学界 | 哥伦比亚大学与Adobe提出新方法,可将随机梯度下降用作近似贝叶斯推理
选自arXiv
机器之心编译
参与:吴攀
伦比亚大学和 Adobe 的三位研究者近日在 arXiv 上的一篇论文《用作近似贝叶斯推理的随机梯度下降(Stochastic Gradient Descent as Approximate Bayesian Inference)》提出了一种可将随机梯度下降用作近似贝叶斯推理的新方法。该论文共做出了 5 项贡献。在 Reddit 上有人对此研究评论说:「随机梯度下降总是比你想像的更强大。」机器之心对本论文进行了摘要介绍,原论文可点击文末「阅读原文」查阅。

具有恒定的学习率的随机梯度下降(constant SGD)可以模拟具有静态分布的马尔可夫链。基于这个观点,我们得到了一些新结果。(1) 我们表明 constant SGD 可以被用作近似贝叶斯后验推理算法(approximate Bayesian posterior inference algorithm)。具体而言,我们表明可以如何调整 constant SGD 的调优参数来最好地匹配一个后验的静态分布,以最小化这两个分布之间的 Kullback-Leibler 散度。(2) 我们表明 constant SGD 能产生一个新的变分 EM 算法,该算法可以在复杂的概率模型中对参数进行优化。(3) 我们还提出了用于采样的带有动量的 SGD(SGD with momentum),并且给出了相应地调整阻尼系数的方法。(4) 我们分析了 MCMC 算法。对于 Langevin Dynamics 和 Stochastic Gradient Fisher Scoring,我们量化了其由于有限学习率而导致的近似误差。最后 (5),我们使用这个随机过程的观点简要地证明了为什么 Polyak 平均是最优的。基于这一思想,我们提出了一种可扩展的近似 MCMC 算法——平均随机梯度采样器(Averaged Stochastic Gradient Sampler)。
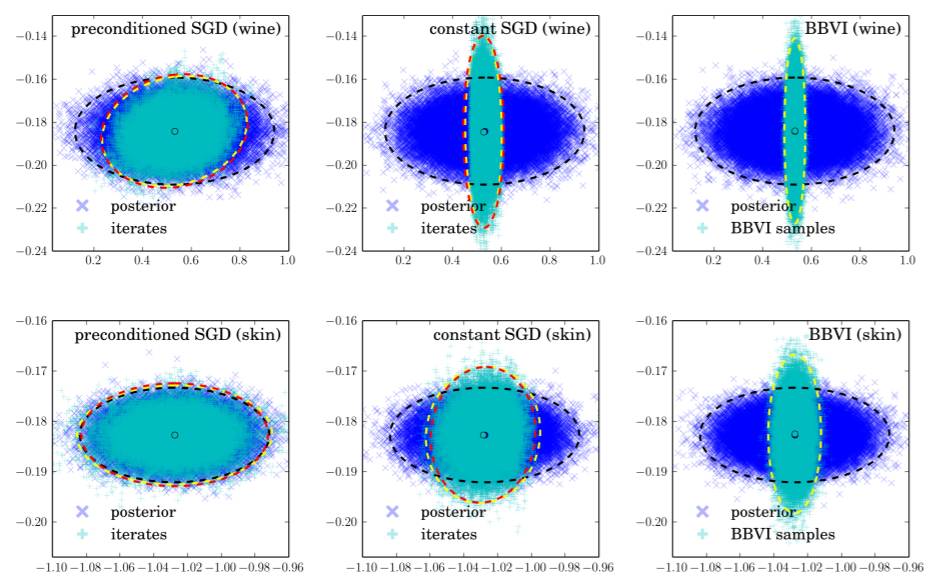
图 1:后验分布 f (θ) ∝ exp {−NL (θ)}(蓝色)与 SGD 的迭代的静态采样分布 q(θ)(青色)或基于再参数化梯度的黑箱变分推理(BBVI:black box variational inference)。行:(上)线性回归,(下)logistic 回归,在第 6 节讨论。列:(左)full-rank preconditioned constant SGD,(中)constant SGD,(右)BBVI。我们给出了在该后验的最小和最大主成分上的投射。这幅图还给出了在 Ornstein-Uhlenbeck 过程(Eq. 13)中该后验的经验协方差(3 标准差)(黑色)、样本的协方差(黄色)和它们的预测(红色)
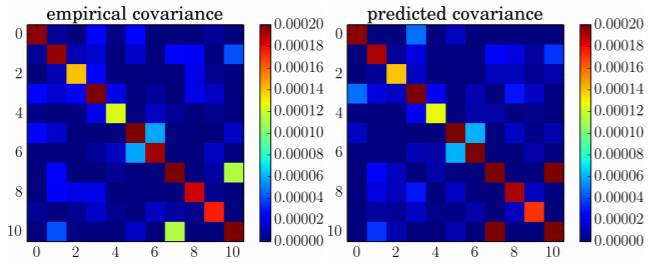
图 2:随机梯度下降迭代的经验协方差和预测协方差,其中预测基于 Eq.13。我们在葡萄酒质量数据集上使用了线性回归,详见 6.1 节。

算法 1:迭代平均随机梯度下降采样器(IASG)
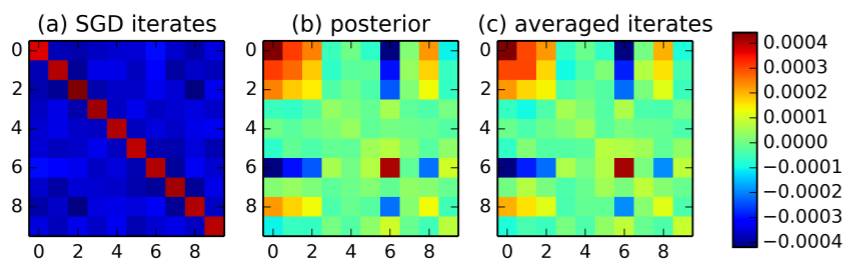
图 3:在线性回归上的迭代平均(iterate averaging),其中我们生成类似于模型生成的人造数据。(a) 给出了该 SGD 迭代的经验协方差,而 (c) 给出了带有最优的时间窗口选择的平均迭代。其结果得到的协方差非常类似于 (b) 中的真实后验协方差。这表明迭代平均有可能得到后验采样。
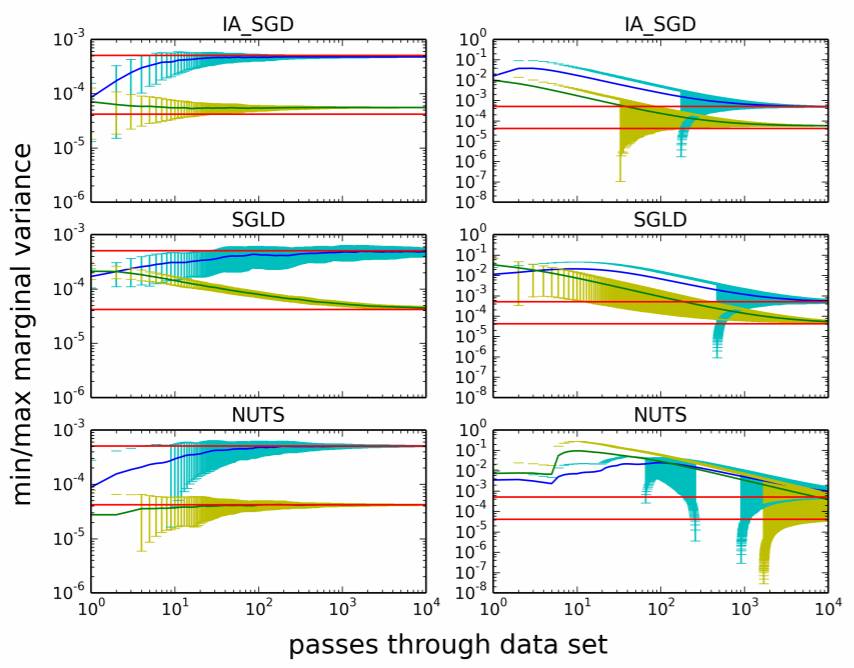
图 4:IASG(顶行)、SGLD(中行)和 NUTS(底行)在线性回归上的收敛速度比较。该图分别给出了最小(黄色)和最大(蓝色)的后验边界方差作为迭代的函数,其以通过数据的次数作为度量。误差柱表示一个标准差。红色实线表示 ground truth。左图是以后验最大值初始化的,而右图是随机初始化的。
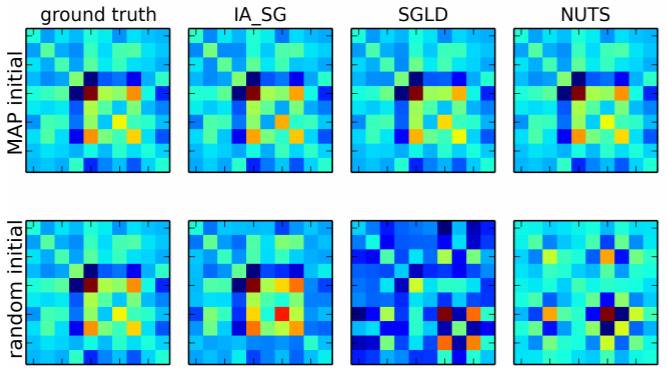
图 5:用不同的方法所估计的后验协方差,参见图 4。顶行是用后验最大值对采样器进行初始化所得到的结果。底行是随机初始化的结果。对于 MAP 初始化,所有的采样器都可以找到对后验的一个良好估计。当随机初始化时,IASG 的表现优于 NUTS 和 SGLD。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com


