如何让电脑成为看图说话的高手?计算机视觉顶会ICCV论文解读
阿里妹导读:ICCV,被誉为计算机视觉领域三大顶级会议之一。作为计算机视觉领域最高级别的会议之一,其论文集代表了计算机视觉领域最新的发展方向和水平。阿里巴巴在今年的大会上有多篇论文入选,本篇所解读的论文是阿里iDST与多家机构合作的入选论文之一,目标是教会机器读懂图片并尽量完整表达出来。

精准描述商品:计算机视觉和自然语言处理的联合
近年来,随着深度学习技术的快速发展, 人们开始尝试将计算机视觉(Vision)和自然语言处理(Language)两个相对独立的领域联合起来进行研究,实现一些在过去看来非常困难的任务,例如“视觉-语义联合嵌入(Visual-SemanticEmbedding)”。该任务需要将图像及语句表示成一个固定长度的向量,进而嵌入到同一个矢量空间中。这样,通过该空间中的近邻搜索可以实现图像和语句的匹配、检索等。
视觉语义联合嵌入的一个典型应用就是图像标题生成(Image Captioning):对于任意输入的一张图像, 在空间中找到最匹配的一句话, 实现图像内容的描述。在电商场景下, 淘宝卖家在发布一件商品时, 该算法可以根据卖家上传得图片, 自动生成一段描述性文字, 供卖家编辑发布使用。再比如,视觉语义联合嵌入还可以应用于“跨模态检索(Cross-mediaRetrieval)”:当用户在电商搜索引擎中输入一段描述性文字(如“夏季宽松波希米亚大摆沙滩裙”、“文艺小清新娃娃领飞飞袖碎花A字裙”等), 通过文字-图像联合分析, 从商品图像数据库中找到最相关的商品图像返回给用户。
之前的不足:只能嵌入较短的语句简单描述图片
以往的视觉语义联合嵌入方法往往只能对比较短的句子进行嵌入,进而只能对图像做简单而粗略的描述,然而在实际应用中,人们更希望得到对图像(或图像显著区域)更为细致精确的描述。如图1所示,我们不仅想知道谁在干什么,还想知道人物的外表,周围的物体,背景,时间地点等。

图1 现有方法的问题
现有方法:“A girl is playing a guitar.”
我们提出的方法:“a young girl sitting on a benchis playing a guitar with a black and white dog nearby.”
为了实现这个目标,我们提出一个框架:第一步从图像中找出一些显著性区域,并用具有描述性的短语描述每个区域;第二步将这些短语组合成一个非常长的具有描述性的句子,如图2所示。

图2 我们的提出的框架
为此,我们在训练视觉语义联合嵌入模型时不仅需要将整个句子嵌入空间,更应该将句子中的各种描述性短语也嵌入空间。然而,以往的视觉语义联合嵌入方法通常采用循环神经网络模型(如LSTM(Long short-term memory)模型)来表示语句。标准的LSTM模型有一个链式结构(Chain structure):每一个单元对应一个单词,这些单词按出现顺序排成一列,信息从第一个单词沿该链从前传到最后,最后一个节点包含了所有的信息,往往用于表示整个句子。显然,标准的LSTM模型只适合表示整个句子,无法表示一句话中包含的短语,如图所示。
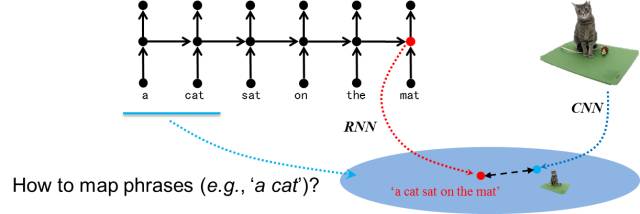
图3 链式结构的问题
论文创新方法:提出层次化的LSTM模型
本文提出一种多模态、层次化的LSTM模型(Hierarchical Multimodal LSTM)。该方法可以将整个句子、句子中的短语、整幅图像、及图像中的显著区域同时嵌入语义空间中,并且自动学习出“句子-图像”及“短语-图像区域”间的对应关系。这样一来,我们生成了一个更为稠密的语义空间,该空间包含了大量的描述性的短语,进而可以对图像或图像区域进行更详细和生动的描述,如图所示。
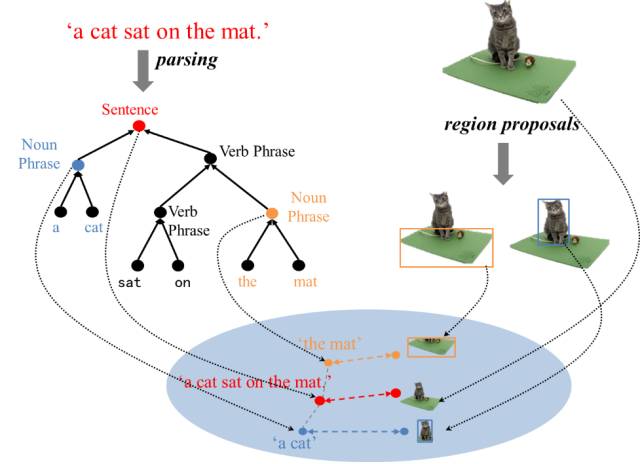
图4 本文提出的多模态层次结构
本文方法的创新性在于提出了一个层次化的LSTM模型,根节点对应整句话或整幅图像,叶子节点对应单词,中间节点对应短语或图象中的区域。该模型可以对图像、语句、图像区域、短语进行联合嵌入(Joint embedding),并且通过树型结构可以充分挖掘和利用短语间的关系(父子短语关系)。其具体网络结构如下图所示
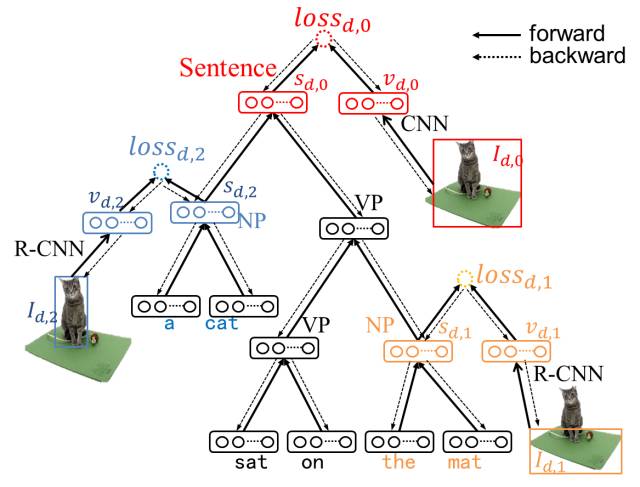
图5 网络结构
其中为每一个短语和对应的图像区域都引入一个损失函数,用于最小化二者的距离,通过基于结构的反向传播算法进行网络参数学习。
在图像-语句数据集上的比较
Image Annotation |
Image Search |
|||||
R@1 |
R@10 |
Med r |
R@1 |
R@10 |
Med r |
|
SDT-RNN |
9.6 |
41.1 |
16 |
8.9 |
41.1 |
16 |
DeFrag |
14.2 |
51.3 |
10 |
10.2 |
44.2 |
14 |
SC-NLM |
14.8 |
50.9 |
10 |
11.8 |
46.3 |
13 |
DeepVS |
22.2 |
61.4 |
4.8 |
15.2 |
50.5 |
9.2 |
NIC |
17.0 |
56.0 |
7 |
17.0 |
57.0 |
7 |
m-RNN-vgg |
35.4 |
73.7 |
3 |
22.8 |
63.1 |
5 |
DeepSP |
35.7 |
74.4 |
N/A |
25.1 |
66.5 |
N/A |
Ours |
38.1 |
76.5 |
3 |
27.2 |
68.8 |
4 |
图 6在Flickr30K数据集上的对比
Image Annotation |
Image Search |
|||||
R@1 |
R@10 |
Med r |
R@1 |
R@10 |
Med r |
|
Random |
0.1 |
1.1 |
631 |
0.1 |
1.0 |
500 |
DeepVS |
36.4 |
80.9 |
3 |
28.1 |
76.1 |
3 |
m-RNN |
41.0 |
83.5 |
2 |
29.0 |
77.0 |
3 |
DeepSP |
40.7 |
85.3 |
N/A |
33.5 |
83.2 |
N/A |
Ours |
43.9 |
87.8 |
2 |
36.1 |
86.7 |
3 |
图 7在MS-COCO数据集上的对比
可见本文方法在几个公开数据集上都获得了很好的效果
在图像区域-短语数据集上的对比
我们提供了一个带有标注的图像区域-短语数据集MS-COCO-region,其中人工标定了一些显著性物体,并在这些物体和短语之间建立了联系。
Region Annotation |
||||
R@1 |
R@5 |
R@10 |
Med r |
|
Random |
0.02 |
0.12 |
0.24 |
3133 |
DeepVS |
7.2 |
18.1 |
26.8 |
64 |
m-RNN |
8.1 |
20.6 |
28.2 |
56 |
Ours |
10.8 |
22.6 |
30.7 |
42 |
图 8在MS-COCO-region数据集上的对比
下图是我们方法的可视化结果,可见我们的短语具有很强的描述性

此外,我们可以学习出图像区域和短语的对应关系,如下


你可能还喜欢
点击下方图片即可阅读




关注「阿里技术」
把握前沿技术脉搏




