【前沿】谷歌提出Sim2Real:让机器人像人类一样观察世界
选自Google AI Blog
作者:Fereshteh Sadeghi
来源:机器之心
参与:张倩、李泽南
由视觉输入控制的机器人非常依赖于固定视角的摄像头,这意味着它们难以在活动的情况下精确完成任务。近日,谷歌研究人员提出了一种结合卷积神经网络和 LSTM 的新架构,可通过强化学习等方法在接收多个摄像头、不同视角图像输入的情况下控制机械臂准确完成任务。研究人员称,新方法可以扩展到任何类型的自动自校准任务上。
人们非常擅长在不将视点调整到某一固定或特殊位置的情况下操纵物体。这种能力(我们称之为「视觉动作整合」)在孩童时期通过在多种情形中操纵物体而习得,并由一种利用丰富的感官信号和视觉作为反馈的自适应纠错机制控制。然而,在机器人学中,基于视觉的控制器很难获得这种能力,目前来看,这种控制器都基于一种用来从固定安装的摄像头读取视觉输入数据的固定装置。在视点大幅变化的情况下快速获取视觉运动控制技能的能力将对自动机器人系统产生重大影响——例如,这种能力对于参与救援工作或在灾区作业的机器人来说尤其必要。
在本周的 CVPR 2018 会议中,谷歌提交了一篇名为《Sim2Real Viewpoint Invariant Visual Servoing by Recurrent Control》的论文。在这篇论文中,谷歌研究了一种新的深度网络架构(包含两个全卷积网络和一个长短期记忆单元),该架构从过去的动作和观测结果中学习自我校准。其视觉适应网络(visually-adaptive network)利用由演示轨迹和强化学习目标组成的各种模拟数据,能够从各种视点控制机械臂到达视觉指示的各种目标,并且独立于摄像机校准。

用物理机械臂实现视觉指示目标的视点不变操作。新方法学习了一种单一策略,通过从截然不同的摄像机视点捕获的感官输入来到达不同的目标。第一行显示了视觉指示的目标。
挑战
从未知视点捕获的单一图像中探索可控自由度(DoF)如何影响视觉运动可能不够明确和具体。确定动作对图像-空间运动的影响并成功地执行预期任务需要一个对过去动作记忆的保持能力进行增强的鲁棒感知系统。要解决这个具有挑战性的问题,必须解决以下基本问题:
如何提供适当的经验,让机器人在模拟终身学习模式的纯视觉观察的基础上学习自适应行为?
如何设计一个将鲁棒感知和自适应控制整合起来并能快速迁移到未见环境中的模型?
为了解决以上问题,研究人员设计了一种新的操纵任务,给一个七自由度机械臂提供一个物体的图像,并命令它在一系列干扰物中拿到特定的目标物体,同时每一次尝试的视点会发生剧烈变化。采用这种做法,研究人员能够模拟复杂行为的学习以及向未知环境的迁移。

用物理机械臂和各种摄像机视点完成到达视觉指示目标的任务。
利用模拟来学习复杂行为
收集机器人经验数据费时费力。在过去的一篇博文(https://ai.googleblog.com/2016/03/deep-learning-for-robots-learning-from.html)中,谷歌展示了如何通过将数据收集和试验分配给多个机器人来扩展学习技能。尽管该方法加快了学习进度,但它仍然不适合扩展到复杂行为的学习中(如视觉自校准),后者需要将机器人置于一个包含各种视点的大型空间中。因此,研究人员选择在模拟环境中学习此类复杂行为,在模拟中可以收集无限的机器人试验数据,并轻松将摄像头移动到各个随机视点。除了在模拟中快速收集数据之外,该方法还可以突破需要在机器人周围安装多个摄像机的硬件限制。

谷歌研究人员在模拟环境中使用域随机化技术来学习可泛化的策略。
为了学习足以迁移到未知环境的视觉鲁棒特征,研究人员使用了 Sadeghi 与 Levine 在 2017 年提出的域随机化技术(即模拟随机化),它可令机器人完全在模拟环境中学习基于视觉的策略,并可以推广到现实世界。该技术在诸如室内导航、物体定位、拾取和放置等多种机器人任务上效果良好。此外,为了学习像自校准这样的复杂行为,研究人员利用模拟能力生成合成示例,并结合强化学习目标来学习鲁棒的机械臂控制器。

使用模拟的 7 自由度机械臂实现视觉指示目标的视点不变操作。新方法学习了一种单一策略,可以通过不同相机视角捕捉的感官输入实现不同的目标。
在控制中解构感知
为了更快地将知识迁移到未知环境中,谷歌研究人员设计了一个深度神经网络,将感知和控制相结合,并同时进行端到端训练,且在必要情况下允许二者分别进行训练。感知与控制之间的分离使迁移到未知环境的难度减小,也让模型更加灵活和高效,因为每个部分(即「感知」和「控制」)都可以单独适应仅有少量数据的新环境。另外,虽然神经网络中的控制部分完全由模拟数据进行训练,但感知部分经过物体边界框收集的少量静态图像补充了输入,无需让物理机器人收集完整的动作序列轨迹。在实践中,谷歌研究人员只用了来自 22 张图像的 76 个对象边界框来微调网络的感知部分。

真实世界的机器人和移动摄像头设置。第一行展示了场景布置,第二行显示了机器人接收到的视觉感官输入。
早期结果
谷歌研究人员在物理机器人和真实物体上测试了视觉适应版本的网络,这些物体的外形与模拟环境中使用的完全不同。在实验中,桌子上会出现一个或两个物体:「见过的物体」(如下图所示)用于视觉适应,实验中使用的是小型静态真实图像集。在视觉适应期间不会看到「未见过的物体」。在测试中,机械臂被引导从各个视点到达视觉指示目标物体。对于双对象实验,第二个对象用于让机械臂产生「混淆」。因为纯模拟网络具有良好的泛化能力(因为它是在域随机技术之上进行训练的),模型的网络架构非常灵活,因此虽然实验中仅收集了非常少量的真实静态视觉数据用于视觉适应,但控制器的表现仍然有了很大提升。
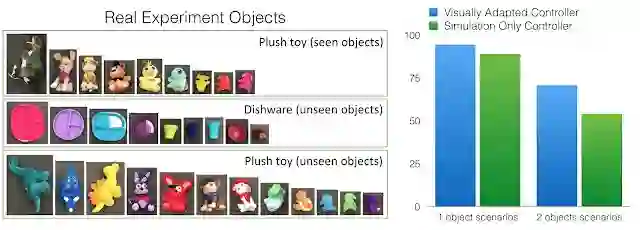
在视觉特征和少量真实图像进行适应之后,模型性能提高了 10% 以上。其中所有用到的真实物体都与模拟中看到的截然不同。
谷歌研究人员认为,学习在线视觉自适应是一个重要而具有挑战性的问题,这一方向的目标是学习到可在多样化和非结构化的现实世界中运行的机器人所需要的通用化策略。新方法可以扩展到任何类型的自动自我校准上。
有关该研究的详细信息可参看以下视频:
原文链接:https://ai.googleblog.com/2018/06/teaching-uncalibrated-robots-to_22.html
☞【学界】OpenPV:中科院研究人员建立开源的平行视觉研究平台
☞【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞【CFP】Virtual Images for Visual Artificial Intelligence
☞【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞【学界】CVPR 2018 | 牛津大学&Emotech首次严谨评估语义分割模型对对抗攻击的鲁棒性
☞【学界】谷歌大脑提出自动数据增强方法AutoAugment:可迁移至不同数据集


