TensorFlow实现神经网络入门篇

本文首发于阿里云云栖社区(http://t.cn/RYRORg6),AI研习社授权转载。
如果你一直关注数据科学/机器学习,你就不能错过深度学习和神经网络的热潮。互联网公司正在寻找这方面的人,而且从竞赛到开源项目,都有巨额奖金。
如果你对深度学习所提供的前景感到兴奋,但是还没有开始,在这里或许是你开始的第一步。
在这篇文章中,我将介绍TensorFlow。阅读本文后,你将能够理解神经网络的应用,并使用TensorFlow解决现实生活中的问题,本文中的代码是用Python编写的,Python最近的火爆也和深度学习有关。
何时使用神经网络?
有关神经网络和深度学习的更详细的解释, 请看这里(http://t.cn/RYRNUS6)。其“更深”版本正在图像识别,语音和自然语言处理等诸多领域取得巨大突破。
现在的主要问题是何时使用神经网络?关于这点,你必须记住一些事情:
1.1:神经网络需要大量的信息数据来训练。将神经网络想象成一个孩子。它首先观察父母如何走路。然后它才会独立行走,并且每走一步,孩子都会学习如何执行特定的任务。如果你不让它走,它可能永远不会学习如何走路。你可以提供给孩子的“数据”越多,效果就越好。
1.2:当你有适当类型的神经网络来解决问题时。 每个问题都有自己的难点。数据决定了你解决问题的方式。例如,如果问题是序列生成,递归神经网络更适合,而如果它是一个图像相关的问题,你可能会采取卷积神经网络。
1.3:硬件要求对于运行深度神经网络模型是至关重要的。神经网络很早以前就被“发现”了,但是近年来,神经网络一直在发光,这是因为计算能力的强大。如果你想用这些网络解决现实生活中的问题,准备购买一些高性能硬件吧!
如何解决神经网络问题?
神经网络是一种特殊类型的机器学习(ML)算法。因此,与每个ML算法一样,它遵循数据预处理,模型构建和模型评估等常规ML工作流程。我列出了一个如何处理神经网络问题的待办事项清单。
1.检查神经网络是否可以提升传统算法。
2.做一个调查,哪个神经网络架构最适合即将解决的问题。
3.通过你选择的语言/库来定义神经网络架构。
4.将数据转换为正确的格式,并将其分成批。
5.根据你的需要预处理数据。
6.增加数据以增加规模并制作更好的训练模型。
7.将数据批次送入神经网络。
8.训练和监测训练集和验证数据集的变化。
9.测试你的模型,并保存以备将来使用。
本文中,我将重点关注图像数据。让我们先了解一下,然后再研究TensorFlow。
图像大多排列为3D阵列,尺寸指的是高度,宽度和颜色通道。例如,如果你现在截取了你的电脑的屏幕截图,则会首先将其转换为3D数组,然后将其压缩为PNG或JPG文件格式。
虽然这些图像对于人来说是相当容易理解的,但计算机很难理解它们。这种现象被称为语义鸿沟。我们的大脑可以查看图像,并在几秒钟内了解完整的图片。另一方面,计算机将图像视为一组数字。
在早期,人们试图把图像分解成像“模板”这样的“可理解的”格式。例如,一张脸总是有一个特定的结构,这个结构在每个人身上都有所保留,比如眼睛的位置和鼻子,或我们的脸的形状。但是这种方法并不可行,因为当要识别的对象的数量增加时,“模板”就不会成立。
2012年,深度神经网络架构赢得了ImageNet的挑战,这是一个从自然场景中识别物体的重大挑战。
那么人们通常使用哪种库/语言来解决图像识别问题?一个最近的一项调查(http://t.cn/Rchdfyp)发现,最流行的深度学习库是Python提供的API,其次是Lua中,Java和Matlab的。最流行的库是:
Caffe(http://t.cn/8FnOmHE)
DeepLearning4j(http://t.cn/RXidtGH)
TensorFlow(http://t.cn/RYRN172)
Theano(http://t.cn/RGDldaz)
Torch(http://torch.ch/)
让我们来看看TensorFlow所提供的功能。 什么是TensorFlow?
“TensorFlow是一个使用数据流图进行数值计算的开源软件库。图中的节点表示数学运算,而图边表示在它们之间传递的多维数据阵列(又称张量)。灵活的体系结构允许你使用单个API将计算部署到桌面、服务器或移动设备中的一个或多个CPU或GPU。“
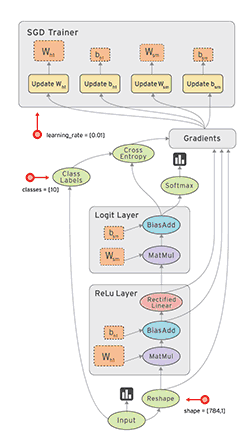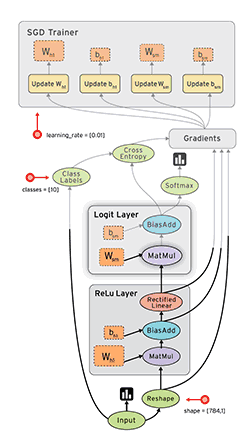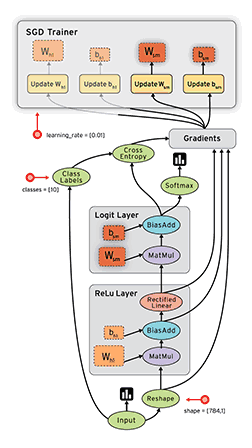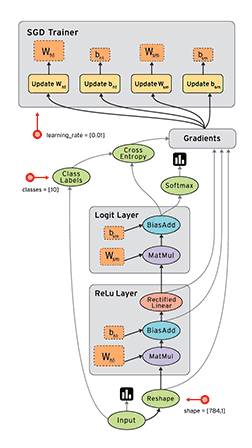
如果你之前曾经使用过numpy,那么了解TensorFlow将会是小菜一碟!numpy和TensorFlow之间的一个主要区别是TensorFlow遵循一个“懒惰”的编程范例。它首先建立所有要完成的操作图形,然后当一个“会话”被调用时,它再“运行”图形。构建一个计算图可以被认为是TensorFlow的主要成分。要了解更多关于计算图的数学构成,请阅读这篇文章(http://t.cn/RyAdOHj)。
TensorFlow不仅仅是一个强大的神经网络库。它可以让你在其上构建其他机器学习算法,如决策树或k最近邻。
使用TensorFlow的优点是:
1.它有一个直观的结构,因为顾名思义,它有一个“张量流”。 你可以很容易地看到图的每一个部分。
2.轻松地在CPU / GPU上进行分布式计算。
3.平台灵活性。你可以在任何地方运行模型,无论是在移动设备,服务器还是PC上。
典型的“张量流”
每个库都有自己的“实施细节”,即按照其编码模式编写的一种方法。例如,在执行scikit-learn时,首先创建所需算法的对象,然后在训练集上构建一个模型,并对测试集进行预测。例如:

正如我刚才所说,TensorFlow遵循一个“懒惰”的方法。
在TensorFlow中运行程序的通常工作流程如下所示:
1.建立一个计算图(http://t.cn/RYRNUS6)。这可以是TensorFlow支持的任何数学操作。
2.初始化变量。
3.创建会话。
4.在会话中运行图形。
5.关闭会话。
接下来,让我们写一个小程序来添加两个数字!
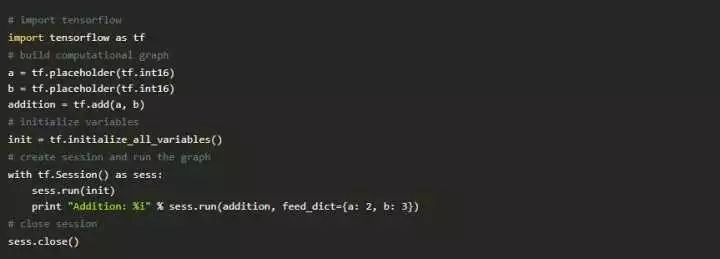
在TensorFlow中实现神经网络
注意:我们可以使用不同的神经网络体系结构来解决这个问题,但是为了简单起见,我们需要实现前馈多层感知器。
神经网络的常见的实现如下:
1.定义要编译的神经网络体系结构。
2.将数据传输到你的模型。
3.将数据首先分成批次,然后进行预处理。
4.然后将其加入神经网络进行训练。
5.显示特定的时间步数的准确度。
6.训练结束后保存模型以供将来使用。
7.在新数据上测试模型并检查其执行情况。
我们的问题是识别来自给定的28x28图像的数字。我们有一部分图像用于训练,剩下的则用于测试我们的模型。所以首先下载数据集,数据集包含数据集中所有图像的压缩文件:train.csv和test.csv。数据集中不提供任何附加功能,只是以“.png”格式的原始图像。
我们将使用TensorFlow来建立一个神经网络模型。所以你应该先在你的系统中安装TensorFlow。 根据你的系统规格,请参阅官方安装指南进行安装。
我们将按照上述模板进行操作。用Python 2.7内核创建一个Jupyter笔记本,并按照下面的步骤。
导入所有必需的模块:

设置初始值,以便我们可以控制模型的随机性:

第一步是设置保管目录路径:

让我们看看数据集。这些格式为CSV格式,并且具有相应标签的文件名:

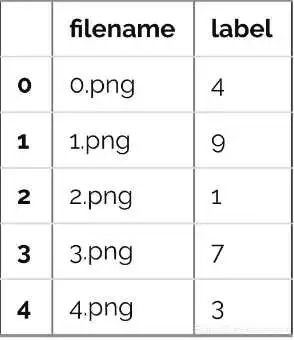
让我们看看我们的数据是什么样的!


上面的图像表示为numpy数组,如下所示:
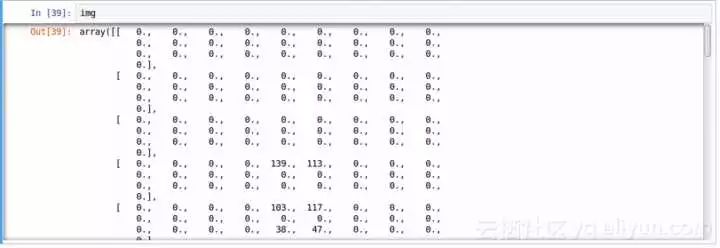
为了更简单的数据处理,让我们将所有的图像存储为numpy数组:
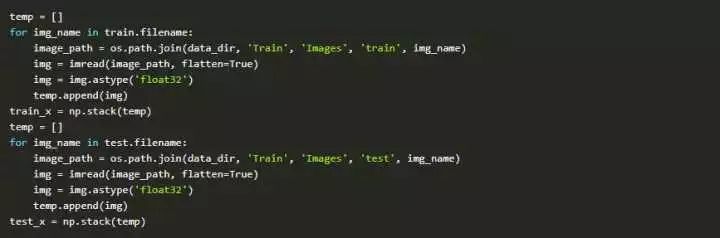
由于这是一个典型的ML问题,为了测试我们模型的正确功能,我们创建了一个验证集。

现在,我们定义一些辅助函数,我们稍后使用它:
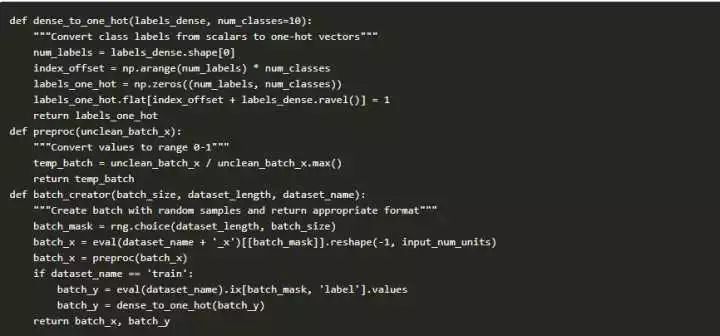
我们来定义我们的神经网络架构。我们定义了一个三层神经网络:输入,隐藏和输出。输入和输出中神经元的数量是固定的,因为输入的是28x28图像,输出的是10x1向量。我们隐藏层中有500个神经元。这个数字可以根据你的需要而有所不同。
阅读文章(http://t.cn/RYRNUS6)以获得完整的代码,并深入了解它的工作原理。

上海交通大学博士讲师团队
从算法到实战应用
涵盖CV领域主要知识点
手把手项目演示
全程提供代码
深度剖析CV研究体系
轻松实战深度学习应用领域!
▼▼▼
(限时早鸟票~)

新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据,教程,论文】
TensorFlow全新的数据读取方式:Dataset API入门教程
▼▼▼




