立体视觉Cost Volume构建新方法,性能SoA且运行时间大幅降低
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:Wayne
https://zhuanlan.zhihu.com/p/97188877
本文已由作者团队授权,未经允许,不得二次转载
Cascade Cost Volume for High-Resolution Multi-View Stereo and Stereo Matching

作者团队:阿里巴巴 A.I. Labs&西蒙弗雷泽大学
论文链接: https://arxiv.org/abs/1912.06378
代码链接: 将在两周内整理好放出来.
1. Motivation
最近几篇基于深度学习的Multi-view Stereo 和 Stereo Matching模型都引入了3D的cost volume来约束并回归深度图或视差图.基于3D的cost volume的方法会首先假设一系列的深度/视差平面(下文统一称为hypothesis)并通过将特征图warp到不同的平面上来构建cost volume. 接下来一系列的3D CNNs会用来regularize cost volume并且回归出最终的深度/视差图. 这一系列基于3D cost volume的方法相较于纯2D CNNs来做回归有以下优势:能够更好地捕获几何结构;可以在3D空间来执行photometric matching;并且可以减轻由透视变换和遮挡引起的图像失真的影响.
但是3D CNNs的引入限制了这些方法在需要高分辨率输出的时候的应用, 因为3D CNNs通常很费显存并且运算时间也比较长. 几篇比较经典的基于深度学习的Stereo Matching方法常使用插值将做了cost aggregation之后的probability volume插值到原图的尺寸然后再做视差的回归,而基于深度学习的Multi-view stereo的方法常对回归出的深度图进行插值来放大到原图的尺寸.

我们思考一下,当下主要影响显存和运行时间的两个原因就是cost volume的分辨率和卷积的层数. 首先cost volume的分辨率由 



因此我们希望设计一种新的Cost Volume的构建方法来输出一个full resolution的深度/视差图,并且希望能大幅降低对显存和运行时间的要求.
针对这两个目标,首先要解决的就是显存和运行时间的问题.根据前边的分析,H,W和D这三个参数似乎都对最终的精度产生比较大的影响.那我们能否设计一种coarse-to-fine的框架来降低对显存和运行时间的依赖?针对另外一个问题,2D特征提取的过程中并没有很好地利用金字塔特征,那么在coarse-to-fine的框架逐渐引入带有detail的2D特征来恢复high-level特征丢掉的细节是否可行呢?
2. Method
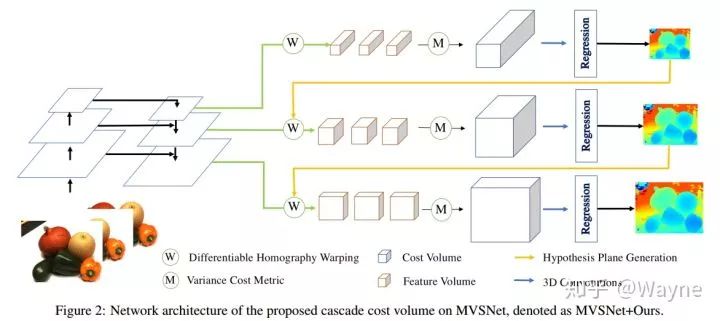
根据以上分析,我们提出了一种显存和时间利用率较高的cost volume的构建方式,它针对现有的基于3D cost volume的框架是一种互补的存在. 我们称所提出的方法为Cascade Cost Volume.
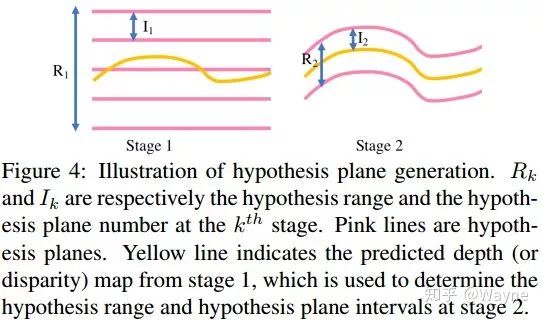
Cascade cost volume由多个阶段构成,并且是构建于特征金字塔编码器来对不同尺度的特征进行geometry 和 context的编码.其中较早阶段cost volume是由larger scale semantic 2D 特征以及比较sparse的hypothesis构成,这样就可以构建一个hypothesis resolution较低的cost volume.随后我们利用先前阶段的预测,在后续阶段缩小深度或者视差的范围(例如我们一开始要预测总的深度范围是192,第一个阶段我们使用48个hypothesis,虽然比较粗糙但是能得到一个初步的预测.第二个阶段可以利用第一个阶段的预测,并在第一个预测值的附近再构建一个范围比较小的cost volume.同理第三个阶段构建的cost volume的范围就可以更小了)

利用这种coarse-to-fine的cost volume构建框架,GPU显存消耗从10.8GB降到了2.3GB,运行时间从1.2s降到了0.3s.在这种框架下,我们就能引入不同spatial resolution的cost volume而不是利用插值来回归出一个高分辨率的结果. 具体做法是利用上在2D 特征提取过程中不同分辨率的特征来构建spatial resolution逐步提高的cost volume,我们的策略是在第k个stage的cost volume上,spatial resolution设置为 
基于coarse-to-fine的框架,即便引入了spatial resolution的cost volume,显存需求也仅是5.3GB,运行时间为0.49s.相较于原始的MVSNet单阶段的cost volume还是有很大的优化.
3.Results
为了验证这种cost volume的通用性,我们分别在Multi-view stereo 和 Stereo matching上选了几个经典的基于3D Cost volume的方法,把他们的cost volume换成我们提出的构建方式.
1)Experiments on Multi-view stereo
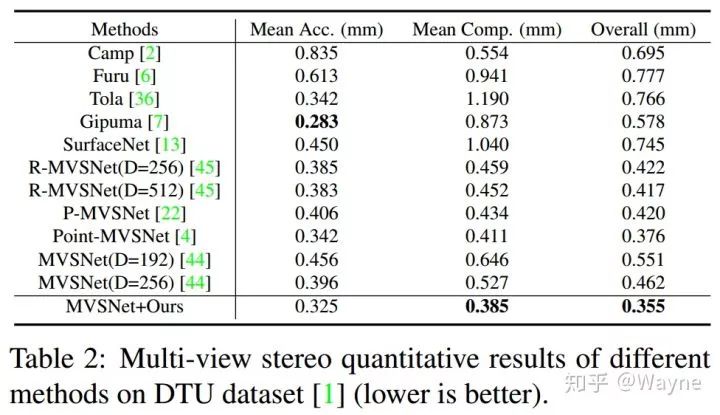
针对Multi-view stereo,我们选择了MVSNet作为baseline model,并且分别在DTU和Tank and Temples数据集上做了实验. 在DTU数据集上,把MVSNet单阶段的cost volume换上我们的cascade high-resolution cost volume框架可以取得目前最好的性能(overall 为0.355mm).
由于我们是一种coarse-to-fine的formulation, 我们可以在不同的stage的cost volume 用不同的depth hypothesis和spatial resolution. 在这里我们选用3 stages的cost volume, depth hypothesis 分别设为48, 32, 8(MVSNet总的depth hypothesis数目为256), depth interval分别设置为MVSNet的4倍,2倍和1倍.另外stage1的spatial resolution和MVSNet是一样的,但是在stage2和stage3我们增加了cost volume的spatial resolution到MVSNet的4倍和16倍.

通过比较发现,使用cascade high-resolution cost volume的MVSNet(Table5 最后一行)整体精度(overall)大幅优于MVSNet,显存消耗从10.8GB降到了5.3GB,运行时间也从1.2s降到了0.49s.
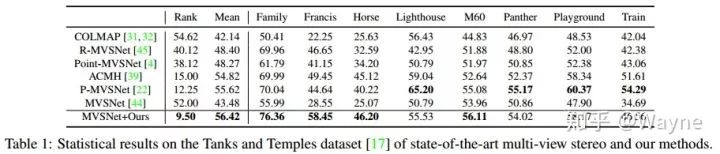
除了在DTU数据集上进行评测,我们拿训好的模型直接在Tank and Temples数据集上进行测试. 截止到11月16号,我们的方法在所有基于deep-learning的MVS方法里排名第一.


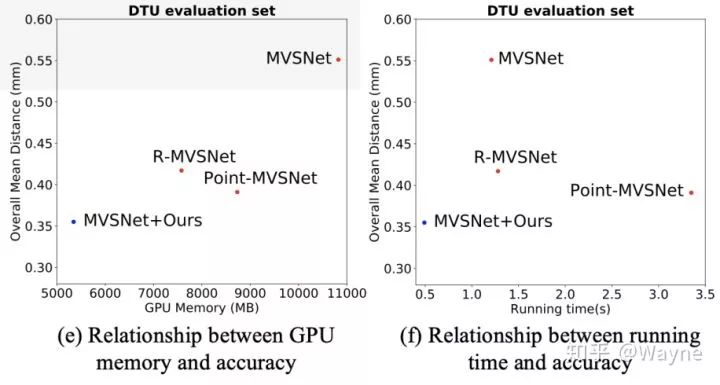
通过和其他方法的可视化对比,我们提出的能够直接输出high-resolution的方法能回归出更多的点云细节,显存消耗和运行时间也明显低于其他方法.
2)Experiments on Stereo Matching
在Stereo Matching的任务里,我们选择了经典的PSMNet,GwcNet和GANet作为我们的baseline models,并且把他们的cost volume 替换成了我们的cascade high-resolution cost volume.
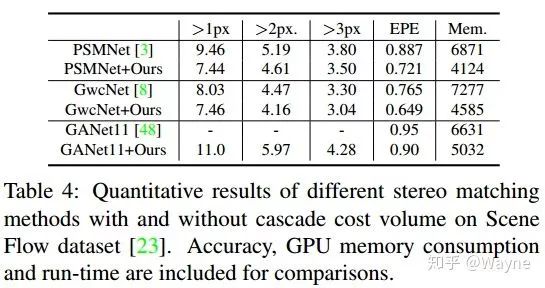
作为一项互补的存在,三个baseline models更换了cost volume的构建形式以后性能均有大幅度提升.
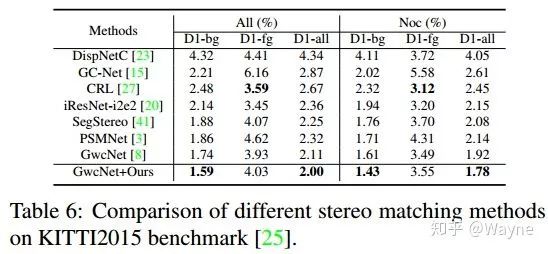
除了在SceneFlow这个仿真数据集上进行验证之外,我们还在KITTI Stereo Benchmark上提交了成绩.因为官方限制提交次数,我们仅选取了GwcNet作为我们的baseline model.截止到11月5号,GwcNet和使用我们所提出的cost volume构建的GwcNet分别排在29名和17名.
4.Ablation Study
这一章节涉及到的实验比较多,包括设置多少个cascade stage;不同的spatial resolution的影响;使用feature pyramid feature构建cost volume的优势;不同stage cost volume要不要共享权重以及如何设置不同stage的loss weight.大家可以看一下arxiv上的文章上分析和实验结果.
5.Conclusion
通过分解单阶段的cost volume到一种级联的coarse-to-fine的cost volume,我们可以降低所需要的depth/disparity hypothesis数目,减小depth/disparity interval.在这种框架下我们可以使用具有更多图像细节的feature map来构建cost volume并且减轻了整体的显存和运行时间的消耗.这种方法针对当前基于3D cost volume的模型是一种互补的存在,我们在Multi-view stereo和stereo matching上的一系列实现验证了方法的有效性.
CVer 推荐阅读
YOLACT++:更强的实时实例分割网络,可达33.5 FPS/34.1mAP!
重磅!CVer-学术交流群已成立
扫码可添加CVer助手,可申请加入CVer大群和细分方向群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
麻烦给我一个在看!