训练数据多少才够用
【导读】机器学习获取训练数据可能很昂贵。因此,机器学习项目中的关键问题是确定实现特定性能目标需要多少训练数据。在这篇文章中,我们将对从回归分析到深度学习等领域的训练数据大小的经验和研究文献结果进行快速但广泛的范围总结。训练数据大小问题在文献中也称为样本复杂性。
作者:Drazen Zaric
本文将介绍以下内容:
呈现回归和计算机视觉任务的经验训练数据大小。
给定统计检验的预期功效,讨论如何确定样本量。
介绍统计理论学习,关于控制训练数据大小的内容。
提供问题的答案:随着训练数据的增长,效果会继续提高吗?在深度学习的情况下会发生什么?
我们将提出一种方法来确定分类中的训练数据大小。
最后,我们将提供一个问题的答案:训练数据的增长是否是处理不平衡数据的最佳方式?
训练数据量的经验界限
让我们首先根据我们使用的模型类型,讨论一些广泛使用的经验方法来确定训练数据的大小:
·计算机视觉:对于使用深度学习的图像分类,经验法则是每类1,000个图像,如果使用预训练模型,这个数字可以显着下降。
假设检验样本大小的确定
假设检验是数据科学家可用于测试群体之间差异。鉴于测试的功效,通常需要确定样本量。
让我们考虑这个例子:一个科技巨头已搬到A市,那里的房价急剧上涨。记者想知道,公寓的新平均价格是多少。考虑到公寓价格在60K的标准差和10K的可接受误差范围,在95%的置信度下,他应该平均多少公寓销售价格,?相应的公式如下所示; N是他需要的样本大小,1.96是对应95%置信度标准正态分布的数字,
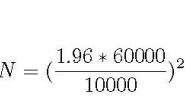
根据上述等式,记者需要考虑约138个公寓价格。
上述公式根据具体测试而变化,但总是包括置信区间,可接受的误差范围和标准偏差的度量。
数据规模训练的统计学习理论
让我们首先介绍着名的Vapnik-Chevronenkis(VC)维度。 VC维度衡量模型的复杂程度;模型越复杂,VC维度越高。在下一段中,我们将介绍一个根据VC指定训练数据大小的公式。
首先,让我们看一个经常用来展示如何计算VC的例子:想象一下,我们的分类器是二维平面中的直线,我们有3个点需要分类。无论这3个点的正/负的组合可能是(所有正数,2个正数,1个正数等),直线可以正确地分类/分离正样本和负样本。因此,线性分类器VC维数至少为3,并且因为我们可以找到4个点的例子,这些点不能用线准确分开,我们说线性的VC分类器正好是3.事实证明,训练数据大小N是VC的函数:
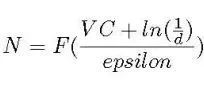
其中d是失败的概率,epsilon是学习错误率。 因此,学习所需的数据量取决于模型的复杂程度。 其副作用是众所周知的用于训练数据的神经网络的贪婪,因为它们具有显着的复杂性。
随着训练数据的增长,效果会继续提高吗? 在深度学习的情况下会发生什么?
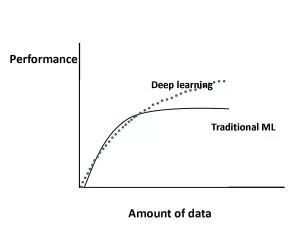
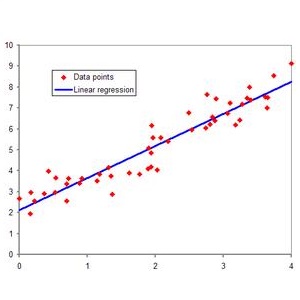
图1显示了在传统机器学习算法和深度学习的情况下,机器学习算法的性能如何随着数据大小的增加而变化。具体而言,对于传统的机器学习算法,性能根据幂律增长,然后达到稳定水平。关于深度学习,有关性能如何随着数据量的增加而扩展的重要研究。图1显示了目前大部分研究的共识;对于深度学习,根据幂律,性能随着数据大小而不断增加。
一种确定分类中训练数据大小的方法论
在分类中,我们通常使用略微不同的学习曲线形式;它是分类准确度与训练数据大小的关系图。确定训练数据大小的方法很简单:确定您的领域的学习曲线的确切形式,然后,只需在图上找到您想要的分类准确度的相应点。例如,用幂律函数表示:
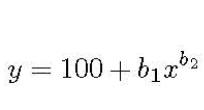
其中y是分类精度,x是训练集,b1,b2对应于学习率和衰减率。 参数根据问题域而变化,并且可以使用非线性回归或加权非线性回归来估计它们。
训练数据的增长是应对不平衡数据的最佳方式吗?

在数据不平衡的情况下,准确度不是分类器性能的最佳度量。原因很直观:让我们假设负类是主导类。然后我们可以通过在大多数时间预测负值来实现高精度。相反,他们建议将精确度和召回率(也称为灵敏度)作为衡量不平衡数据性能的最佳方法。除了上面描述的明显的准确性问题之外,作者还声称,对于不平衡域,测量精度本质上更为重要。例如,在医院报警系统中,高精度意味着当警报响起时,很可能确实存在患者的问题。
通过适当的性能测量,作者比较了Python scikit-learn库中的不平衡校正技术,并简单地使用了更大的训练数据集。具体而言,他们使用K-Nearest邻居和不平衡校正技术对50,000个例子的药物发现相关数据集进行比较,然后在大约100万个例子的原始数据集上与K-NN进行比较。上述包中的不平衡校正技术包括欠采样,过采样和集成学习。作者重复了200次实验。他们的结论简单而深刻:在测量精度和召回方面,没有不平衡校正技术可以匹配添加更多的训练数据。
原文链接:
https://towardsdatascience.com/better-heatmaps-and-correlation-matrix-plots-in-python-41445d0f2bec
-END-
专 · 知
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎登录www.zhuanzhi.ai,注册登录专知,获取更多AI知识资料!
欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!530+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程