刷新五项SOTA,百度ActBERT:基于动作和局部物体的视频文本特征学习模型
机器之心编辑部
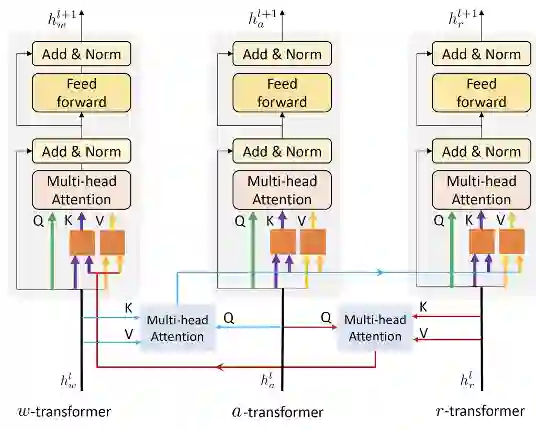
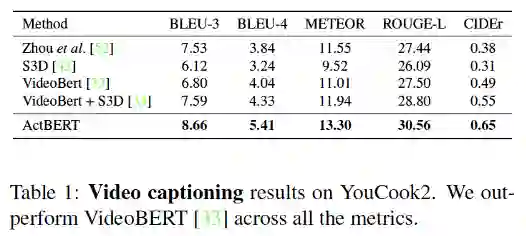
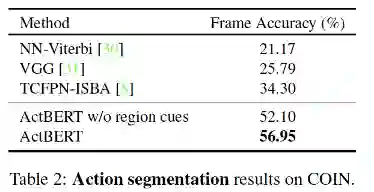
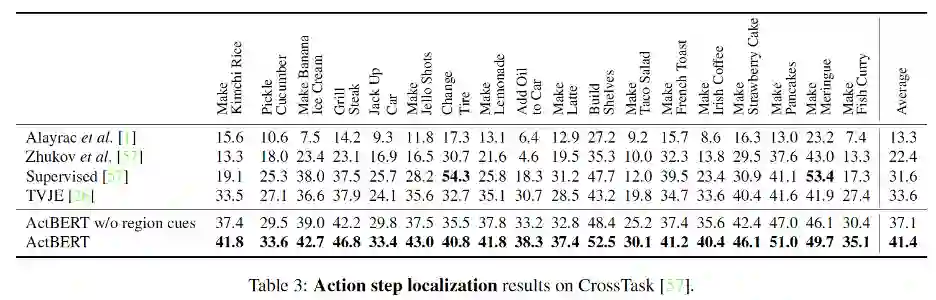
全球计算机视觉顶会 CVPR 2020 上,百度共计有 22 篇论文被接收。这篇 Oral 论文中,百度提出了 ActBERT,该模型可以学习叙述性视频进行无监督视频文本关系,并提出纠缠编码器对局部区域、全局动作与语言文字进行编码。最终在 5 项相关测评任务上取得了 SOTA 结果。

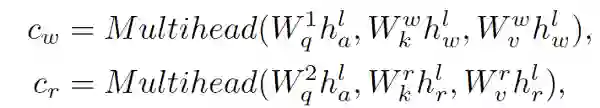

登录查看更多
相关内容
Arxiv
7+阅读 · 2019年2月3日

相关VIP内容
相关资讯
相关论文
Arxiv
7+阅读 · 2019年2月3日