AI做题不止高数!Google新模型Minerva称霸工科竞赛:秘诀竟是保留LaTeX表达式?
![]()
新智元报道

新智元报道
编辑:LRS
【新智元导读】Google的新语言模型Minerva将AI做数学题的水平抬到新高度,而且工科领域如天文、几何、代数、机器学习统统不在话下。
用学「语文」的脑子能学好「数学」吗?

从Bert开始,到GPT-3, Gopher和PaLM,大型语言模型在各个自然语言处理任务上不断刷新成绩,创作个小作文、聊个天、写个代码都不在话下,可以说语言模型在大规模数据集下的自监督训练下已经能很好地模拟人类的语言能力了。
但定量推理(Quantitative Reasoning),也就是解决数学问题上,AI模型跟人类比还是有相当大的差距。
如果把「数学问题」作为文本输入,答案作为输出,也就只能解决一些小学数学的应用题,至于大学数学以及其他的科学和工程问题,语言模型只会「胡言乱语」。
MIT之前剑走偏锋,把「问题」作为输入,「程序代码」作为输出,基于OpenAI Codex预训练模型,借助Python解释器,在七门大学数学课程上通过few-shot learning成功达到81%的正确率。
最近Google也发布了一个基于PaLM语言模型的求解器
,在不借助外部工具的情况下取得了sota的结果。

Minerva最主要的改进点在于微调的数据集。
研究人员首先在arXiv服务器上下载了200万篇用LaTex排版的科学论文(截至2021年2月),在删掉那些内容不足75000个token的论文后,最后得到了120万篇论文,共计58GB
第二个数据渠道来自网页,先收集HTML中包含「<math」或者「MathJax-Element-」标签的,然后采用两个启发式规则过滤出用LaTex或者ASCII-math格式的内容,最后得到60GB数据
标准的数据清洗过程通常都是把符号和数学表达式给删掉,导致E=mc^2给转成了E=mc2,语义就变了。在保留LaTex数学公式后,模型在那些要求计算和符号操作的任务上性能得到显著提高。
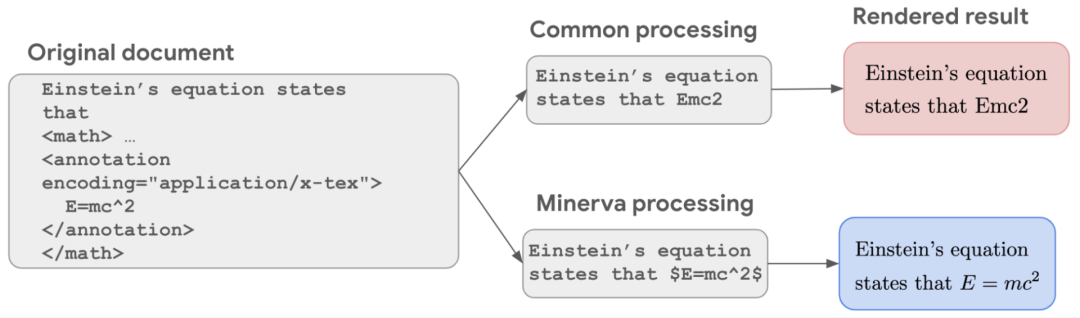
最终的训练数据连带自然语言文本和数学公式在内总共包含了385亿个token。

Minerva的训练基于三个不同尺寸的PaLM模型。

Minerva生成答案的过程使用了Chain of Thought方法来提示模型step-by-step地解决问题。

另一个技术是Majority Voting,在回答一个问题时虽然答案相同,但推理过程可能不同,Minerva通过从所有可能的输出中随机抽样来产生多个解决方案,然后对结果进行投票,把出现次数最多的结果作为最终的答案。
在评估阶段,使用了三个数据集:
MATH: 高中数学竞赛水平,包括12000个初中和高中的数学问题,问题描述使用LaTex
GSM8k: 小学级别的数学问题,包括基本的算术运算。
MMLU-STEM: 大规模多任务语言理解基准的一个子集,涵盖高中和大学水平的工程、化学、数学和物理等多个学科
实验结果直接把基线抬高一个层次,MATH的sota直接从6.9提高到50.3,而MMLU-STEM也有大幅提升。
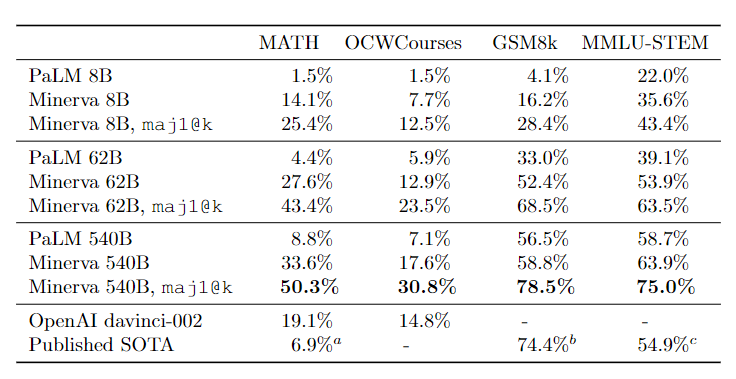
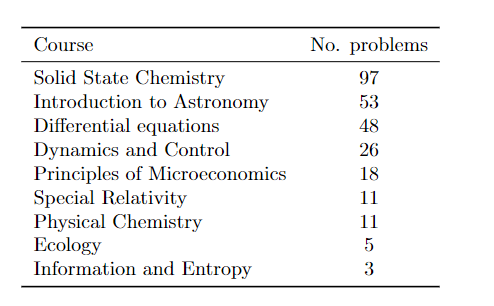
解决这几个「简单的」数据集之后,Minerva又把目标对准本科生水平的STEM问题(OCWCourses),研究人员根据MIT提供的公开课程材料(OpenCourseWare)中,在「固态化学」、「信息与熵」、「微分方程」和「狭义相对论」等课程中收集了272个问题,其中191个有数字解,81个有符号解,最终正确率达到30.8%
除此之外,Minerva 62B还参加了一次「波兰的全国数学考试」,最后得分57,正好是2021年的全国平均分;而540B的模型最终成绩为65分。
比如说几何体,尽管模型从来没有「看见」过立方体,但它仍然能通过公式计算出表面积。
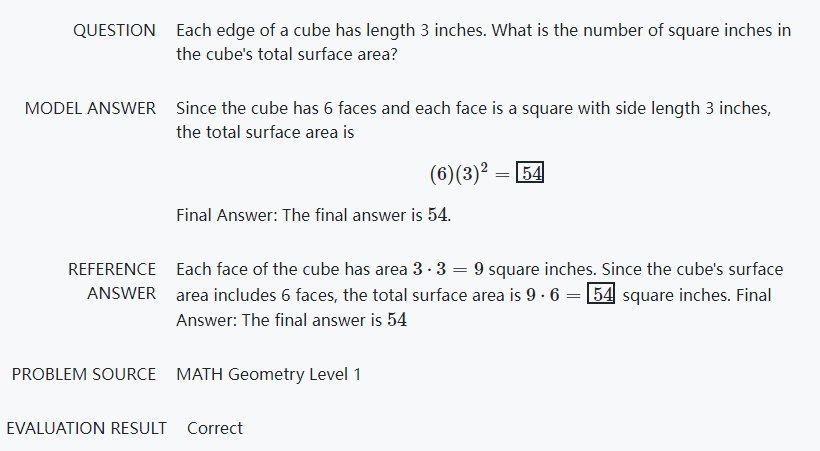
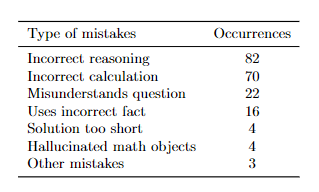
虽然Minerva的性能已经很强了,但它仍然做错了很多题目,通过分析结果可以发现,大约一半的错误是因为计算错误,另一半是推理错误,也就是解题步骤跳跃了,没有遵循思维链。
下面这个例子就是个计算错误,把式子里的根号给消了(难不成是通过其他数学公式推理出来的消根号)

推理错误的例子里,模型的推理链只有一次,实际上应该进行5次。

而且有的Minerva做对的题目也没有完全正确,有的步骤错了,但结果正确,这种情况称为False Positive,假阳率大概是8%
Minerva的这种方法也存在局限性,定量推理没有以形式化的数学公式为基础,而是采用自然语言和LaTeX数学表达式的组合来解析问题和生成答案,没有明确的基础数学结构。
最重要的是,模型生成的答案没法自动验证,即使最终答案的只是一个数值或者符号,可以通过匹配字符来验证,模型也可以通过不正确的推理步骤得出最终的正确答案。如果不是人来阅卷的话,很难发现其中的端倪。而这种限制在定理证明的形式化方法中是不存在的。
不过非形式化方法的一个优点是它可以应用于比较灵活、不适合形式化描述的问题。
Minerva还公开了模型的输入样例和预测结果,包括物理、生物、化学、天文学、机器学习等多个领域。

下面是几道「机器学习」的问题。
以下哪一项是修剪决策树的主要原因?
A. 减少测试时的计算时间
B. 节省保存决策树的空间
C. 在训练集上的错误率更低
D. 避免在训练集上过拟合

模型返回的答案为「决策树剪枝是为了防止在训练集过拟合」,所以答案为D
还有一些概念上的题目:out-of-distribtion detection换种说法叫什么?
A. 异常检测
B. One-Class检测
C. train-test 失配稳健性
D. 背景检测

模型返回的答案为「Out-of-distribution检测任务就是找出那些不属于任何一个训练类别的样例,也称为异常检测」
不过稍难一些、不是很直观的题来说,模型还是很难回答正确,比如问题是:在指定数据集上构建一个线性回归模型,发现有一个特征的权重系数值有一个很高的负值,说明什么?
A. 该特征对模型有很强的影响(应该保留)
B. 该特征对模型没什么影响(应该删除)
C. 没有额外信息的话很难知道该特征的重要性
D. 什么也无法确定

模型返回的答案为「该特征对模型有一个负面影响」,所以答案为B,但实际上答案为C
要是这些题当面试题,你能答对吗?
参考资料:
http://ai.googleblog.com/2022/06/minerva-solving-quantitative-reasoning.html



