谷歌AI:根据视频生成深度图,效果堪比激光雷达

新智元推荐
新智元推荐
来源:图灵TOPIA(ID:turingtopia)
编辑:刘静
【新智元导读】从视频中估计3D结构和相机运动是计算机视觉中的一个关键问题,这个技术在自动驾驶领域有着广阔的工业应用前景。今日,谷歌AI与机器人实验室联合发布的最新成果:无需相机参数、单目、以无监督学习的方式从未标记场景视频中搞定深度图,效果堪比激光雷达。
目前自动驾驶的核心技术是LiDAR(激光雷达),一种运用雷达原理,采用光和激光作为主要传感器的汽车视觉系统。LiDAR传感器赋予了自动驾驶汽车能够看到周边环境的“双眼”,激光雷达技术越先进,视觉感知的精准程度越高,这是自动驾驶得以实现的底层技术基础。
但是最近几年,放在摄像头上的深度学习研究,发展很蓬勃。相比之下, 虽然激光雷达 (LiDAR)的数据有诸多优点,但相关学术进展并不太多。相机+数据+神经网络的组合,正在迅速缩小与LiDAR的能力差距。
无需相机参数、单目、以无监督学习的方式从未标记场景视频中搞定深度图!
这是谷歌AI与机器人实验室联合发布的最新研究结果,效果可媲美LiDAR。
深度图像(depth image)也被称为距离影像(range image),由相机拍摄,是指将从图像采集器到场景中各点的距离(深度)作为像素值的图像,它直接反映了景物可见表面的几何形状。单位为mm,效果参考下图:
在场景视频景深学习领域,谷歌AI和机器人实验室联合公布了三项最新研究突破:
第一,证明了可以以一种无监督的方式训练深度网络,这个深度网络可以从视频本身预测相机的内在参数,包括镜头失真(见图1)。
第二,在这种情况下,他们是第一个以几何方式从预测深度直接解决遮挡的问题。
第三,大大减少了处理场景中移动元素所需的语义理解量:只需要一个覆盖可能属于移动对象的像素的单个掩码,而不是分割移动对象的每个实例并跨帧跟踪它。

图1:从未知来源的视频中学习深度的方法的定性结果,通过同时学习相机的外在和内在参数来实现。由于该方法不需要知道相机参数,因此它可以应用于任何视频集。所有深度图(在右侧可视化,作为差异)都是从原始视频中学习而不使用任何相机内在函数。从上到下:来自YouTube8M的帧,来自EuRoC MAV数据集,来自Cityscapes和来自KITTI的帧。
推特网友对此不吝赞美:“这是我见过的最令人印象深刻的无监督结果之一。来自未标记视频的深度图对于自动驾驶非常有用:)“
以下是论文具体内容:
从视频中估计3D结构和相机运动是计算机视觉中的一个关键问题,这个技术在自动驾驶领域有着广阔的工业应用前景。
解决该问题的传统方法依赖于在多个连续帧中识别场景中的相同点,并求解在这些帧上最大程度一致的3D结构和相机运动。
但是,帧之间的这种对应关系只能针对所有像素的子集建立,这导致了深度估计不确定的问题。与通常处理逆问题一样,这些缺口是由连续性和平面性等假设填充的。
深度学习能够从数据中获得这些假设,而不是手工指定这些假设。在信息不足以解决模糊性的地方,深度网络可以通过对先前示例进行归纳,以生成深度图和流场。
无监督方法允许单独从原始视频中学习,使用与传统方法类似的一致性损失,但在训练期间对其进行优化。在推论中,经过训练的网络能够预测来自单个图像的深度以及来自成对或更长图像序列的运动。
随着对这个方向的研究越来越有吸引力,很明显,物体运动是一个主要障碍,因为它违反了场景是静态的假设。已经提出了几个方向来解决该问题,包括通过实例分割利用对场景的语义理解。
遮挡是另一个限制因素,最后,在此方向的所有先前工作中,必须给出相机的内在参数。这项工作解决了这些问题,因此减少了监督,提高了未标记视频的深度和运动预测质量。
首先,我们证明了可以以一种无监督的方式训练深度网络,这个深度网络从视频本身预测相机的内在参数,包括镜头失真(见图1)。
其次,在这种情况下,我们是第一个以几何方式从预测深度直接解决遮挡的问题。
最后,我们大大减少了处理场景中移动元素所需的语义理解量:我们需要一个覆盖可能属于移动对象的像素的单个掩码,而不是分割移动对象的每个实例并跨帧跟踪它。
这个掩模可能非常粗糙,实际上可以是矩形边界框的组合。获得这样的粗糙掩模是一个简单得多的问题,而且与实例分割相比,使用现有的模型可以更可靠地解决这个问题。
除了这些定性进展之外,我们还对我们的方法进行了广泛的定量评估,并发现它在多个广泛使用的基准数据集上建立了新的技术水平。将数据集汇集在一起,这种能力通过我们的方法得到了极大的提升,证明可以提高质量。
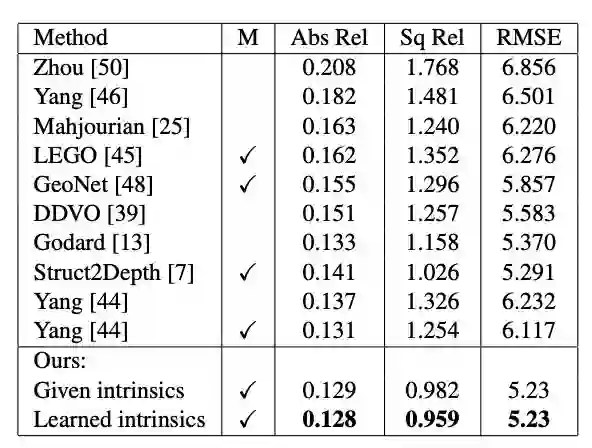
表1:总结了在KITTI上训练的模型和评估结果,使用给定相机内建和学习相机内建两种方式来评估我们方法的深度估计,结果显而易见,我们获得了当前最佳SOTA。
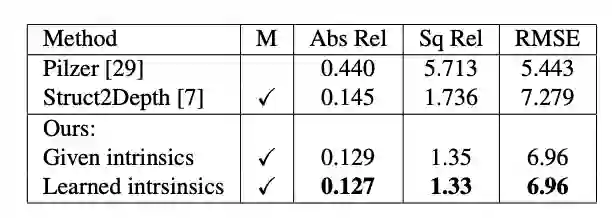
表2:总结了在Cityscapes上训练和测试的模型的评估结果,我们的方法优于以前的方法,并从学习的内建中获益。
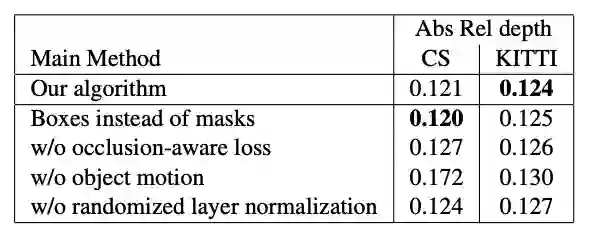
表3:深度估计的消融实验。在所有实验中,训练集是Cityscapes(CS)和KITTI组合,我们分别在Cityscapes(CS)和KITTI(Eigen partition)上测试模型。每行代表一个实验,其中与主方法相比进行了一次更改,如“实验”行中所述。数字越小越好。
除了这些定性的进步,我们对我们的方法进行了广泛的定量评估,发现它在多个广泛使用的基准数据集上建立了一个新的技术状态。将数据集集中在一起,这种方法大大提高了数据集的质量。
最后,我们首次演示了可以在YouTube视频上学习深度和相机内在预测,这些视频是使用多个不同的相机拍摄的,每个相机的内建都是未知的,而且通常是不同的。

来自YouTube8M收集的图像和学习的视差图。
《场景视频景深学习——非特定相机单眼图片景深无监督学习》
我们提出了一种新颖的方法,仅使用相邻视频帧的一致性作为监督信号,用于同时学习单眼视频的深度,运动,物体运动和相机内建。与先前的工作类似,我们的方法通过将可微变形应用于帧,并将结果与相邻结果进行比较来学习,但它提供了若干改进:我们直接使用在训练期间预测的深度图,以几何和可微的方式处理遮挡。我们介绍了随机层标准化,一种新颖的强大正则化器,并考虑了目标相对于场景的运动。据我们所知,我们的工作是第一个以无监督的方式从视频中学习相机固有参数(包括镜头失真)的工作,从而使我们能够从规模未知原点的任意视频中提取准确的深度图和运动信息。
我们在Cityscapes,KITTI和EuRoC数据集上评估我们的结果,建立深度预测和测距的新技术水平,并定性地证明,深度预测可以从YouTube上的一系列视频中学到。

论文地址:
https://arxiv.org/pdf/1904.04998.pdf
本文经授权转载自微信公众号:图灵TOPIA,ID:turingtopia
更多阅读
新智元春季招聘开启,一起弄潮AI之巅!
岗位详情请戳:
.png")

【加入社群】
新智元AI技术+产业社群招募中,欢迎对AI技术+产业落地感兴趣的同学,加小助手微信号:aiera2015_2 入群;通过审核后我们将邀请进群,加入社群后务必修改群备注(姓名 - 公司 - 职位;专业群审核较严,敬请谅解)。



