AI眼中的世界什么样?谷歌&OpenAI新研究打开AI视觉的黑箱
机器之心报道
机器之心编辑部
近日,谷歌和 OpenAI 发布新研究,提出一种新方法 Activation Atlas,旨在映射计算机视觉系统用于理解世界的视觉数据,进一步打开 AI 视觉的黑箱。
AI 眼中的世界是什么样的?
这个问题已经困扰研究人员数十年了,近年来这个问题变得更加紧迫。机器视觉系统被部署到生活的各个方面,从医疗健康到自动驾驶。但从机器的视角去「看」世界,去理解为什么它把一个目标归类为行人,而把另一个归类为路标,仍是一个挑战。无法克服这个挑战可能会带来严重甚至致命的后果。有些人会说这已经造成不良影响了,比如自动驾驶方面的事故。
来自谷歌和非盈利实验室 OpenAI 的新研究希望通过映射这些系统用来理解世界的视觉数据,进一步打开 AI 视觉的黑箱。该方法被称为 Activation Atlas,它能够让研究人员分析各个算法的工作原理,不仅可以揭示算法识别的抽象形状、颜色和模式,还展示了它们如何将这些元素组合起来识别特定的目标、动物和场景。
神经网络已经成为图像相关任务的标配了,现已被部署到多个场景中,范围包括在图像库中自动标记照片、自动驾驶系统等。这些机器学习系统已经到处都是了,因为它们比人类不用机器学习直接设计的任何系统都更准确。但由于这些系统的关键细节是在自动训练过程中学到的,因此理解网络如何完成给定任务有时仍旧是个谜。
今日,谷歌与 OpenAI 的研究人员合作撰写并发布了《Exploring Neural Networks with Activation Atlases》。该文介绍了一种新技术,旨在帮助我们解答这个问题:图像分类神经网络从图像中「看到」了什么?激活值图集(Activation atlases)提供了一种观察卷积视觉网络的新方法,对网络隐藏层中的概念进行了一种全局、分层、人类可理解的概述。我们认为激活值图集揭示了一个机器学得的图像字母表——一系列简单的原子概念,它们被反复组合,形成更加复杂的视觉概念。我们还发布了一些 Jupyter notebook 来帮助大家创建自己的激活值图集。
文章地址:https://distill.pub/2019/activation-atlas/
Jupyter notebook:https://github.com/tensorflow/lucid#activation-atlas-notebooks
InceptionV1 视觉分类网络其中一层的激活值图集详细视图。它显示了网络用来给图像分类的很多视觉检测器,如水果状纹理、蜂窝图案和纤维状纹理。
下面的激活值图集是根据卷积图像分类网络 Inceptionv1 构建的,该网络在 ImageNet 数据集上训练得到。通常,给分类网络展示一张图像,然后让网络根据预先决定的 1000 种类别给该图像分配标签,如「培根蛋面」(carbonara)、「呼吸管」(snorkel)、「煎锅」(frying pan)。为此,我们的网络渐进地通过约 10 个层评估图像数据,每层都由数百个神经元组成,这些神经元在不同类型的图像块上被不同程度地激活。某一层的某个神经元可能对狗耳朵做出积极反应,另一层的某个神经元可能对高对比度垂直线做出积极反应。
激活值图集是通过从一百万张图像中收集神经网络每个层中的内部激活反应制成的。这些激活由一组复杂的高维向量表示,并通过 UMAP 被投影为有用的 2D 布局。UMAP 是一种降维技术,能够保留原始高维空间的一些局部结构。
它负责组织激活向量,但我们还需要将其聚合成更易于管理的数量——全部激活层太多了,无法一目了然。为此,我们在创建的 2D 布局上绘制网格。对于网格中的每个单元格,我们将该单元格边界内的所有激活平均化,并使用特征可视化来创建图标表征(iconic representation)。
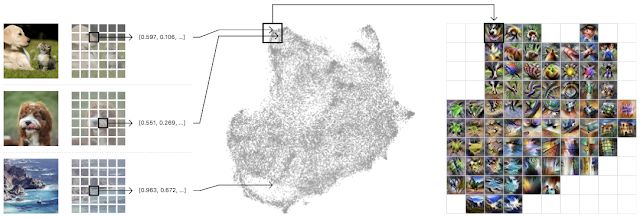
左:随机选取一百万张图像输入至网络中,每张图像收集一个随机空间激活。中:激活被传输至 UMAP,然后降成二维。然后把这些二维激活画下来,相似的激活画在相邻的位置。右:然后绘制一个网格,将网格中每个单元格内的所有激活平均化,对平均后的激活进行特征反演(feature inversion)。
下面是神经网络其中一层的激活值图集(注意,这些分类模型能够有 6 层甚至更多层)。它揭示了这层网络执行图像分类时学到的全部视觉概念。该激活值图集可能乍一看让人头晕——但还有很多呢!这种多样性反映了模型发展出来的的各种视觉抽象和概念。
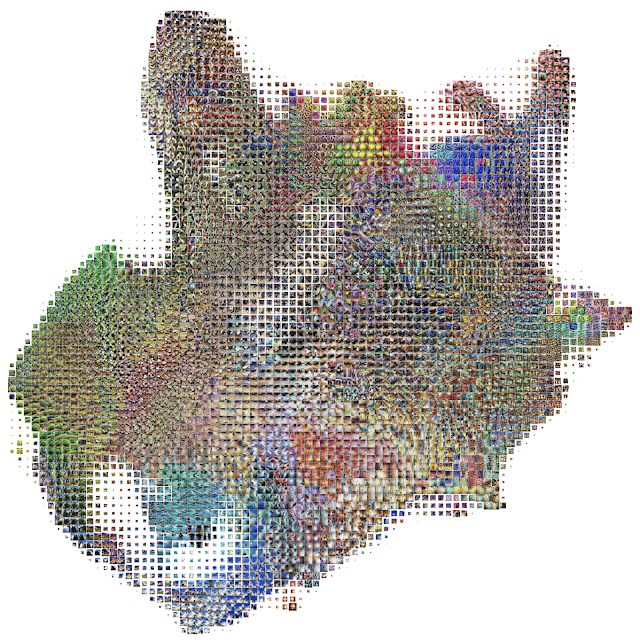
Inception v1 多层网络中其中一层(mixed4c)的激活值图集概览。

在这张图中,我们可以看到检测器视角下不同类型的叶子和植物。

从不同检测器中看到的水、湖和沙洲。

人类眼中的不同类型建筑和桥梁。
正如之前所提到的,这个网络有很多层。我们可以看看在此之前的层级,然后看这些概念是如何随着层的加深而变得更加精细的(每层网络基于上一层网络的激活值计算当前层的激活值)。

在该层的上一层即 mixed4a 的激活图中,有一个模糊的「哺乳动物」区域。
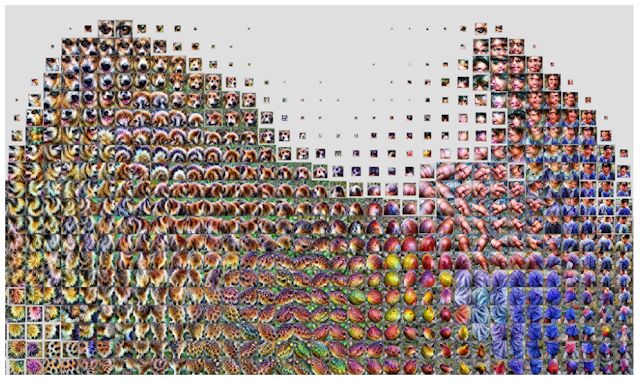
在下一层即 mixed4b 的激活图中,动物和人已经分开了,中间还出现了一些水果和食物。

在 mixed4c 层中,这些概念变得更精细了,且被微分成较小的「半岛(peninsulas)」。
上面我们已经看到从层到层的全局结构演变了,但随着层层递进,这些概念开始变得越来越具体和复杂。如果我们聚焦于三层网络在具体分类中的激活图,如卷心菜,我们会看到下图:

左:与另外两个相比,前层的激活图看起来非常不具体。中:中间层的图像绝对可以看出是叶子,但却无法确定是哪种植物的叶子。右:最后一层中的图像非常具体,就是卷心菜。
另一个值得注意的现象是:随着层数变深,不仅概念变得精细,同时旧概念也可以组合成新概念。
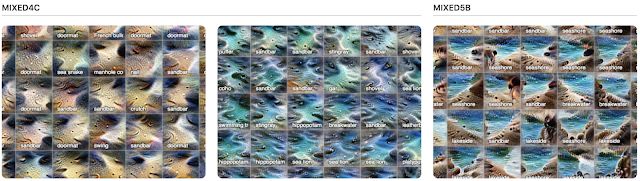
在中间层 mixed4c(左和中)中,你可以看到沙子和水是明显不同的概念,它们都具有强烈的属性来分类为「沙洲」。而在后面的 mixed5b 层(右)中,这两个概念似乎融合成一个激活图了。
我们也可以在特定层为 ImageNet 1000 种类别创建激活值图集,而不是在特定层放大整个激活值图集的特定区域。这样将展示网络经常用来进行具体分类(如红色的狐狸)的概念和检测器。

当对「红色的狐狸」进行分类时,我们可以更清楚地看到网络的关注点在哪里。尖尖的耳朵、红色皮毛包围着的白色口鼻部、树木繁茂或白雪皑皑的背景。

通过检测器看到的不同大小、角度的「瓦屋顶」。

对于「野山羊」,通过检测器可以看到羊角和棕色的皮毛。还有可能找到这种羊的环境,如 rocky hillsides。

像瓦屋顶一样,检测器视角下的「洋蓟」纹理也有不同大小,还有针对紫色花朵的检测器。所以这检测的应该是一颗洋蓟的花朵。
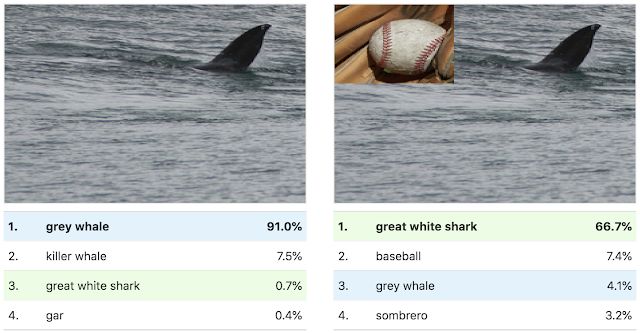
这些激活值图集不仅展示了模型内微妙的视觉抽象,还揭示了概念上的误区。例如,看「大白鲨」的激活值图集时,我们不仅会看到水和三角形,还会看到类似棒球的东西。这暗示了该研究模型采取的一个捷径:它将棒球红色的缝合处与大白鲨的嘴混合在一起了。

我们可以使用棒球图像的缝合处来测试这一点,将模型对特定图像的分类从「灰鲸」切换成「大白鲨」。
我们希望激活值图集(Activation Atlases)会是一个有用的工具,有助于让机器学习变得更易理解和更具解释性。为了便于你使用,我们发布了一些 Jupyter Notebook,通过 colab 就能在你的浏览器上立即执行。它们是基于之前发布的 Lucid 工具构建的,该工具包含很多其它可解释性可视化技术的代码。

jupyter notebook:https://github.com/tensorflow/lucid#activation-atlas-notebooks
工具地址:https://github.com/tensorflow/lucid
参考内容:
https://ai.googleblog.com/2019/03/exploring-neural-networks.html
https://www.theverge.com/2019/3/6/18251274/ai-artificial-intelligence-tool-machine-vision-algorithms
本文为机器之心报道,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com




