前沿 | DeepMind改进超参数优化:遗传算法效果超越贝叶斯
编译 | 林椿眄
从围棋、Atari游戏到图像识别、语言翻译领域,神经网络都已经取得了重大的突破。但是,经常被人忽略的是,神经网络的成功是在特定的应用情景下所取得,这些情景通常是在一系列研究的开始就确定好了的设置,包括所使用的神经网络的类型,所使用的数据以及训练的方法等。如今,这些设置,也被称为超参数,通常可以通过经验,随机搜索或者大规模的研究过程来决定。
在最新发表的文章中,我们介绍了一种新的训练神经网络的方法,这种方法能够帮助研究者快速地选择最适用于此任务的超参数和模型。
这种技术,被称为基于种群的训练方法(PBT),能够同时训练并优化一些的神经网络,以便快速地寻找到最佳的网络配置。更重要地是,这种方法不会增加计算的成本,能够像传统方法那样快速地得到结果,还能很容易地整合到现有的机器学习方法中。
该技术是两种最常用的超参数优化方法的混合体:随机搜索和手动微调法。
在随机搜索法中,一群神经网络会被同时独立地训练,并在训练结束后选出训练性能最佳的那个模型。通常情况下,只有很少一部分的神经网络训练后能够得到良好的超参数配置,而绝大部分神经网络训练后得到的超参数都是不良的,这无疑是在浪费计算力资源。
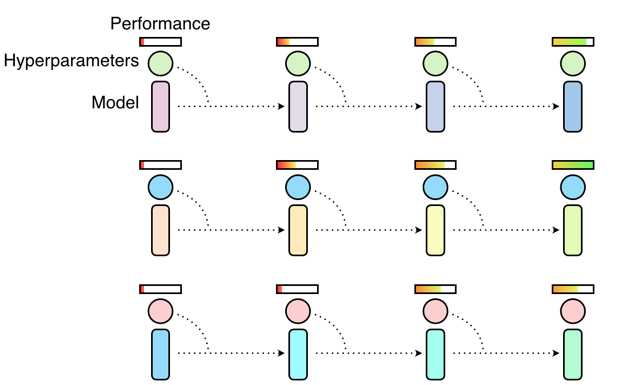

诸如手动微调和贝叶斯优化的方法,都是通过连续地多次训练过程来对超参数做出调整,这使得这些方法变得耗时。
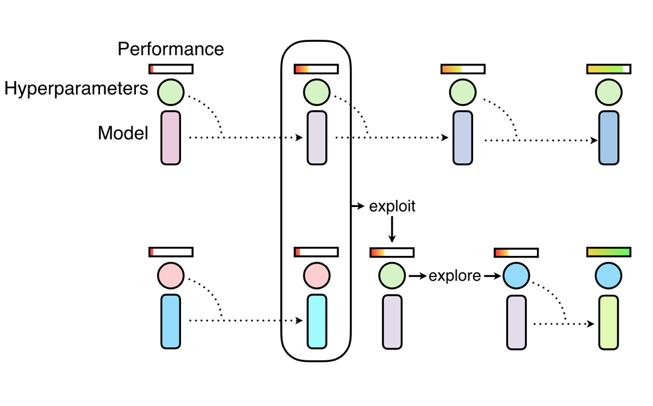
基于种群的神经网络训练方法,像随机搜索法一样开始训练,还能允许一个工人挖掘其他工人的部分结果并在训练过程探索新的超参数。
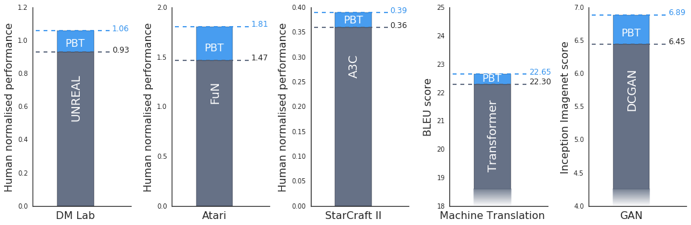
我们还发现,基于种群的训练方法能够更有效地训练生成对抗网络。这是个众所周知很难进行微调的难题。具体地说,我们使用基于种群的训练框架来最大化Inception Score值,一种视觉保真度的度量。对此,结果有显著的改善,Inception Score值从6.45增至6.9。
运用种群算法,我们在CIFAR-10数据库训练GANs和Ms Pacman数据库训练Feudal Networks (FuN)的变化情况。粉红色的点代表初始状态,蓝色的店则代表最终状态。
原文链接:
https://deepmind.com/blog/population-based-training-neural-networks/
资源推荐
资源 | Yann LeCun最新演讲:大脑是如何高效学习的?(附PPT+视频)
重磅 | 128篇论文,21大领域,深度学习最值得看的资源全在这了
爆款 | Medium上6900个赞的AI学习路线图,让你快速上手机器学习
Quora十大机器学习作者与Facebook十大机器学习、数据科学群组
Chatbot大牛推荐:AI、机器学习、深度学习必看9大入门视频
葵花宝典之机器学习:全网最重要的AI资源都在这里了(大牛,研究机构,视频,博客,书籍,Quora......)