用文本分类模型轻松搞定复杂语义分析;NLP管道模型可以退下了

大家好,我是为人造的智能操碎了心的智能禅师。
本文是《NLP 可以很好玩》系列教程的第二篇,由作者 Adam Geitgey 授权在人工智能头条翻译发表。
Adam Geitgey 毕业于佐治亚理工学院,曾在团购网站 Groupon 担任软件工程师总监。目前是软件工程和机器学习顾问,课程作者,Linkedin Learning 合作讲师。
《NLP 可以很好玩》系列教程,用易于理解的案例,清晰通畅的方式,教会大家写出可以理解人类书面语言的程序。
第一篇《用 Python 构建 NLP Pipeline,从思路到具体代码,这篇文章一次性都讲到了》中(链接在文章末尾),我们使用 Python 构建了一个 NLP Pipeline,通过逻辑化的方式解析语法和结构,从而进行英语文本处理。
而今次则可以认识到,文本分类模型是如何轻松解决 NLP Pipeline 的短板,在不经过分析语法结构,仅仅通过对大量数据的相关性,实现快速、高准确度、低硬件需求的语义分析。
全文大约2000字。读完可能需要下面这首歌的时间
👇

难题
先回顾一下 NLP Pipeline 的方式是怎么运作的:首先将文本分成句子,然后将句子分解为名词和动词,接着找出这些词之间的关系,依此类推。
这种方法非常合理,非常合乎逻辑。但同时也导致这种方式使用条件非常苛刻,需要厘清语法结构,对语法(grammar)有非常强的依赖性。
然而不幸的是,人类大部分时间都是非理性的,语言也并不符合语法结构,而且非常依赖使用场景,这也是为什么会有误解这种东西的存在。
很多脱离了使用场景的对话,别说机器,连人类自己都理解不来。通过 NLP Pipeline 的方式去解析,就显得有点欺负人了。
再举个例子。下图是 Adam 在国外的“58 + 点评”网站 Yelp 上,对一个公园的评价:
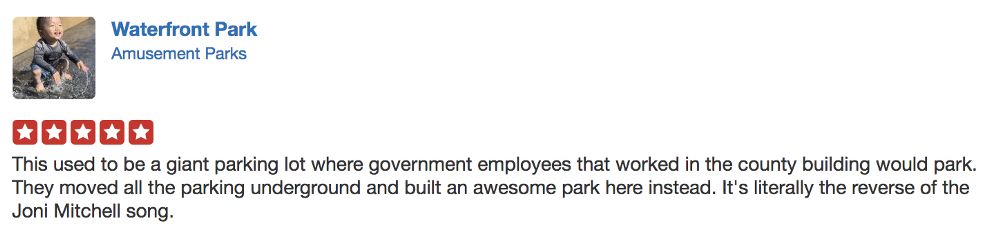
Adam 给了一个五星评价。通过这个五星评价,机器能判断出用户满意度是非常高的。
但如果没有星级评分呢?如果作者的评价中不出现明确的“满意”“不满意”的文字呢?比如作者说:这个公园,秋风送爽,风和日丽,鸟语花香。那么机器该如何从这条评价的字里行间,判断作者的心思呢?
这个时候,就可以将这种复杂的语言理解任务重新定义为一个简单的分类问题。
分类模型
我们先设置一个简单的线性分类器,用于接收单词。分类器的输入是评论的文本;输出是5个固定标签之一:“1星”,“2星”,“3星”,“4星”,以及“5星”。

要想分类器能够可靠地预测,那它就必须以某种方式,充分的理解整个文本的含义,从而做出判断。
训练文本分类模型
首先,我们收集大量(大量的意思是百万量级)类似地点(比如:公园,企业,地标,酒店…)的用户评论,按照评星分类,这样我们就能得出文本和评星之间的对应关系。是不是很简单?
但简单的东西,应用场景可是一点都不简单。比如你现在可以成立一家分析社交媒体趋势的公司,监测微博上跟品牌相关的评价内容,给品牌做用户满意度跟踪和预测,提前应对即将到来的负面信息。品牌就有了更加充足的时间去准备危机公关,听着都感觉很刺激。
甚至我们可以做一个触发开关,当评价走低的时候,自动触发应急预案。
简单的让人心疼
人们不断创造和发展语言。 特别是在一个充满了模因和表情符号的在线词汇中,靠语法分析和传统分词的方式,操作难度太高。
比如一个德语文本,那么训练处理美国英语的 NLP Pipeline 就会崩溃。 如果用户使用老伦敦土语(Cockney Rhyming Slang)撰写评论,别说算法了,就是一个正常的英语母语的人也会崩溃的。
比如这句典型的老伦敦土语:I ran up the apples, got straight on the dog to me trouble and said I couldn't believe me mincers. 翻译过来是:我跑上台阶(apples),径直的拿起座机(dog),打给我老婆(trouble),说简直不敢相信我的眼睛(mincers)。
简直喵喵喵的跟江湖黑话一样:合吾的朋友(合得来的朋友),在家日月宫(在家靠父母),在外并肩子(在外靠朋友),把招子放亮了,别崩了盘子(别闹僵了)。
🤷🤷🤷
表情符号也不在话下。如果ಠ_ಠ与1星和2星评论的对应关系更为密切,即使算法不知道这个表情是啥意思,但分类器仍然可以在它们出现的位置、对特定输出的贡献频率中,找出字符的含义。
算法会将文本分解为单独的单词,并测量这些单词的效果。只要给分类器投喂足够的训练数据,管你英语德语还是汉语蒙语,在算法面前一视同仁。
文本分类还有一个非常大的优点:快。线性文本分类算法非常简单,相比递归神经网络这些复杂的算法,训练也快,要求的硬件也更亲民。
你可以普通笔记本电脑上训练带有千兆字节文本的线性分类器,都不需要用到GPU,而且准确度也很高。研究表明,文本分类算法和其他算法,在准确度之间的差距几乎为零。
当然,任何算法都不可能是完美无瑕的。文本分类算法虽然操作简单,但对数据量有非常大的依赖。数据越多,准确度越高;反之准确度会非常难看。
构建用户评论模型
安装工具
接下来我们利用 Facebook 的 fastText 作为工具,来构建我们的用户评论模型。这是个开源工具,可以将其作为命令行工具运行或从 Python 调用它。安装也很简单:

获取数据
工具有了,还缺训练数据。感谢 Yelp ,提供了470万用户评论的研究数据集。下载地址:
https://www. Yelp .com/dataset/download
🚫 注意,改数据只供个人学习使用,严禁用于其他用途,尤其不得用于商业目的
下载数据后,将获得一个名为reviews.json的4千兆字节json文件。 文件中的每一行都是一个json对象,其数据如下:
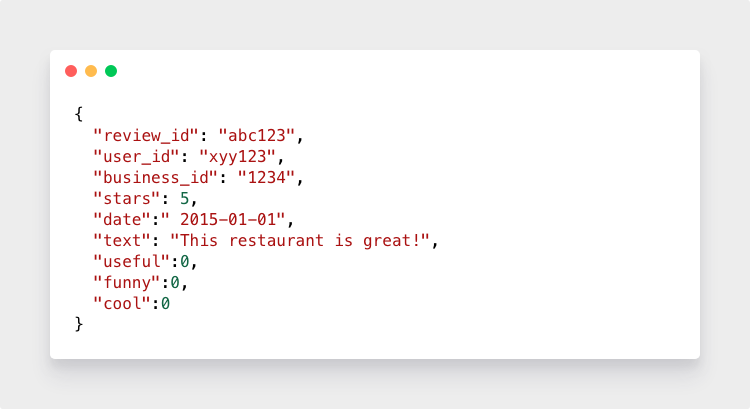
格式化和预处理
第一步是将此文件转换为fastText期望的格式。
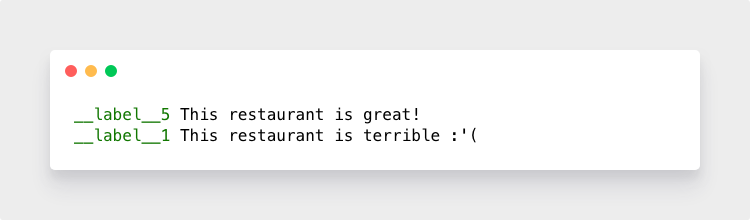
fastText需要一个文本文件,每行文本都在一行上。每行的开头都需要有一个__label__YOURLABEL的特殊前缀,用于为该段文本分配标签。
换句话说,我们的餐厅评论数据需要重新格式化,如下所示:
这是一段简单的 Python 代码,它将读取 reviews.json 文件并以fastText格式写出一个文本文件:

运行后会创建一个名为fastText_dataset.txt的新文件,我们可以将其输入fastText进行训练。但是,我们还没有完成,仍然需要做一些额外的预处理。
在fastText看来,Hello hello hello! 是3个不同的词。 要解决这个问题,可以将所有内容转换为小写,并在标点符号前加上空格。 这称为文本规范化,它使fastText更容易获取数据中的统计模式。
这意味着文本This restaurant is great! 应该成为this restaurant is great ! 。
这是一个简单的 Python 转换函数,可以添加到代码中:

⚠️ 下面提供的完整代码包含此功能
将数据拆分为训练集和测试集
为了准确衡量模型的表现,需要测试训练数据外的数据。
我们从训练数据集中提取一些字符串,保存在单独的测试数据文件中。然后使用保留的数据测试训练模型的性能,以获得模型执行情况的真实效果。
接下来是我们数据解析代码的最终版本,它读取 Yelp 数据集,删除任何字符串格式,并写出单独的训练和测试文件,将90%的数据随机分成测试数据,10%作为测试数据:
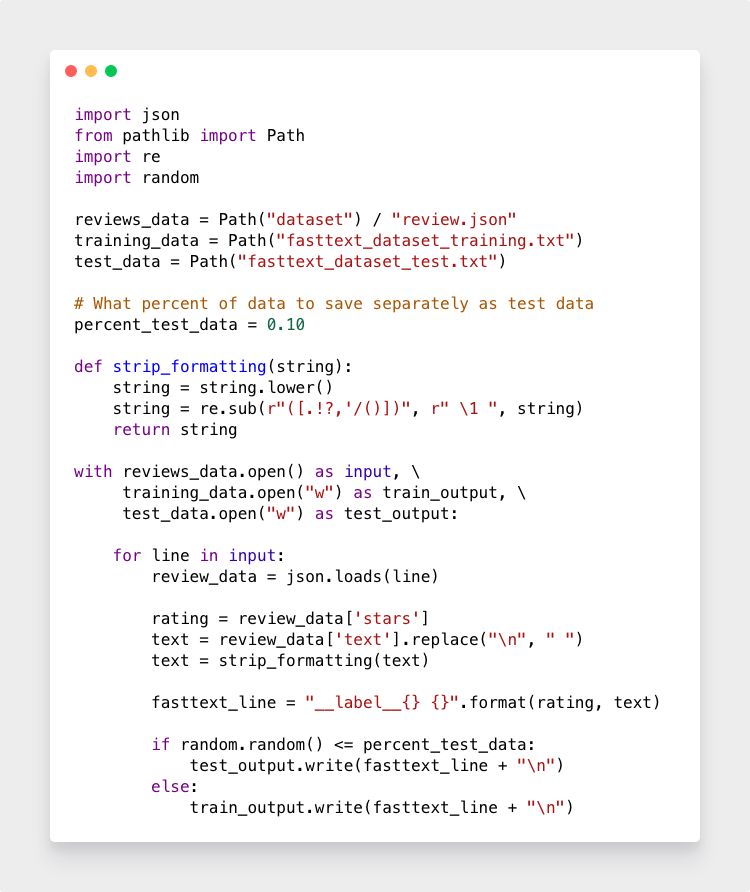
运行后会生成两个文件:fastText_dataset_training.txt和fastText_dataset_test.txt。现在我们准备训练了!
这里还有一个提示:为了使模型更撸棒,在使用自己的数据时,还需要随机化每个数据文件中的行顺序,以便训练数据的顺序不会影响训练过程。当然在本文中不需要,因为 Yelp 的数据已经非常随机了。
训练模型
使用 fastText 命令行工具训练分类器,只需调用fastText,传递supervised关键字,告诉它训练一个有监督的分类模型,然后为其提供训练文件和模型的输出名称:
速度简直快的不像话。一台普通笔记本电脑,用5.8亿个单词训练这个模型,只花了3分钟!
测试模型
让我们通过检查我们的测试数据来了解模型的准确性:
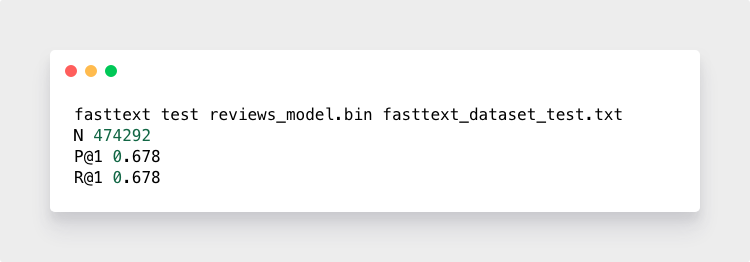
这意味着在474,292个示例中,它猜测用户的确切星级评分为67.8%。 不错的开始。
你还可以要求 fastText 检查星级评分中预测的准确率。比如模型预测一条评论可能是“5”也可能是“4”,而真实用户说的是“4”,那么就可以得出模型预测为“4”的频率。
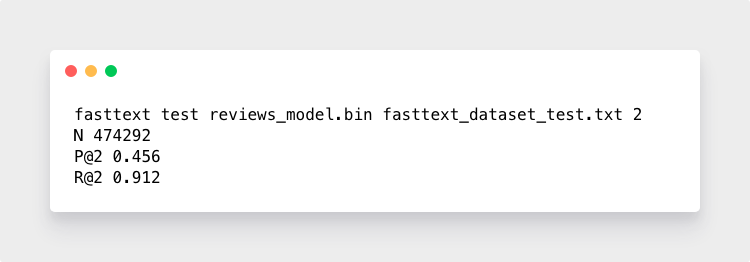
91.2%,说明绝大部分时间算法都猜对了。
还可以通过运行 fastText 的predict命令然后键入自己的评论,以交互方式试用模型(注意,输入的格式跟外面训练数据要保持一致,全部小写并且标点前面加空格)。

当输入this is a terrible restaurant . i hate it so much .的时候,返回__label__1;当个输入this is the best restaurant i have ever tried .的时候,返回__label__5,以此类推。
迭代模型,使其更准确
使用默认的训练设置,fastText 可以独立跟踪每个单词,而不关心单词顺序。但是当你有一个大的训练数据集时,需要它使用wordNgrams参数来考虑单词的顺序。这将使它跟踪词组,而不仅仅是单个单词。
对于数百万字的数据集,跟踪两个字对(也称为双字母)而不是单个字是改善模型的良好起点。
Adam 用了一下-wordNgrams 2参数,稍微对上下文有一些解析,准确度直接从67.8%提升到71.2%,减少了模型产生的明显错误的数量;但同时也使训练花费更长时间,模型文件更大,因为现在数据中的每个双字对都有一个条目。

训练完成后,运行测试命令:

把模型应用到自己的程序中
fastText 最爽的是可以很轻松的从任何 Python 程序调用训练模型。
您可以使用一些不同的用于 fastText 的 Python 包装器,但我喜欢Facebook创建的官方包装器。 您可以按照以下说明进行安装 。
安装完成后,这里是加载模型并使用它自动评分用户评论的整个代码:
这是它运行时的样子:
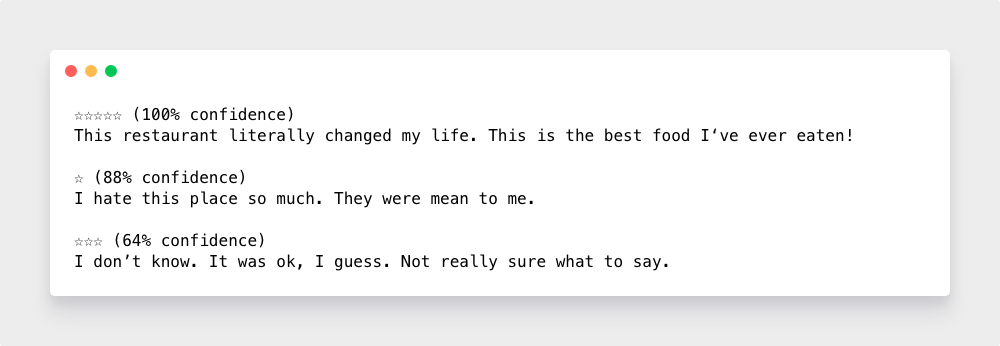
这些都是非常好的预测结果! 让我们看看它会给我的 Yelp 评论预测:

这就是机器学习最酷的地方!一旦我们找到了解决问题的好方法,算法就能帮我妈完成从训练数据中提取语义的所有艰苦工作,然后,仅仅几行代码调用该模型,事情就成了。
简直跟变魔术一样!
开脑洞
这个简单的文本分类算法,可以应用在很多场景中。例如识别垃圾邮件,自动为消费者对接正确的售后团队,轻松给社交媒体内容和文档进行分类、重新分类等。
比如基于用户在微博上发布内容的文本分类模型,就可以定向精准推送广告。又比如公司手头有上千个千个咨询项目,需要根据新的政府规定重新分类,可以手动对随机抽样进行分类,然后构建分类模型以自动编码其余项目,而不用阅读每个项目的摘要。
甚至可以构建将一个分类模型输入另一个分类模型的系统。想象一个用户支持系统,其中第一个分类器猜测用户的语言(英语或德语),第二个分类器猜测哪个团队最适合处理他们的请求,第三个分类器猜测用户是否已经不满意选择票证优先级码…
是不是有种用乐高搭了个布加迪卫龙辣条的成就感!不用犹豫了,下手吧!
延伸阅读:





