「超级 AI」的种子?复杂到人类难以评价的问题,可以教会一个 AI

AI 科技评论按:正如我们仍在自然语言处理的漫漫征途上摸索,AI 安全的课题也仍然没有得到系统的解决。作为前沿探索的积极分子,OpenAI 也不断提出新的思路,有许多既符合人类的思路,也便于未来长期的 AI 发展。
这次,OpenAI 提出了一种名为「迭代扩增」(iterated amplification)的 AI 安全新技术,它可以帮助我们鉴别超出人类可控尺度之外的复杂行为和目标,只需要演示如何把某个任务分解成一些简单的子任务,而无需提供传统的标注数据或者反馈函数。虽然这种想法还处在很早期的阶段,OpenAI 的研究人员们仅仅基于一些非常简单的算法任务进行了实验,但他们仍然决定应该毫无保留地把它的初始模样公布出来。他们觉得,这有可能为 AI 安全带来一条可大规模拓展的光明路径。
从去掉直接的评价开始
传统上,如果我们想要训练一个机器学习系统执行某项任务,我们都会需要一个训练信号,这个训练信号的作用是提供一个评价方式,根据评价出的「好」或者「差」的结果引导系统的学习。比如,监督学习中的数据标注,或者强化学习中的反馈,就是这样的训练信号。这种机器学习范式通常假定了训练信号是已经明确地存在的,然后就可以关注这个信号进行学习。但是在更多的现实任务中,我们总需要找一个什么东西,然后把它作为训练信号。如果我们找不到合适的训练信号,我们就没办法让系统学习;或者如果我们找到的训练信号不合理,系统就会学到奇怪的行为,有时候这些行为甚至可能是危险的。所以,不论是对于一般性地学习一个新任务,还是对于 AI 安全的研究,如果有更好的办法找到/生成训练信号,都会是一件极具价值的事情。
那么,我们现在是如何生成训练信号的呢?一些情况下,我们想要的目标是可以直接用数学形式描述的,比如围棋中的计分、比如赛车游戏中车辆走了多远(下图,左下),或者检查给出的一组乱序数字是否被正确排序(左上)。然而多数真实世界的任务并不能展示出明确的、可以用数学形式表示的训练信号,比如后空翻、比如做饭,在这种时候我们常常可以考虑让一个人做一次这个任务(标注一个训练数据集,中上,或者实际操作一遍,中下),供系统模仿,以此作为训练信号,又或者作为评价者,从旁评价系统执行任务的效果如何。然而,有许多任务还是无法用这些方法解决,它们过于复杂,以至于人类既无法给出评价、也无法执行它们;这样的任务例如,设计一个复杂的城市交通系统,或者管理一个数百台计算机组成的网络,负责其中的安全细节(右)。

迭代扩增就是为最后这类任务生成训练信号的方法,当然了它也需要一定的假设。名义上讲,虽然一个人没有办法直接执行或者直接评价整个任务,但 OpenAI 假设,当你把任务的部分交给一个人的时候,他是有能力把它分解成几个更小的、清晰的部分的。比如,对于刚才提到的计算机网络安全的例子,人可以把「防卫一组服务器和路由器的安全」这个任务分解成「考虑防范对服务器的攻击」、「可考虑防范对路由器的攻击」、「考虑这两种攻击方式互动的可能性」三部分。另外,OpenAI 也假设人类有能力执行任务中的一小部分,比如对于计算机网络安全的例子,人类能够「确认 log 文件中的某一行记录是可疑的」。如果这两个假设为真,那么 OpenAI 认为我们就能够根据人类做小的细分任务的能力,为大规模的任务构建训练信号,同时让人来参与协调整个任务的拼装。
在 OpenAI 的迭代扩增的实现中,他们首先对小的分任务进行采样,训练 AI 系统仿照人类执行这些分任务的演示进行学习。然后他们开始采样更大一些的任务,借助人类的帮助把大任务分解成较小的任务,而这些较小的任务正是前一步中经过训练的 AI 可以解决的。接着,OpenAI 把这些在人类的帮助下得到的二阶任务的解决方案直接作为训练信号,训练直接解决二阶任务的 AI 系统——这次也就不再需要人类帮助了。下一步,OpenAI 继续组合不同的任务,在过程中不断建立更完整的训练信号。如果这个过程奏效的话,我们最终就可以期望得到一个完全自动的系统,它可以解决非常复杂的组合性任务,即便在刚开始学习时没有任何针对这些任务的直接训练信号。
这个过程和 AlphaGo Zero 中用到的「专家迭代」(expert iteration)有相似之处,区别在于专家迭代会不断强化一个现有的训练信号,而迭代扩增则是从零开始逐步构建完善的需训练信号。迭代扩增也和近期的几个学习算法有一些共同的特征,在测试阶段解决问题时,它们都可以现场分解任务以便处理,只不过它们的运行环境设置中并没有前期的训练信号。
实验结果
正如之前通过吵架达到 AI 安全的研究,把一个原型阶段的项目直接在超过人类能力的大规模任务上运行是不现实的。而且,真的用人来做前期需要的训练喜好也会带来额外的复杂度,所以目前 OpenAI 并未这样做(计划未来会做做)。
对于早期实验,OpenAI 首先尝试把迭代扩增用在具有数学形式的训练信号上,以便说明它在简单的设定下是可以奏效的;OpenAI 也暂时把注意力限制在监督学习领域内(上一次借助人类生成隐式的训练信号见你做我评,根据人类反馈高效学习)。他们在 5 个简单的可以数学化的简单任务上尝试了迭代扩增方法。这些任务本身具有直接的、有清晰数学形式的解(比如找到一个图的两个节点之间的最短路径),但 OpenAI 的研究人员们暂时假装不知道这个解。解决这些任务可以通过把小的、单步的推演过程一个个拼接起来(比如把相连的两个短路径拼接起来形成一个长的路径),不过想要靠人工把所有的东西都这样拼接起来则会耗费非常多的精力。
在这种设置下,OpenAI 只把任务的小部分作为训练信号,测试使用迭代扩增来学习最终的直接解决算法;这个过程作为「人类知道如何组合一个组合的各个部分,但无法给出一个直接的训练信号」情境的简单模拟。
对于五个任务中的每一个任务(置换排序、序列对齐、通配符搜索、最短路径搜索以及联盟搜索),迭代扩增学习到的结果都可以和监督学习直接学到的结果有近似的表现 —— 别忘了,这可是以“没有直接的训练信号”作为阻碍,还取得了这样的可贵,难能可贵。(另外值得说明的是,OpenAI 的目标是希望迭代扩增能利用更少的信息也取得与监督学习相当的成绩,而无需超过)
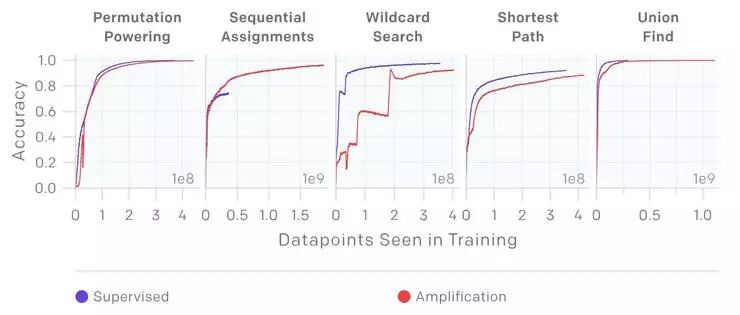
在任务中,迭代扩增无需查看真实值标注,就可以取得和监督学习近似的表现
迭代扩增和 OpenAI 之前通过吵架达到 AI 安全的研究有许多相似的特征。和通过吵架达到 AI 安全一样,它都是在想办法解决那些根据人类的现有问题无法直接操作、或者无法直接评价的任务,过程则是一个迭代进步的过程,而人类就可以在这个过程中提供间接的监督,不管具体的任务、具体的操作细节有多么不同。迭代扩增也利用了 OpenAI 在你做我评中的研究成果,它实现了一个反馈预测系统,之后的更新的版本也很有可能可以包括来自真正的人类的反馈。
目前为止 OpenAI 对这几种不同的路径的探索都还只是在很初级的程度上,下一步的挑战就是如何拓展它们的规模,让它们解决更有趣、也更现实的问题。
论文地址:https://arxiv.org/abs/1810.08575
viablog.openai.com,雷锋网 AI 科技评论编译
全球AI+智适应教育峰会
免费门票开放申请!
雷锋网联合乂学教育松鼠AI以及IEEE教育工程和自适应教育标准工作组,于11月15日在北京嘉里中心举办全球AI+智适应教育峰会。美国三院院士、机器学习泰斗Michael Jordan、机器学习之父Tom Mitchell已确认出席,带你揭秘AI智适应教育的现在和未来。
扫码免费注册



