OpenAI用GPT-3与小学生比数学,水平达90%!60亿小模型性能翻倍,追平1750亿大模型

来源:新智元
本文约3005字,建议阅读6分钟
本文介
绍
了OpenAI训练了一个系统可以解决小学数学问题,目前该方法在同样的问题上可以拿到55分,已经达到了人类小学生90%左右的水平。

【导读】近日,OpenAI训练了一个系统可以解决小学数学问题。一个9-12岁的小孩子在测试中得分为60分,而OpenAI的新方法在同样的问题上可以拿到55分,已经达到了人类小学生90%左右的水平!
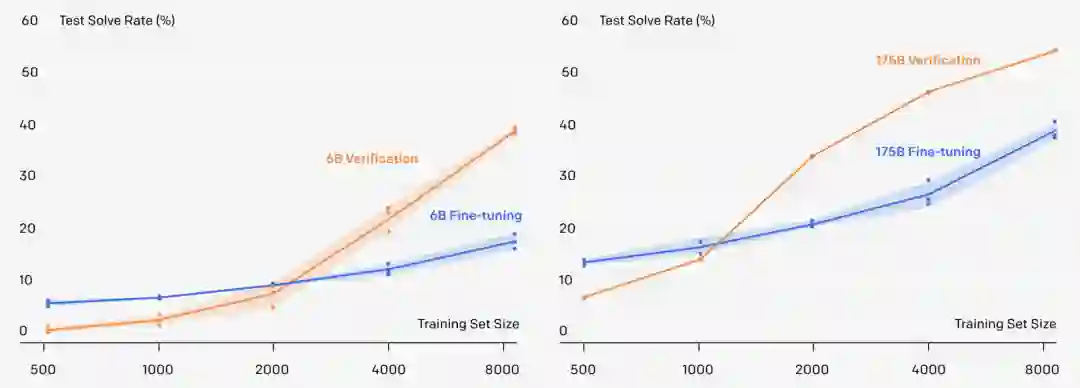
OpenAI的GPT-3以1750亿参数的「大」这一特点,让人印象颇深。


验证器:吃一堑,长一智
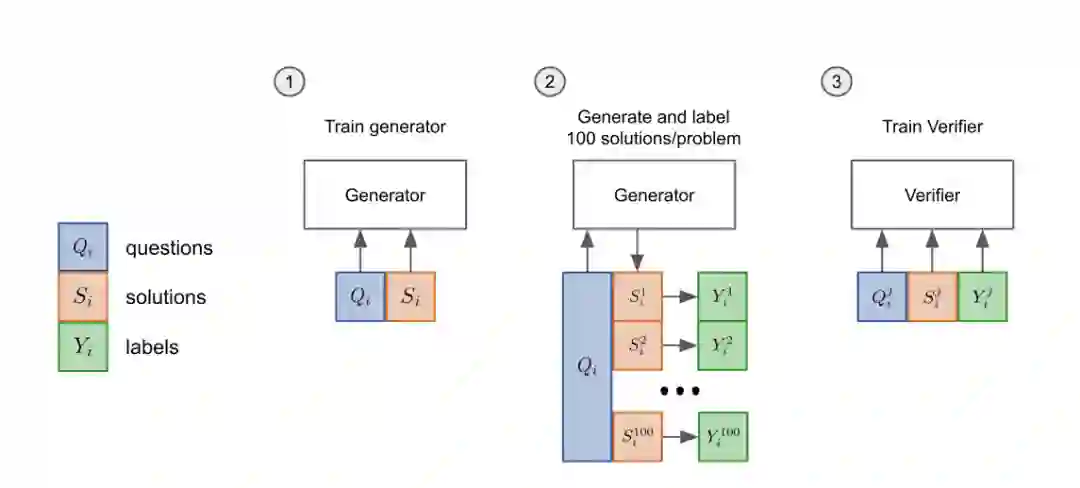
-
先把模型的「生成器」在训练集上进行2个epoch的微调。 -
从生成器中为每个训练问题抽取100个解答,并将每个解答标记为正确或不正确。 -
在数据集上,验证器再训练单个epoch。
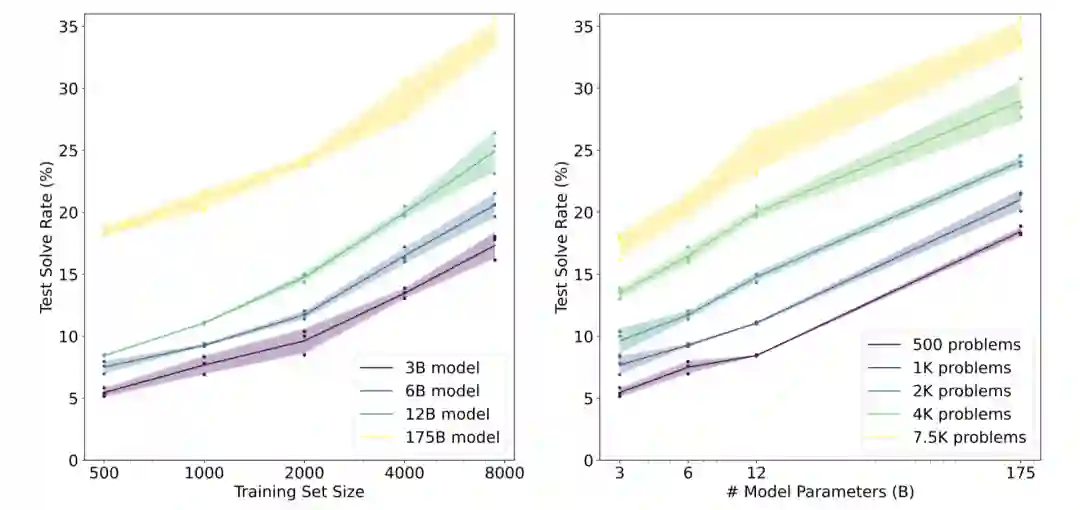
GSM8K数据集
-
高质量:GSM8K中的问题都是人工设计的,避免了错误问题的出现。
-
高多样性:GSM8K中的问题都被设计得相对独特,避免了来自相同语言模板或仅在表面细节上有差异的问题。
-
中等难度:GSM8K中的问题分布对大型SOTA语言模型是有挑战的,但又不是完全难以解决的。这些问题不需要超出早期代数水平的概念,而且绝大多数问题都可以在不明确定义变量的情况下得到解决。
-
自然语言解决方案:GSM8K中的解决方案是以自然语言而不是纯数学表达式的形式编写的。模型由此生成的解决方案也可以更容易被人理解。此外,OpenAI也期望它能阐明大型语言模型内部独白的特性。

举个「栗子」













登录查看更多
相关内容
Arxiv
13+阅读 · 2021年3月10日




相关VIP内容
相关资讯
相关论文
Arxiv
13+阅读 · 2021年3月10日