
随着规模的扩大,语言模型既表现出定量的改进,又表现出新的定性能力。尽管它们具有潜在的变革性影响,但这些新能力的特征还不明确。为了指导未来的研究,为颠覆性的新模型能力做好准备,并改进社会有害影响,我们了解语言模型现在和近期的能力和局限性是至关重要的。为了解决这一挑战,我们引入了超越模仿游戏基准(BIG-bench)。BIG-bench目前包含204项任务,由来自132个机构的442位作者贡献。任务的主题是多样化的,从语言学、儿童发展、数学、常识推理、生物学、物理学、社会偏见、软件开发等等。BIG-bench专注于那些被认为超出当前语言模型能力的任务。我们评估了OpenAI的GPT模型、Google内部密集transformer架构以及BIG-bench上switch式的稀疏transformer 的行为,这些模型的大小涵盖了数百万到千亿的参数。此外,为了提供强有力的基准,一组人类专家评分人员执行了所有任务。研究结果包括: 模型性能和校准都随着规模的增加而提高,但绝对值较差(与评分者的性能相比); 跨模型类的性能非常相似,尽管这得益于稀疏性;可预测的逐步提高的任务通常涉及大量知识或记忆成分,而在临界尺度上表现出“突破性”行为的任务通常涉及多个步骤或成分,或脆性指标;在模棱两可的环境中,社会偏见通常会随着规模的增加而增加,但这可以通过提示来改善。
项目地址:
https://github.com/google/BIG-bench/#creating-a-programmatic-task
生成语言模型的核心能力是生成文本序列最可能的延续。这个看似简单的技能其实非常普遍。任何可以通过文本指定和执行的任务都可以被框定为文本延续。这包括广泛的认知任务,包括可以通过聊天或电子邮件解决的任务,例如,在一个网络论坛。最近的一个共识是,随着生成语言模型变得更大,并接受更多数据的训练,它们在可预测的方式中表现得更好。它们在测试集上的交叉熵在模型大小、训练数据大小和训练中使用的计算量方面表现为幂律(Hestness et al., 2017; 2019; Rosenfeld et al., 2019; Kaplan et al., 2020; Brown et al., 2020)。在这一可预测的改进的推动下,研究人员现在已经将语言模型扩展到1万亿以上的参数(Fedus et al., 2021),我们预计模型在未来几年内将增长一个数量级。我们还期望通过架构和训练方法的改进来持续提高性能。
数量的海量增加通常会给系统注入新行为。在科学领域,规模的扩大往往需要或使新颖的描述成为可能,甚至开创新的领域(Anderson, 1972)。随着语言模型规模的增加,它们同样展示了定性的新行为(Zhang et al., 2020e)。例如,他们表现出了编写计算机代码的初级能力(Hendrycks et al., 2021a; Chen et al., 2021; Austin et al., 2021; Schuster et al., 2021b; Biderman & Raff, 2022),诊断医疗条件(Rasmy et al,2021),以及语言之间的翻译(Sutskever et al,2014),尽管目前他们在所有这些事情上的能力都不如拥有有限领域知识的人类。这些突破能力(Ganguli et al,2022年)已经通过经验观察到,但我们无法可靠地预测新突破发生的规模。我们可能还没有意识到已经发生的其他突破,但还没有在实验中被注意到。语言模型在变大的过程中发生的量变和质变具有潜在的变革性(Bommasani et al., 2021; Black et al., 2022)。大型语言模型可以增强或取代人类,使其能够完成一系列广泛的任务,这些任务可以用文本响应来构建。它们可能启用全新的应用程序。如果没有适当的介入,他们可能还会将不受欢迎的社会偏见深深嵌入技术堆栈和决策过程中——但如果有适当的介入,他们可能会使决策自动化,减少人为偏见。由于语言模型潜在的变革性影响,我们了解它们的能力和限制,以及随着模型的改进,我们了解这些能力和限制可能如何变化,这是至关重要的。这种认识将直接推动新技术的发展;使我们能够识别并减轻潜在的有害社会影响,从失业到社会偏见的自动化(Bender et al,2021年);使我们能够预测模型行为可能微妙地偏离人类意图的其他方式(Kenton et al,2021年);允许我们将研究精力引向最有前途的方向(Bommasani et al,2021年,第3节);并使我们避免将研究资源投入到可能仅靠规模解决的问题上(Sutton, 2019)。
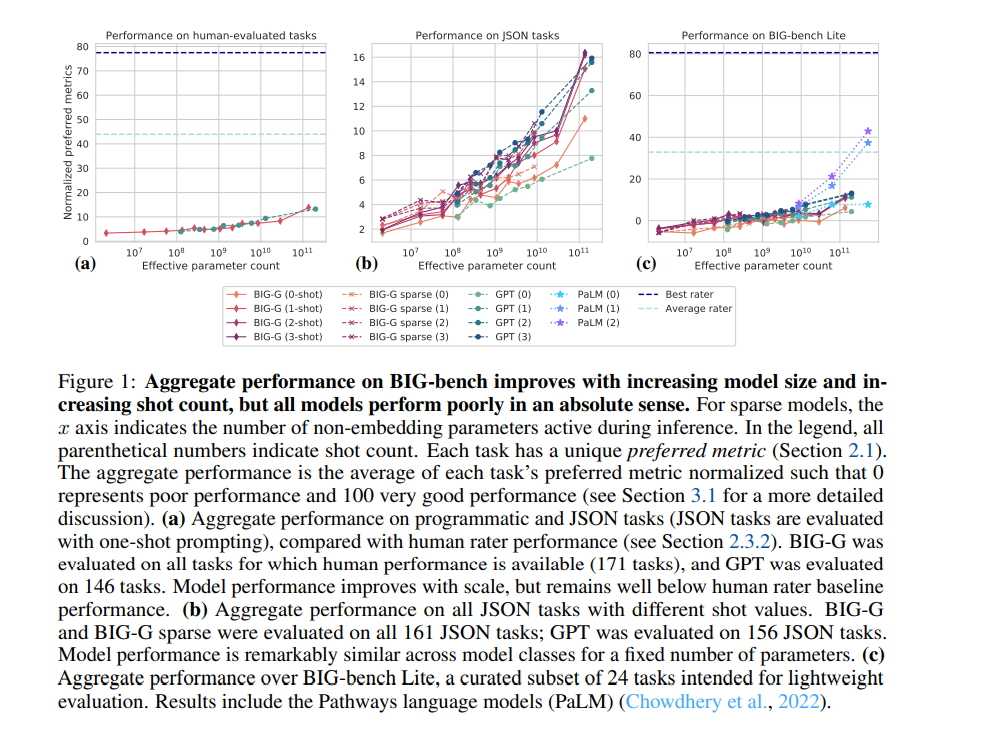
目前的语言建模基准还不足以满足我们理解语言模型的行为和预测它们未来的行为的需求。这些现有基准有几个局限性。首先,许多基准测试的范围有限,主要针对语言模型已经证明一定熟练程度的单一或少数功能。例如,基准测试通常提出的任务是对较窄的领域子集进行编码,如语言理解(See et al., 2017; Hermann et al., 2015; Narayan et al., 2018; Koupaee & Wang, 2018; Rush et al., 2015; Graff et al., 2003),或琐碎问题的回答((Joshi et al., 2017; Kwiatkowski et al., 2019; Rajpurkar et al., 2016)。因为它们的目标范围很窄,而且因为它们的目标通常是语言模型已经知道要执行的对象,所以它们不适合识别语言模型可能随着规模的增加而开发的新的和意想不到的功能,或者描述当前功能的广度。其次,最近的语言建模基准测试的有用寿命通常很短(MartínezPlumed et al., 2021)。当这些基准达到与人类相当的性能时,它们往往要么停止,要么被替换,要么通过在一种“挑战-解决-替换”评估动态(Schlangen, 2019)或“数据-解决-补丁”对抗性基准共同进化(Zellers等人,2019a)中加入更有挑战性的基准来扩展。例如,通用SuperGLUE基准测试(Wang et al., 2019a)在产生不到18个月的时间内就实现了超人的性能(图2)。如此短的有用寿命可能是由于这些基准测试的范围有限,这使得它们无法包括远远超出当前语言模型能力的任务。最后,许多当前的基准测试使用的是通过人为标记收集的数据,而不是由专家或任务作者执行的。与这种数据标签相关的成本和挑战极大地影响了所选任务的难度,因为许多任务需要易于解释和执行。这通常会导致更容易的任务,噪声、正确性和分布问题会降低结果的可解释性(Bowman & Dahl, 2021)。
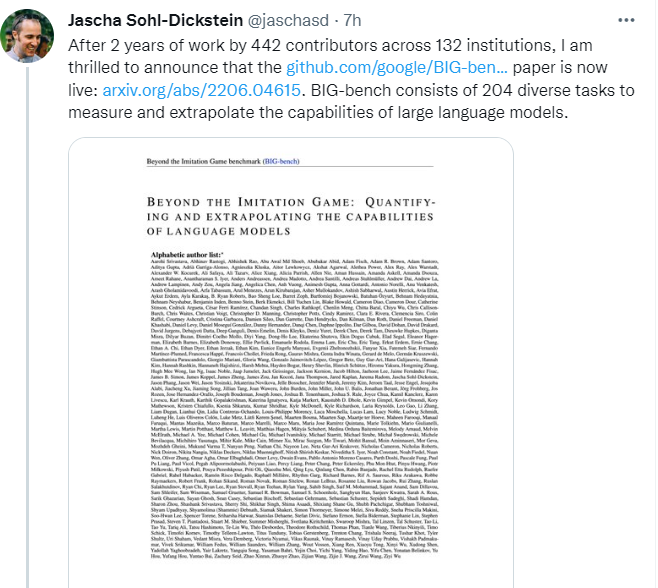
考虑到预测大型语言模型的潜在变革性影响的重要性,以及当前基准测试的局限性,我们引入了一个大规模、极其困难和多样化的基准测试。然后我们在这个基准上测量模型的性能。为了衡量模型性能是否与人的性能有很大的区别,我们提供了一个人工评估基准和专家对这组不同任务的人工评估。此外,模型是跨尺度测量的,以便于简单的尺度外推,在这个尺度上,它们可能与人类评估者没有区别。为了向艾伦·图灵的模仿游戏(图灵,1950)致敬,因为我们的目标是提取模型行为的信息,而不是从模型是否与人类不同的二元判断中获得的信息,我们把这个基准称为超越模仿游戏基准,或BIG-bench。我们还介绍了精简版的BIG-bench(第2.2节),它包含24个任务,用于轻量级评估。该基准是在GitHub上公开开发的,贡献者通过GitHub拉请求的方式添加任务。通过对拉请求的讨论,对提议的任务进行同行评审。为了激励贡献,所有接受任务的作者都有机会成为这篇介绍BIG-bench的论文的共同作者。我们使用这个基准来分析密集和稀疏变压器模型,从谷歌和OpenAI,跨越6个数量级的模型规模。我们特别感兴趣的是预测语言模型未来的功能。因此,在我们的分析中,我们不关注任何单一模型的性能,而是关注性能如何随着模型规模的变化而变化。对于选择的任务,我们研究特定的模型能力如何随着规模的发展而发展。图1显示了在所有BIG-bench任务中超过5个数量级的模型的总体性能。


