让你的声音动起来,人声驱动合成逼真的视频人像
点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
标题:Photorealistic Audio-driven Video Portraits
作者:Xin Wen, Miao Wang, Christian Richardt, Ze-Yin Chen, Shi-Min Hu
来源:Transactions on Visualization and Computer Graphics, 2020.
主页:https://richardt.name/publications/audio-dvp
编译:realcat

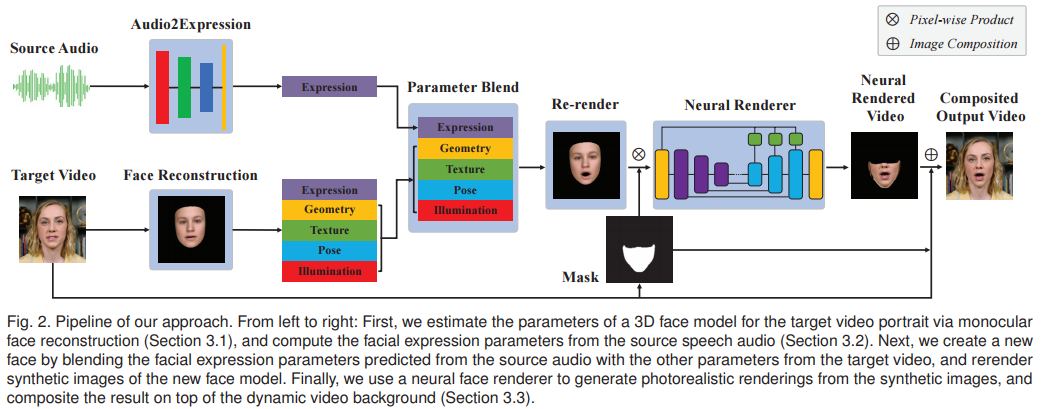
视频人像在各种应用中都很常见,如视频会议、新闻广播、虚拟教育和培训等。本文提出了一种新的方法,由人的声音自动驱动,给输入的人像视频合成逼真的视频人像。这项任务的主要挑战是如何从输入的语音音频中幻化出可信的、逼真的面部表情。为了解决这个挑战,本文采用了一个由几何形状、面部表情、光照等表示的参数化三维人脸模型,并学习从音频特征到模型参数的映射。
效果直接看视频:
然后,将从原始目标视频中计算出的表情参数替换为预测参数,并重新演绎人脸。最后,通过神经人脸渲染器从重演的合成人脸序列中生成一个逼真的视频人像。本文方法的一个吸引人的特点是对各种输入语音音频的泛化能力,包括来自文本到语音软件的合成语音音频。大量的实验结果表明,本文的方法优于之前的通用音频驱动的视频人像方法。



交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
投稿、合作也欢迎联系:simiter@126.com

扫描关注视频号,看最新技术落地及开源方案视频秀 ↓





