下载:
https://github.com/paraschopra/one-network-many-uses
第一部分:图像描述(Image Captioning)
在网上有很多实现图像描述的好教程,所以这里就不深入讲解。我的实现与这个教程中所使用的方法完全相同:构建一个自动化的图像标题应用程序(教程链接:https://daniel.lasiman.com/post/image-captioning/)。关键的区别在于,我的实现是使用 Pytorch 实现的,而教程使用的是 Keras。
要继续学习,你需要下载 Flickr8K 数据集(1GB Flickr8K 数据集的下载链接:https://github.com/jbrownlee/Datasets/releases/download/Flickr8k/Flickr8k_Dataset.zip,不过我不确定这个链接的有效期多长)。填好这张表格(https://forms.illinois.edu/sec/1713398)后,你的电子邮件会收到一个下载链接。将 zip 文件解压到与笔记本目录相同的「Flicker8k_Dataset」文件夹中。您还需要从这里(http://cs.stanford.edu/people/karpathy/deepimagesent/caption_datasets.zip)下载描述,并提取「caption_datasets」文件夹中的描述。
模型
图像描述一般由两个组成部分:
a)图像编码器(image encoder),它接收输入图像并以一种对图像描述有意义的格式来表示图像;
b)图说解码器(caption decoder),它接受图像表示,并输出文本描述。
图像编码器是一个深度卷积网络,而图说解码器则是传统的 LSTM/GRU 循环神经网络。当然,我们可以从头开始训练它们。但这样做的话,就需要比我们现有的(8k 张图像)更多的数据和更长的训练时间。因此,我们不从头开始训练图像编码器,而是使用一个预训练的图像分类器,并使用它倒数第二层的激活。
你将在本文中看到许多神奇的表示示例,下面这个示例是第一个。我使用在 ImageNet 上进行了训练的 PyTorch modelzoo 中可用的 Inception 网络来对 100 个类别的图像进行分类,并使用该网络来提供一个可以输入给循环神经网络中的表示。
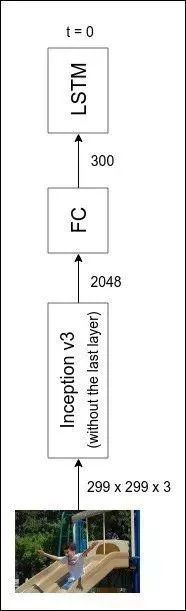
via https://daniel.lasiman.com/post/image-captioning/
值得一提的是,虽然 Inception 网络从未对图说生成任务进行过训练,但是它的确有效!
如我在通过机器学习形成机器学习思路一文中所做的那样,我们使用了一个预训练的语言模型来作为图说解码器。但这一次,由于我重新实现了在教程中运行良好的模型,仅按照教程的步骤便从头开始训练了一个解码器。
完整的模型架构如下图所示:
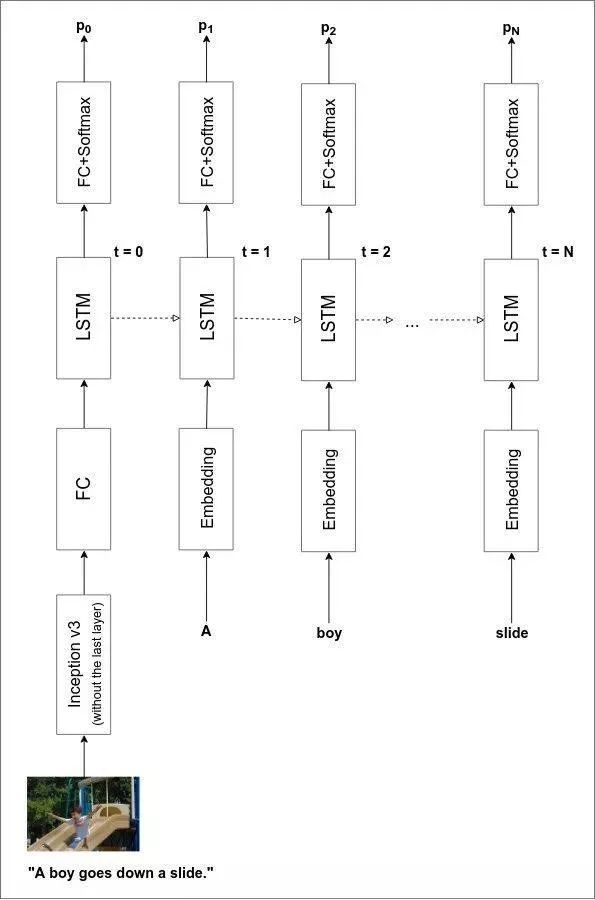
Image via https://daniel.lasiman.com/post/image-captioning/
你可以从头开始训练模型,但是在 CPU 上就要花费几天时间(我没有对 GPU 进行优化)。但不用担心,我的笔记本电脑度过了几个不眠之夜训练出来的模型成果,可供大家使用。(如果你是从头开始训练,需要注意的是,当运行的平均损失约为 2.8 时,我在大概 40 epochs 时停止了训练。)
性能
我采用的集束搜索(beam search)方法实现了良好的性能。下面是网络为测试集中的图像所生成的图说示例(网络此前从未见过这种图像)。


用我自己的照片试试,看看网络生成的图说是什么:

效果不错!令人印象深刻的是,网络知道这张照片中有一个穿着白色 T 恤的男人。另外虽然图说的句子语法有些错误(我相信通过更多的训练可以修正这些错误),但基本的要点都抓住了。
如果输入的图像包含网络从未见过的东西,它往往会失败。例如,我很好奇网络会给 iPhone X 的图像贴上什么样的标签。
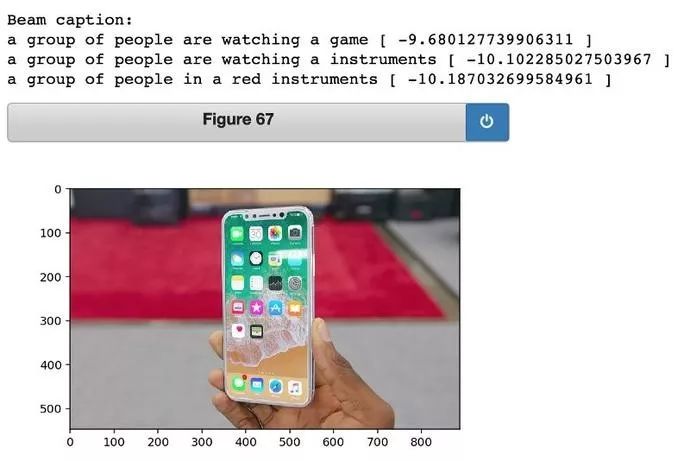
效果不太好。但总的来说,我对其性能非常满意,这为我们在学习生成图说时,使用网络所开发的「表示」构建其他功能提供了良好的基础。
第二部分:相似词
回想一下我们如何对由图像表示得到的图说进行解码。我们将该表示提供给 LSTM/GRU 网络,生成一个输出,将输出解释为第一个单词,然后将第一个单词返回给网络以生成第二个单词。这个过程一直持续到网络生成一个表示句子结束的特殊标记为止。
为了将单词反馈到网络中,我们需要将单词转换为表示,再输入给网络。这意味着,如果输入层包含 300 个神经元,那么对于所有图说中的 8000 多个不同的单词,我们需要有一个唯一指定那个单词的「300」数字。将单词字典转换成数字表示的过程,就称为词嵌入(或词表示)。
我们可以下载和使用已经存在的词嵌入,如 word2vec 或 GLoVE。但在本例中,我们从零开始学习一个词嵌入。我们从随机生成的词嵌入开始,并探索我们的网络在完成训练时从单词中学到了什么。
由于无法想象 100 维的数字空间,我们将使用一种称为 t-SNE 的神奇技术将学到的词嵌入在二维空间可视化。t-SNE 是一种降维技术,它试图使高维空间中的邻域不变地投射为低维空间中的邻域。
词嵌入的可视化
让我们来看看图说解码器所学习到的词嵌入空间(不像其他语言任务中有数百万个单词和句子,我们的解码器在训练数据集中只看到了大约 3 万个句子)。
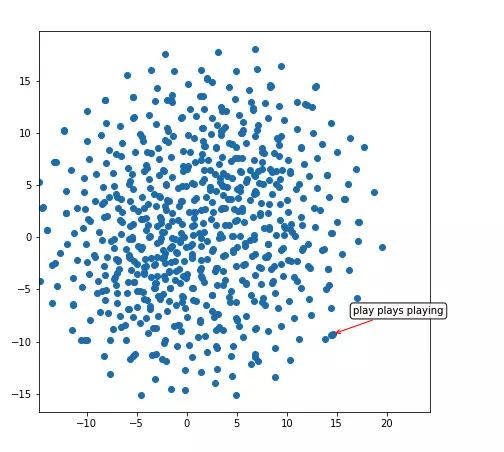
因此,我们的网络已经了解到像「play」、「plays」和「playing」这样的词汇是非常相似的(它们具有相似的表示,如红色箭头所示的密集聚类)。让我们看看这个二维空间中的另一个区域:
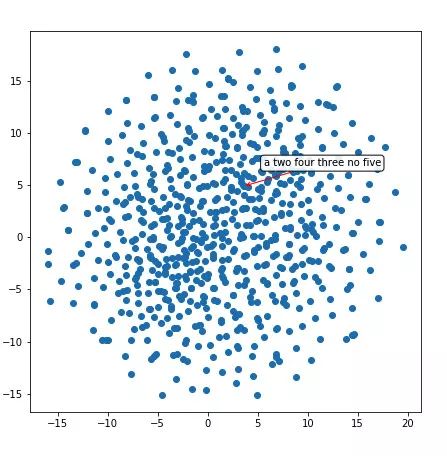
这个区域似乎有一堆数字——「two」、「three」、「four」、「five」等等。再看另一个:
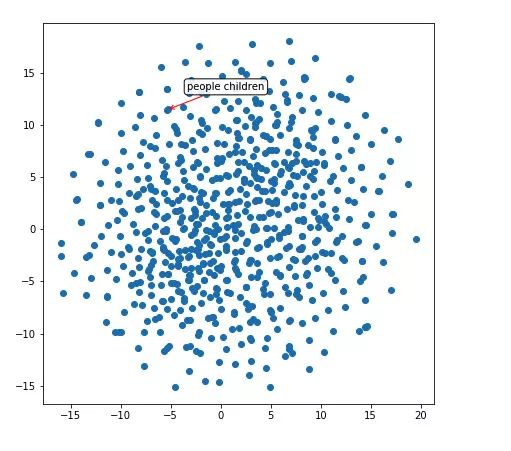
上图,它知道「people」和「children」这两个单词相似。而且,它还隐晦地推断出了物体的形状。
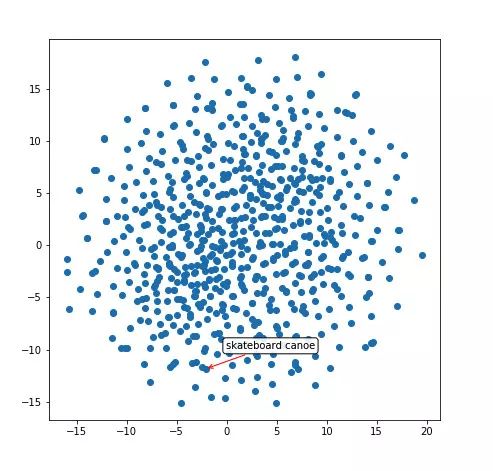
相似词
我们可以使用 100 维表示来构建一个函数,该函数可找出与输入单词最相似的单词。它的工作原理很简单:采用 100 维的表示,并找出它与数据库中所有其他单词的余弦相似度。
让我们来看看与「boy」最相似的单词:
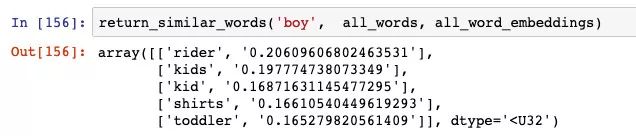
结果不错。除「Rider」外,但「kids」、「kid」和「toddler」都是正确的。
这个网络认为与「chasing」相似的词汇是:
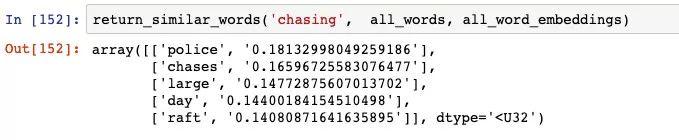
「Chases」是可以理解的,但我疑惑的是为什么它认为「police」与「chasing」类似。
单词类比(Word analogies)
关于词嵌入的一个振奋人心的事实是,你可以对它们进行微积分计算。你可以用两个单词(如「king」和「queen」)减去它们的表示来得到一个方向。当你把这个方向应用到另一个词的表示上(如「man」),你会得到一个与实际的类比词(比如「woman」)很接近的表示。这就是为什么 word2vec 一经推出就如此受欢迎:
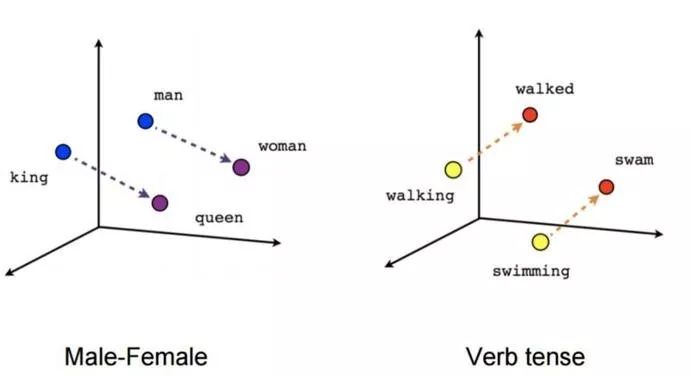
via https://www.tensorflow.org/images/linear-relationships.png
我很好奇通过图说解码器学习到的表示是否具有类似的属性。尽管由于训练数据并不大(大约 3 万个句子)我对结果持怀疑态度,但我还是尝试了一下。
网络学到的类比并不完美(由于有些单词书面上出现的次数<10次,因此网络没有足够的信息可供学习),这种情况下我不得不仔细去看,但是发现仍有一些类比。
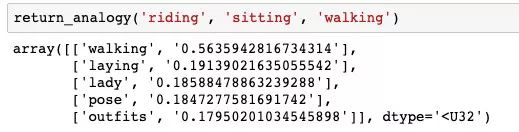
如果「riding」对应「sitting」,那么「walking」对应什么呢?网络认为应该是「laying」(这个结果还不错!)
同样,如果「man」的复数是「men」,那么「woman」的复数应该是什么呢:
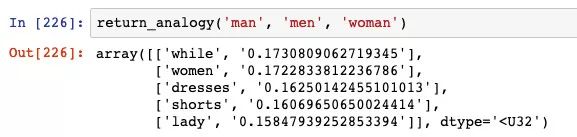
第二个结果是「women」,相当不错了。
最后,如果「grass」对应「green」,那么「sky」对应什么呢:

网络认为「sky」对应「silver」或「grey」的,虽然结果中没有出现「blue」,但它给的结果都是颜色词。令人惊讶的是,这个网络还能够推断颜色的方向。
第三部分:相似图像
如果词表示将类似的单词聚类在一起,那么图像表示(Inception支持的图像编码器输出)呢?我将相同的 t-SNE 技术应用于图像表示(在图说解码器的第一步中作为输入的 300 维度的张量)。
可视化
这些点是不同图像的表示(我没有使用全部的 8K 图像,只使用了大约 100 张图像样本)。红色箭头指向附近一组表示的聚类。
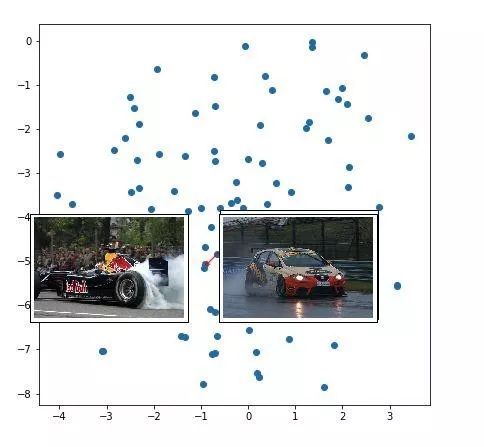
赛车的图像被聚类在一起。
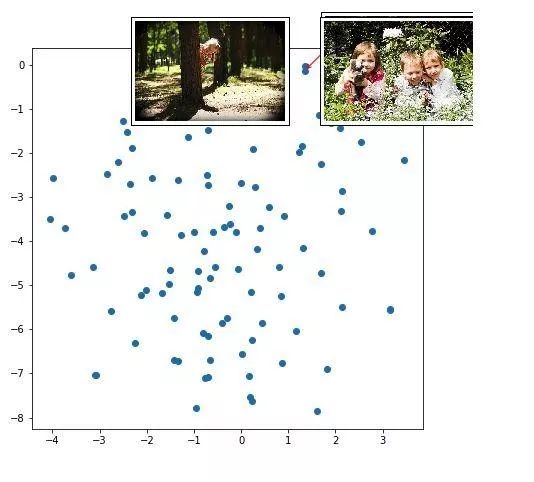
孩子们在森林/草地玩耍的图像也被聚类在一起。
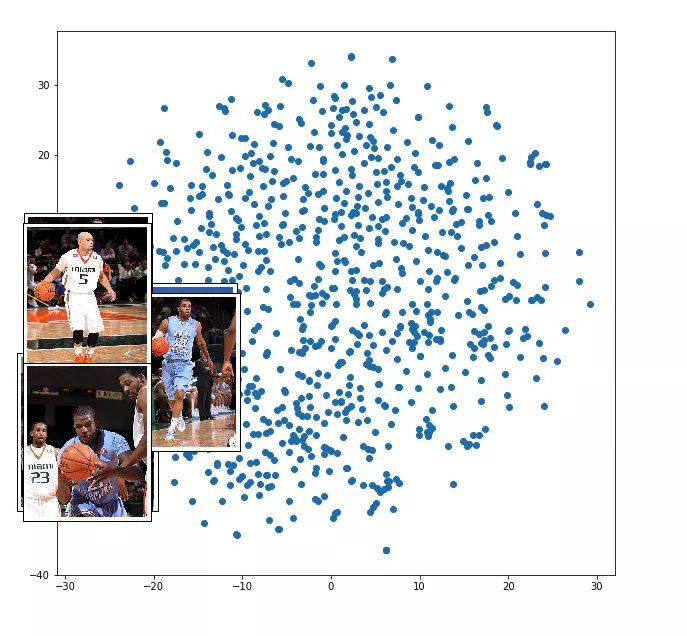
篮球运动员的图像也被聚类在一起。
查找与输入图像相似的图像
对于查找相似单词的任务,我们受限于在测试集词汇表中寻找相似的单词(如果测试集中不存在某个单词,我们的图说解码器就不会学习该单词的嵌入)。然而,对于类似的图像任务,我们有一个图像表示生成器,它可以接收任何输入图像并生成其编码。
这意味着我们可以使用余弦相似度的方法来构建一个按图像搜索的功能,如下所示:
步骤 1:获取数据库或目标文件夹中的所有图像,并存储它们的表示(表示由图像解码器给出);
步骤 2:当用户希望搜索与已有图像最相似的图像时,可以输入新图像的表示,并在数据库中找到与之最接近的图像(数据库由余弦相似度给出)。
谷歌图像就可能会正式使用这种(或类似的)方法来支持其反向图像搜索功能。
让我们看看这个网络是如何工作的。我点击了下面这张我在 Goa 度假时拍的照片。(PS:我爱 Goa!)

注意,这张图片是我自己的,而我们使用的模型此前从未见过这张图片。当我查询类似的图像时,网络从Flickr8K 数据集中输出如下图像:

是不是很像?我没想到该模型会有这么好的表现,但它确实做到了!深度神经网络简直太棒了!(https://www.youtube.com/watch?v=Y-WgVcWQYs4)
第四部分:通过描述来搜索图片
在最后一部分中,我们将反向运行图说生成器。因此,我们不是获取图像并为其生成图说,而是输入图说(文本描述)来找到与之最匹配的图像。
听起来好得令人难以置信?当然可以相信!我们是这样做的:
步骤 1:首先输入的是一个完全随机的 300 维张量,而不是一个来自编码器的 300 维图像表示;
步骤 2:冻结整个网络的所有层(例如引导 PyTorch 不要对梯度进行计算);
步骤 3:假设随机生成的输入张量来自图像编码器,将其输入到图说解码器中;
步骤 4:获取给定随机输入时网络生成的图说,并将其与用户提供的图说进行比较;
步骤 5:比较生成的图说和用户提供的图说,并对二者存在损失进行计算;
步骤 6:为输入张量找到梯度,使损失最小化(例如,在哪个方向以及 300 维数中的每个数值应该改变多少,从而使得在将张量输入到图说解码器时,图说与用户提供的图说接近);
步骤 7:根据梯度改变输入张量的方向(学习率所给定的一小步);
继续步骤 4 到步骤 7,直到收敛或当损失低于某个阈值时为止
最后一步:取最终的输入张量,并利用它的值,通过余弦相似度找到离它最近的图像(以 300 维表示的步速);
通过这样做,我们得到的结果相当神奇:
我搜索了「一只狗」,这是网络找到的图像:

搜索「一个微笑的男孩」:

最后,当我搜索:

前两个结果是:
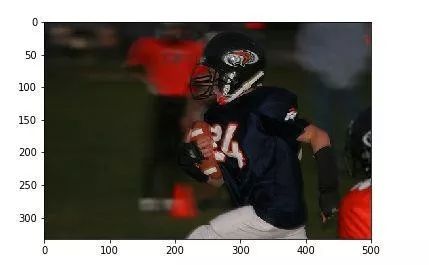
以及
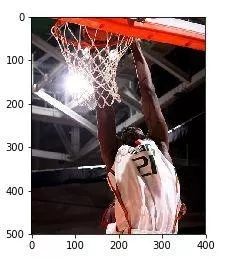
这可真是让人大开眼界,不是吗?
总结和挑战
提醒一下,大家可以从我的 Github 存储库(https://github.com/paraschopra/one-network-many-uses)中下载完成所有这些操作的代码。这个存储库包括了用于数据预处理、模型描述、预训练的图说生成网络、可视化的代码,但不包括 Flickr8K 数据集或图说——这些需要单独下载(https://forms.illinois.edu/sec/1713398)。
希望你喜欢这篇文章。如果你想进行更深入的实操,这里有一个挑战:基于给定的描述生成图像。这就好比是由一个随机的起点来生成一个与用户提供的图说匹配的 300 维图像表示一样,但是你可以更进一步,从零开始为用户提供的图说生成一个图像吗?
这比本文中的操作要难 10 倍,但我感觉这是可行的。如果有这样一个服务,它不仅可以搜索与文本对应的图像,而且能够动态生成图像,那该有多酷啊!
在未来,如果谷歌图像实现了这个功能,并能够为不存在的图像提供结果(比如「两只独角兽在披萨做成的地毯上飞翔」),我都不会感到惊讶。
就这样。我希望你能够在「表示」的世界安然而快乐地遨游。
via :
https://towardsdatascience.com/one-neural-network-many-uses-image-captioning-image-search-similar-image-and-words-in-one-model-1e22080ce73d

点击阅读原文,查看 如何高效验证深度神经网络的学习行为?看看 Facebook 是怎么做的


