手把手 | 生成式对抗网络(GAN)之MNIST数据生成
本文作者 天雨粟,原载于知乎,数说工作室 经授权发布。
【数说君1分钟导读】
2014年,机器学习三大巨头之一 Ian Goodfellow 发表论文 Generative Adversarial Nets,生成式对抗网络 GAN 面世。
GAN 是一种生成模型,顾名思义就是生成某个东西,比如图像、文本,也因此被应用于图像复原(去马赛克,你懂)、自动聊天模型等领域。
GAN 其实就两个部分:生成器和判别器。生成器生不断的生成尽可能真实的图像,而判别器尽可能的去识别出图像的真假,两个相互对抗博弈。
本篇文章作者从真实数据入手,用一步一步的代码教大家如何实现GAN。
(新建了一个微信群,主要面向机器学习、人工智能的从业者,有意入群请加数说君微信 ishushuo,备注【学校/公司+研究方向】)
前 言
GAN从2014年诞生以来发展的是相当火热,比较著名的GAN的应用有Pix2Pix、CycleGAN等。本篇文章主要是让初学者通过代码了解GAN的结构和运作机制,对理论细节不做过多介绍。
我们还是采用MNIST手写数据集(不得不说这个数据集对于新手来说非常好用)来作为我们的训练数据,我们将构建一个简单的GAN来进行手写数字图像的生成。
一、认识 GAN
GAN主要包括了两个部分,即生成器generator与判别器discriminator。生成器主要用来学习真实图像分布从而让自身生成的图像更加真实,以骗过判别器。判别器则需要对接收的图片进行真假判别。在整个过程中,生成器努力地让生成的图像更加真实,而判别器则努力地去识别出图像的真假,这个过程相当于一个二人博弈,随着时间的推移,生成器和判别器在不断地进行对抗,最终两个网络达到了一个动态均衡:生成器生成的图像接近于真实图像分布,而判别器识别不出真假图像,对于给定图像的预测为真的概率基本接近0.5(相当于随机猜测类别)。
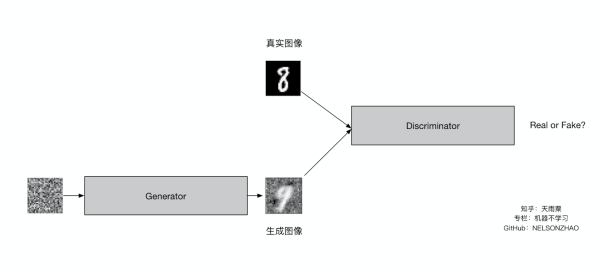
对于GAN更加直观的理解可以用一个例子来说明:
造假币的团伙相当于生成器,他们想通过伪造金钱来骗过银行,使得假币能够正常交易,
而银行相当于判别器,需要判断进来的钱是真钱还是假币。
因此假币团伙的目的是要造出银行识别不出的假币而骗过银行,银行则是要想办法准确地识别出假币。
因此,我们可以将上面的内容进行一个总结。给定真=1,假=0,那么有:
对于给定的真实图片(real image),判别器要为其打上标签1;
对于给定的生成图片(fake image),判别器要为其打上标签0;
对于生成器传给辨别器的生成图片,生成器希望辨别器打上标签1。
有了上面的直观理解,下面就让我们来实现一个GAN来生成手写数据吧!还有一些细节会在代码部分进行介绍。
说明
TensorFlow 1.0
Python 3
Jupyter Notebook
GitHub地址:https://github.com/NELSONZHAO/zhihu/tree/master/mnist_gan
建议将代码pull下来,有部分代码实现没有写在文章中。
二、代码部分
(1)数据加载与查看
数据我们使用 TensorFlow 中给定的MNIST数据接口。
在构建模型之前,我们首先来看一下我们需要完成的任务:
Inputs
generator
discriminator
定义参数
loss & optimizer
训练模型
显示结果
(2)输入inputs
输入函数主要来定义真实图片与生成图片两个 tensor。

(3)定义生成器
我们的生成器结构如下:
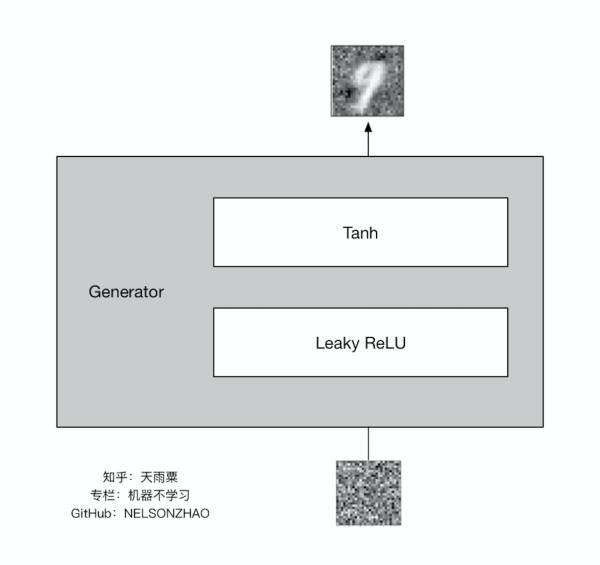
我们使用了一个采用 Leaky ReLU 作为激活函数的隐层,并在输出层加入 tanh 激活函数。
下面是生成器的代码。注意在定义生成器和判别器时,我们要指定变量的scope,这是因为GAN中实际上包含生成器与辨别器两个网络,在后面进行训练时是分开训练的,因此我们要把scope定义好,方便训练时候指定变量。
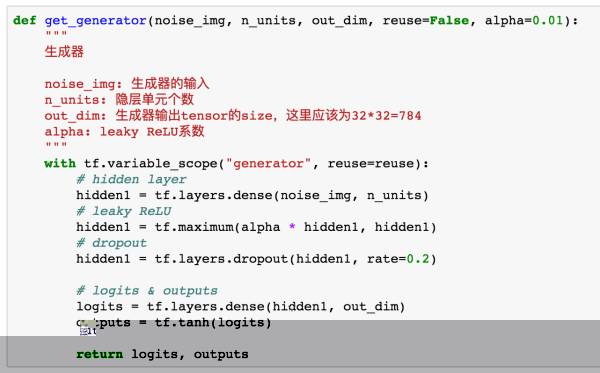
在这个网络中,我们使用了一个隐层,并加入dropout防止过拟合。通过输入噪声图片,generator输出一个与真实图片一样大小的图像。
在这里我们的隐层激活函数采用的是 Leaky ReLU(中文不知道咋翻译),这个函数在 ReLU 函数基础上改变了左半边的定义。
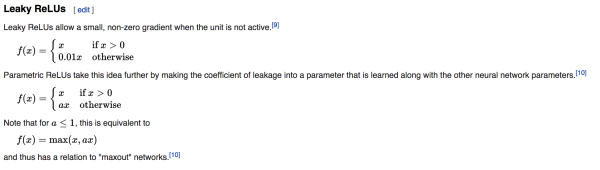
图片来自维基百科。Andrej Karpathy 在 CS231n 中也提到有模型通过这个函数取得了不错的效果。
由于 TensorFlow 中没有这个函数的实现,在这里我们通过函数定义实现了 Leaky ReLU,其中 alpha 是一个很小的数。在输出层我们使用 tanh 函数,这是因为 tanh 在这里相比 sigmoid 的结果会更好一点
(在这里要注意,由于生成器的生成图片像素限制在了 (-1, 1) 的取值之间,而 MNIST 数据集的像素区间为[0, 1],所以在训练时要对 MNIST 的输入做处理,具体见训练部分的代码)
到此,我们构建好了生成器,它通过接收一个噪声图片输出一个与真实图片一样size的图像。
(4)定义判别器
判别器的结构如下:
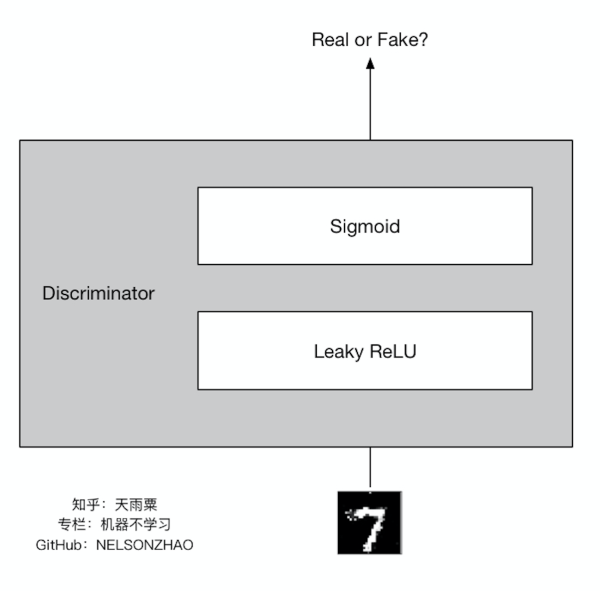
判别器接收一张图片,并判断它的真假,同样隐层使用了 Leaky ReLU,输出层为1个结点,输出为1的概率。代码如下:

在这里,我们需要注意真实图片与生成图片是共享判别器的参数的,因此在这里我们留了reuse接口来方便我们后面调用。
(5)定义参数
img_size是我们真实图片的size=32*32=784。

smooth是进行Label Smoothing Regularization 的参数,在后面会介绍。
(6)构建网络
接下来我们来构建我们的网络,并获得生成器与判别器返回的变量。

我们分别获得了生成器与判别器的logits和outputs。注意真实图片与生成图片是共享参数的,因此在判别器输入生成图片时,需要reuse参数。
(7)定义Loss和Optimizer
有了上面的logits,我们就可以定义我们的loss和Optimizer。在这之前,我们再来回顾一下生成器和判别器各自的目的是什么:
对于给定的真实图片,辨别器要为其打上标签1;
对于给定的生成图片,辨别器要为其打上标签0;
对于生成器传给辨别器的生成图片,生成器希望辨别器打上标签1。
我们来把上面这三句话转换成代码:

d_loss_real对应着真实图片的loss,它尽可能让判别器的输出接近于1。
在这里,我们使用了单边的Label Smoothing Regularization,它是一种防止过拟合的方式,在传统的分类中,我们的目标非0即1,从直觉上来理解的话,这样的目标不够soft,会导致训练出的模型对于自己的预测结果过于自信。因此我们加入一个平滑值来让判别器的泛化效果更好。
d_loss_fake对应着生成图片的loss,它尽可能地让判别器输出为0。
d_loss_real与d_loss_fake加起来就是整个判别器的损失。
而在生成器端,它希望让判别器对自己生成的图片尽可能输出为1,相当于它在于判别器进行对抗。
下面我们定义了优化函数,由于GAN中包含了生成器和判别器两个网络,因此需要分开进行优化,这也是我们在之前定义variable_scope的原因。

(8)训练模型
由于训练部分代码太长,我在这里就不贴出来了,请前往我的GitHub下载代码。在训练部分,我们记录了部分图像的生成过程,并记录了训练数据的loss变化。
我们将整个训练过程的loss变化绘制出来:
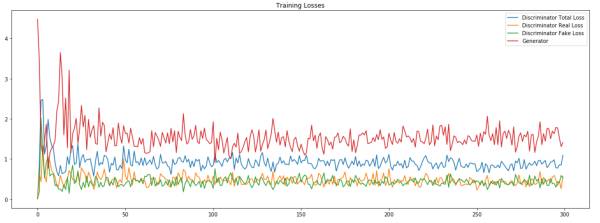
从图中可以看出来,最终的判别器总体loss在1左右波动,而real loss和fake loss几乎在一条水平线上波动,这说明判别器最终对于真假图像已经没有判别能力,而是进行随机判断。
(9)查看过程结果
我们在整个训练过程中记录了25个样本在不同阶段的samples图像,以序列化的方式进行了保存,我们的将samples加载进来。samples的size=epochs x 2 x n_samples x 784,我们的迭代次数为300轮,25个样本,因此,samples的size=300 x 2 x 25 x 784。我们将最后一轮的生成结果打印出来:

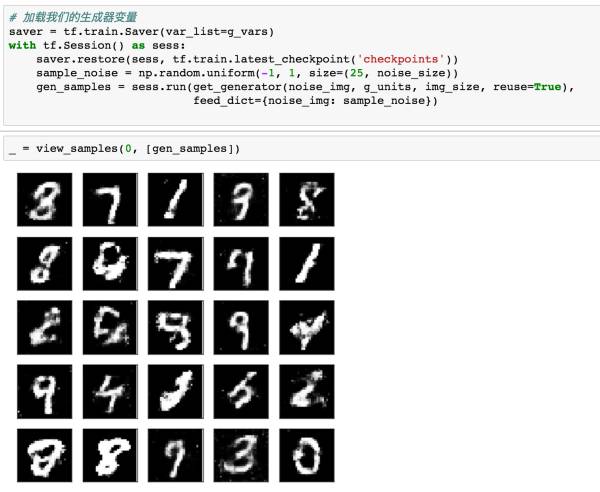
这就是我们的GAN通过学习真实图片的分布后生成的图像结果。
那么有同学可能会问了,我们如果想要看这300轮中生成图像的变化是什么样该怎么办呢?因为我们已经有了samples,存储了每一轮迭代的结果,我们可以挑选几次迭代,把对应的图像打出来:

这里我挑选了第0, 5, 10, 20, 40, 60, 80, 100, 150, 250轮的迭代效果图,在这个图中,我们可以看到最开始的时候只有中间是白色,背景黑色块中存在着很多噪声。随着迭代次数的不断增加,生成器制造“假图”的能力也越来越强,它逐渐学得了真实图片的分布,最明显的一点就是图片区分出了黑色背景和白色字符的界限。
(10)生成新的图片
如果我们想重新生成新的图片呢?此时我们只需要将我们之前保存好的模型文件加载进来就可以啦。
三、总结
整篇文章基于MNIST数据集构造了一个简单的GAN模型,相信小伙伴看完代码会对GAN有一个初步的了解。从最终的模型结果来看,生成的图像能够将背景与数字区分开,黑色块噪声逐渐消失,但从显示结果来看还是有很多模糊区域的。
对于这里的图片处理,相信很多小伙伴会想到卷积神经网络,那么后面我们还会将生成器和判别器改为卷积神经网络来构造深度卷积GAN,它对于图片的生成会取得更好的效果。
《Python量化投资入门》
有这么一个 Python 培训课程,特点是:
从Python从入门到上手,手把手教你从安装到常用工具库的使用。
量化投资从基础到策略编写,手把手教你从获取数据到自动下单。
每位同学在课程结束后,都能有自己的策略并用Python实现自动交易。
课程中配套大量国内量化基金实际案例。
任何问题,可通过文字、语音、远程桌面等方式提问,老师亲自解答。
详细了解、试听课程:长按下图——「识别图中二维码」





