手动调参慢,随机搜索浪费资源?Deepmind异步优化算法PBT解决神经网络痛点

在围棋和Atari游戏、图像识别与语言翻译等领域,神经网络都取得了巨大的成功。但经常被忽视的一点是,神经网络在这些特定应用中的成功往往取决于研究开始时做出的一系列选择,包括:使用何种类型的网络、用于训练的数据和方法等。目前,这些选择(又称为超参数)是通过经验,随机搜索或计算密集型搜索过程来选择的。如何选择参数和调参往往成为训练神经网络的关键问题。
在Deepmind最近一篇名为《Population Based Training of Neural Network(http://t.cn/RYfuj4C)》的论文中,Deepmind提出了一种名为PBT(Population Based Training)训练神经网络的新方法,使得实验者能够快速地选择最佳的超参数集和模型。这一技术可同时训练和优化一系列网络,从而可以快速找到最佳的设置。更重要的是,这不会增加额外的计算开销,可以像传统技术一样快速地完成,并且易于集成到现有的机器学习管道中。
该技术是超参数优化最常用的两种方法随机搜索和手动调试的结合。随机搜索中会并行训练神经网络的群体,并在训练结束时选择最高性能的模型。通常情况下,这意味着只有一小部分群体会获得良好的超参数训练,但更多的群体培训效果欠佳,浪费计算机资源。
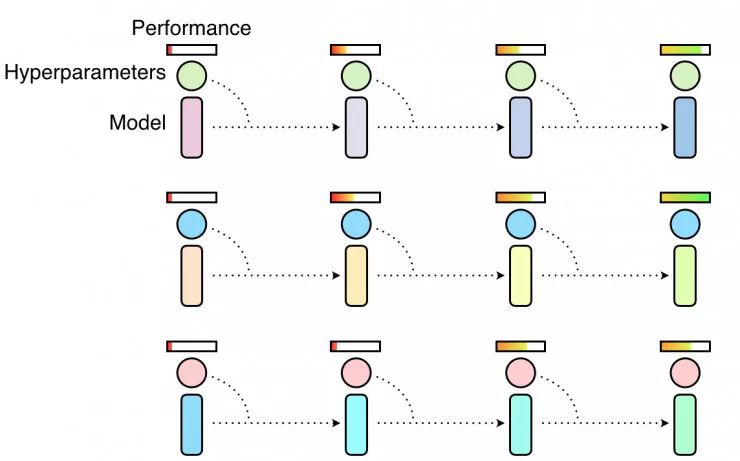
随机搜索超参数意味着同时并行独立训练多个超参数,某些超参数会让模型表现良好,但大多数不会
如果我们使用手动调整超参数,研究人员必须猜测最好的超参数,使用它们训练模型和评估性能,这样的过程将持续重复,直到研究人员对网络的性能感到满意为止。虽然手动调参可以带来更好的性能,但是缺点是这需要很长时间,有时需要数周甚至数月才能找到完美的设置。虽然有诸如贝叶斯优化等一些自动化方法,但是仍然需要很长的时间,并且需要很多持续的训练来找到最好的超参数。
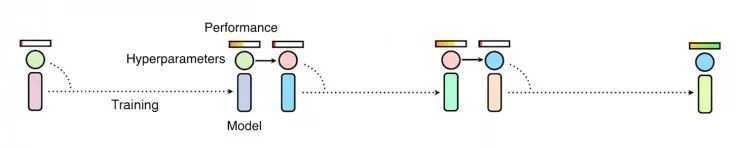
手动调参及贝叶斯优化等方法通过一次观察多个训练过程来改变超参数,这通常较为缓慢
如同随机搜索一样,PBT首先也会并行训练多个神经网络与随机超参,但是每一个网络不是独立训练的,而是使用来自其他群体的信息来完善超参数,并将计算资源引导到更有优秀的模型。这以算法灵感来自于于遗传算法,每个群体成员都被称为“工人”,并可以利用其余群体成员的信息,如从另一个性能较好的“工人”中复制模型参数,此外,它还可以通过随机更改当前值来探索新的超参数。
随着对神经网络群体训练的不断深入,这一开发和探索的过程会定期进行,以确保所有群体中的“工人”都有一个良好的基础性能水平,并且在此基础上在探索新的超参数。这意味着PBT可以快速利用好的超参数,可以为更有效的模型提供更多的训练时间,而且可以在整个训练过程中调整超参数值,从而自动学习最佳配置。
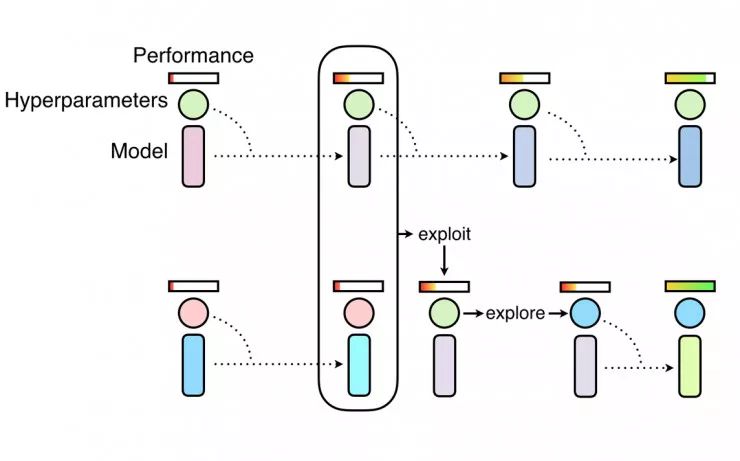
PBT从随机搜索开始,但允许相互利用更有效的结果,并随着训练的进行探索新的超参数
实验表明,PBT在整个任务和领域都非常有效。Deepmind在DeepMind Lab,Atari和StarCraft II上使用最先进的方法严格测试了一套具有挑战性的强化学习问题,在所有情况下,PBT稳定的训练方式均能很快就找到了好的超参数,并得到了超出最新基线的结果。
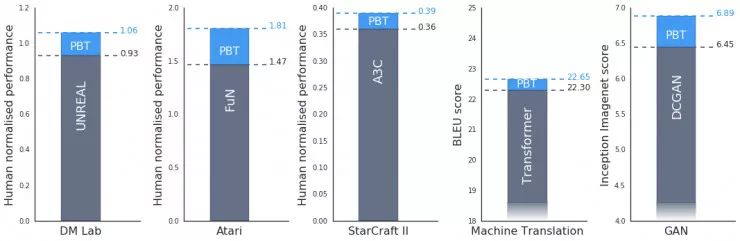
此外,PBT对训练生成对抗网络(GAN)同样有着一定的提升。在Deepmind使用PBT框架来最大化Inception Score(雷锋网注:Inception Score是衡量视觉保真度的指标之一)的测试中,结果从6.45显著提升到了6.9。
Deepmind也将PBT应用于Google最先进的机器翻译神经网络之一。这些神经网络通常经过精心设计的超参数时间表进行培训,这往往需要数月时间才能有改善。使用PBT可以自动找到超参数的时间表,这些时间表可以匹配甚至超过现有的表现,但不需要任何调整,同时通常只需要一次训练。
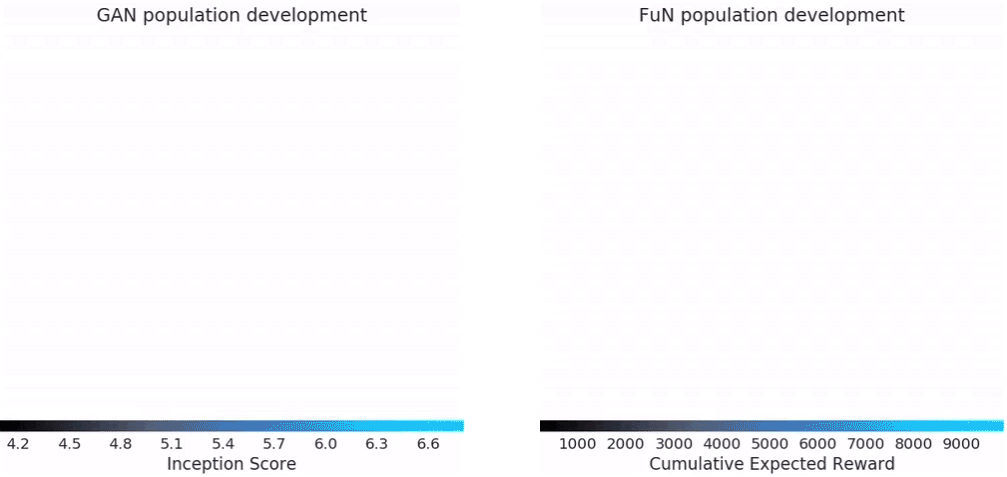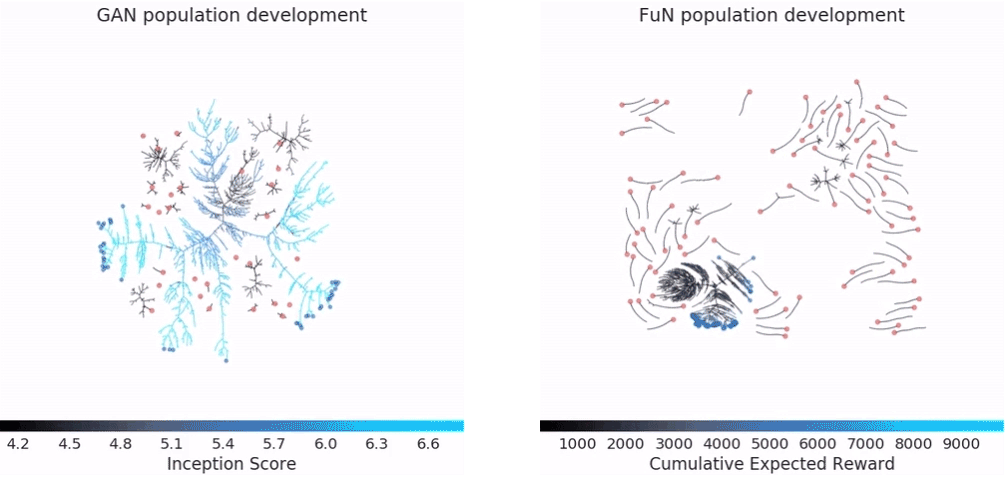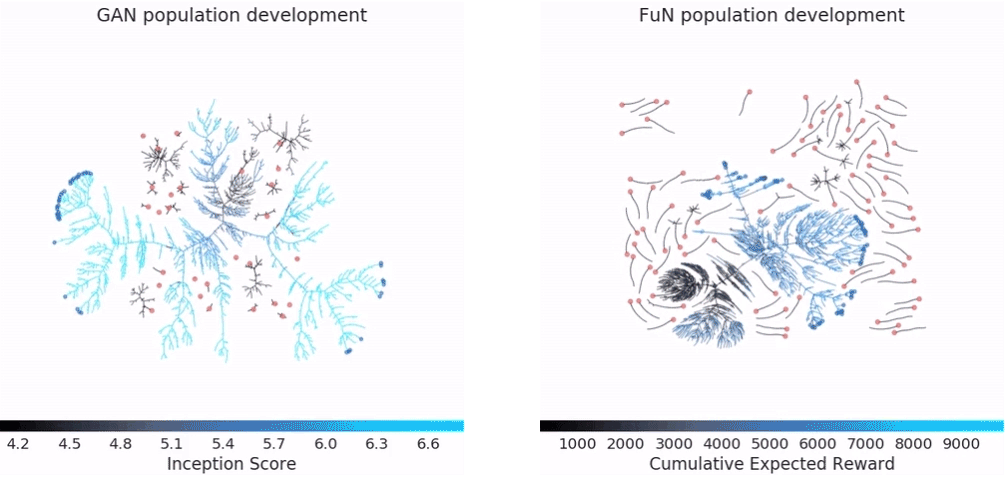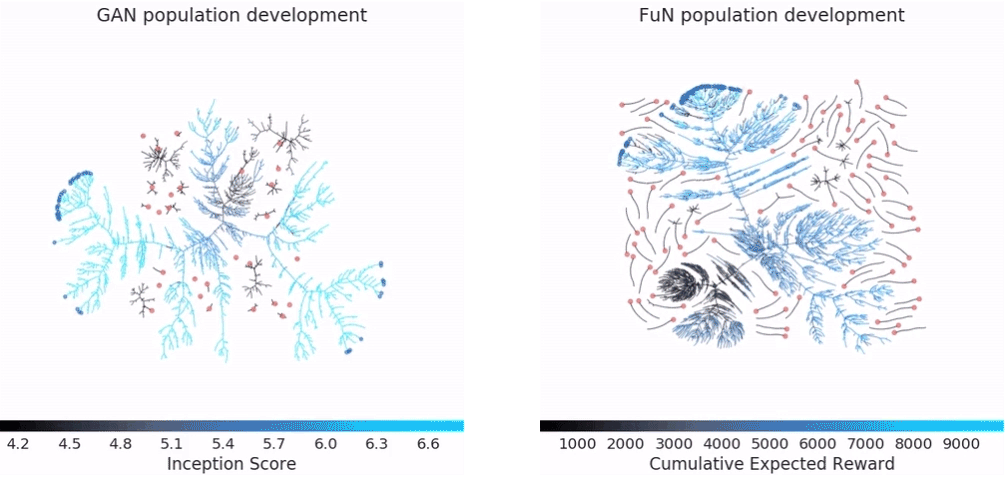
图为在CPSAR-10和封闭网络(FuN)用GANs对“吃豆小姐”(Ms Pacman)游戏训练过程中群体的演化过程。粉红色的点代表最初的智能体,蓝色为最终的智能体。
Deepmind认为,这项技术仍然存在很大的扩展空间。PBT对训练引入新超参数的新算法和神经网络体系结构尤其有效,随着不断细化这个过程,PBT有望更好地应用于寻找和开发更复杂和更强大的神经网络模型。
(完)

如何选择机器学习模型?
如何提高选择算法的能力?
对于算法能力应该从哪块开始抓起?
欢迎报名算法进阶课程
算法推导+实操
双倍告诉你
▼▼▼
(不要等早鸟票过期了才后悔~)

新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据,教程,论文】
深度学习调参有哪些技巧?
▼▼▼

