人类没法下了!DeepMind贝叶斯优化调参AlphaGo,自弈胜率大涨16.5%

新智元报道
新智元报道
来源:arxiv
编译:大明
【新智元导读】AlphaGo的开发和运行涉及海量数据的多次调参,由于数据规模和复杂度的要求,采用手动调参估计需要8.3天。研究人员使用贝叶斯优化作为自动调参解决方案,效果明显,自对弈测试中的胜率从50%提高至66.5%,这下人类更没法下了。
在AlphaGo的开发过程中,它的许多超参数都经过多次贝叶斯优化调整。这种自动调参过程使其棋力显著提高。在与李世乭的比赛之前,我们调整了最新的AlphaGo的参数,并在自弈对局测试中将胜率从50%提高到66.5%。
这个经过调整的版本在最后一局比赛中应用。当然,由于我们在开发周期中多次调整AlphaGo的参数,因此实际上的棋力提升效果更为明显。我们希望这个案例研究将引起围棋爱好者的兴趣,同时也为贝叶斯优化相关从业者提供一些见解和灵感。
为什么AlphaGo调参用贝叶斯优化?手动调参需要8.3天
在AlphaGo的设计和开发过程中,贝叶斯优化作为一项常规方式,经常对AlphaGo超参数进行调整,提升棋力。特别是,贝叶斯优化成为AlphaGo与李世乭引人注目比赛中的重要因素。
AlphaGo的运行可以用两个阶段来概括:神经网络训练和蒙特卡罗树搜索(MCTS)。其中每一个阶段都存在许多超参数。我们主要注意调整与游戏相关的超参数。
我们之所以这样做,是因为掌握了性能强大的神经网络的调节策略,但是在游戏过程中如何调整AlphaGo的人类知识较少。我们对AlphaGo的许多组件进行了元优化。
值得注意的是,我们调整了MCTS超参数,包括管理UCT勘探公式,节点扩展阈值,与MCTS分布式实施相关的几个超参数,以及快速推出和快速推出之间选择公式的超参数。每次移动的价值网络评估。我们还调整了与策略和价值网络评估相关的超参数。
最后,我们对一个公式进行了元优化,以确定游戏过程中每次行棋的搜索时间。根据调整任务属性不同,要调整的超参数的数量从3到10不等。
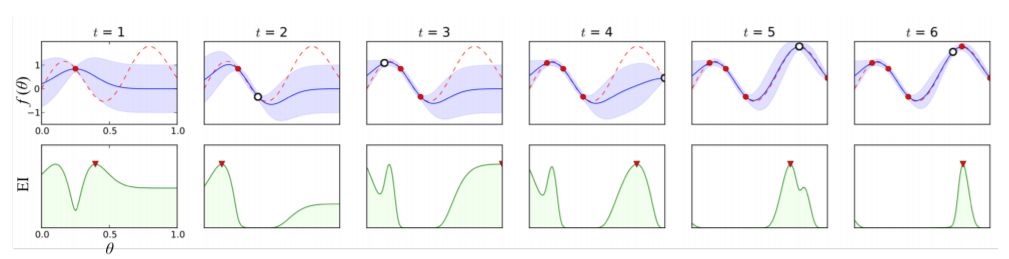
图1:在前6次迭代中使用高斯过程(GP)和预期改进获取(EI)函数的贝叶斯优化的一维化表示。上图所示为GP的均值(蓝色)和真正的未知函数(红色)。在查询点附近,不确定性降低。下图为EI采集函数及其建议的下一个查询点。
在应用贝叶斯优化之前,我们尝试使用网格搜索来调整AlphaGo的超参数。具体来说,对于每个超参数,我们构建了一个有效值网格,并在当前版本v和固定基线v0之间运行自对弈。对于每个值,我们运行了1000局对局。
这些对局中每次行棋的时间固定为5秒。进行一场对局大约需要20分钟。通过使用400个GPU将游戏与几个工作者并行化,大约需要6.7小时来估算单个超参数值的胜率p(θ)。
如果要进行6个超参数的优化,每个参数取5个可能的值,总共需要8.3天。如此高的调参成本是我们采用贝叶斯优化的重要原因。
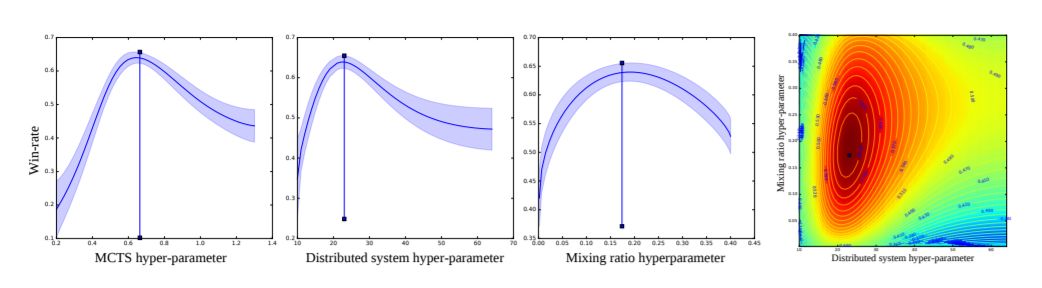
图2:最左边三个图:估计三个单独超参数的胜率的后验均值和方差,同时修复剩余的超参数。垂直条所示为固定的参考参数值。最右边的图:两个超参数的后验均值,表示这些参数之间的相关性
我们使用改进版的Spearmint进行输入变形,进行贝叶斯优化。超参数调整过程可由算法1表示(下图)。

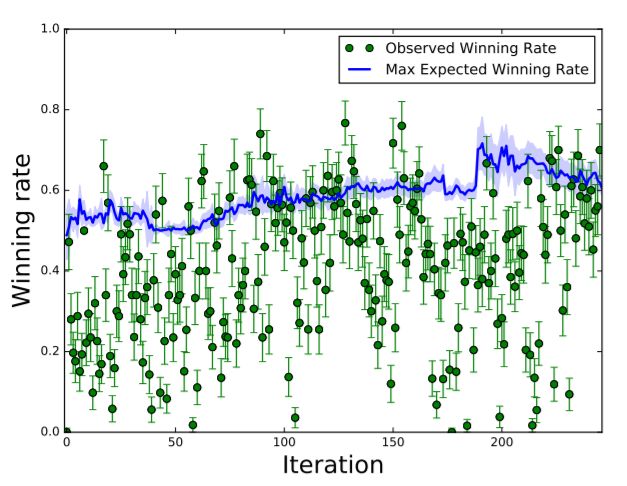
图3:作为优化步骤函数的观察值和最大预期胜率的典型值
实验方法和测试任务
任务1:调整MCTS超参数
我们优化了MCTS超参数,用于管理UCT勘探公式、网络输出回火以及快速输出值和网络输出值之间的混合比。要调整的超参数的数量从3到10不等。
AlphaGo的开发涉及许多设计迭代过程。在完成AlphaGo版本开发之后,我们通过贝叶斯优化和自我对弈对其进行了改进。在每次设计迭代开始时,胜率为50%。然而,通过调整MCTS超参数,在与李世乭比赛之前的两次设计迭代中,胜率增加到63.2%和64.4%(即Elo分数提高了94、103分)。
重要的是,每次我们调整版本时,所获得的知识(包括超参数值)都会传递给下一版本AlphaGo的开发团队。在与李世乭的比赛结束后,我们继续优化MCTS超参数,继续增强AlphaGo的棋力。
任务2:调整面向快棋的AlphaGo用于数据生成
我们运行了行棋时间很短的自弈对局,来生成策略和价值网络的训练数据集,与常规行棋时间对局不同,快速对局每步棋限时0.25秒。 AlphaGo在各种版本上的改进取决于这些数据集的质量。因此,快速的数据生成必须尽可能具备强大性能。在这个特殊的时间设置下,最佳的超参数值会发生很大变化,如果没有适当的先验知识,手动调参就会受到限制。在调整不同的快棋版本后,四个关键版本的Elo收益分别为300、285、145和129。
任务3:调整TPU
张量处理单元(TPU)可以提供比GPU更快的网络评估速度。
迁移到新硬件后,AlphaGo的性能大幅提升。然而,现有超参数的最佳值发生了改变,并且在分布式TPU实现中还出现了新的超参数。贝叶斯优化在早期的TPU实现中产生了更大幅度的Elo分数提升
任务4:开发并调整动态混合比例公式
早期版本的AlphaGo使用快速输出值和网络输出值评估之间的恒定混合比,无论对局的阶段和搜索时间如何变化,这个比例都是不变的。这显然是不是最优选择,但我们一直缺乏适当的技术来寻找最优的混合函数。通过引入贝叶斯优化,我们可以定义更灵活的公式,并寻找和调整最佳公式的参数。
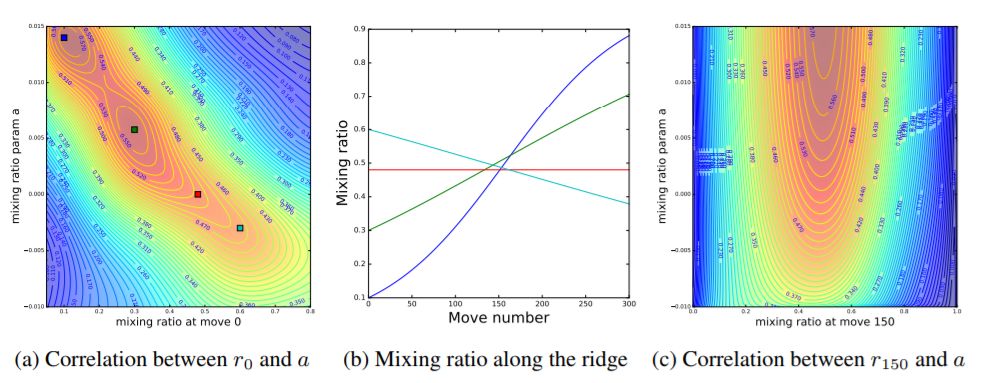
图4b所示为对应于图b中的四个点的四个混合比对移动数曲线。这表明在150手附近找到混合比的良好值是很重要的。这一发现与AlphaGo自对弈中的关键手通常发生在150手至200手之间的观察结果相一致。
任务5:调整时间控制公式
MCTS是一种随时可用的算法,其树搜索可以在任何时候中断,返回当前的最佳选择。为了准备与李世乭的正式比赛,我们希望能够优化所有动作的搜索时间分配,比赛主时间为2小时,每个玩家有3个60秒的读秒时段。我们将时间分配也视为优化问题,以便最大化地提升胜率。
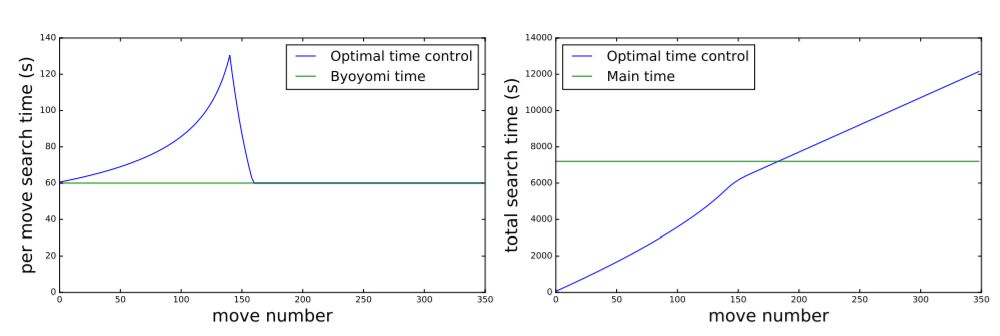
调整所有超参数后的最佳效果如图所示
AlphaGo在默认时间设置下获得66.5%的胜率,每步棋的行棋时间固定为30秒。
未来:继续开发具有MCTS的AI对弈智能体
贝叶斯优化为AlphaGo的超参数调节提供了一种自动化的解决方案。因为传统的手动调参耗时过长,不具备实现的可能。贝叶斯优化对AlphaGo的胜率提升做出了重大贡献,并帮助我们获得了重要的见解,这些见解继续有助于开发具有MCTS的新版本的AI对弈智能体。
论文地址:
https://arxiv.org/pdf/1812.06855.pdf
更多阅读:
【加入社群】
新智元 AI 技术 + 产业社群招募中,欢迎对 AI 技术 + 产业落地感兴趣的同学,加小助手微信号:aiera2015_2 入群;通过审核后我们将邀请进群,加入社群后务必修改群备注(姓名 - 公司 - 职位;专业群审核较严,敬请谅解)。


