加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
转自机器之心,已获得授权,不得二次转载
作者:Maël Fabie
机器之心编译,参与:Panda
为自然语言处理领域创造了突破性进展的 BERT 模型开始进军视频分析和预测领域了!近日,谷歌的 AI 博客介绍了他们在这方面的两项研究成果 VideoBERT 和 CBT。其中 VideoBERT 可以很好地学习视频和 ASR 输出文本之间的语义对应关系,还能根据这种关系预测视频内容的后续发展。而 CBT 在长序列表征学习上表现更好,在视频预测与视频描述上显著优于 LSTM 和平均池化方法。另外,这两种方法都采用了自监督的训练方式。
尽管人类可以轻松地识别视频中发生的活动以及预测接下来可能发生的事件,但对机器而言这样的任务却要困难得多。然而,对于时间定位、动作检测和自动驾驶汽车导航等应用,理解视频的内容和动态对机器来说也越来越重要。为了训练神经网络执行这样的任务,使用监督式训练是常用的方法,其中训练数据由人逐帧精心标注的视频组成。这样的标注难以大规模地获取。因此,人们对自监督学习有非常浓厚的兴趣。使用这类方法,模型可以在各种代理任务上训练,而且这些任务的监督自然地存在于数据本身之中。
谷歌的研究者提出了使用无标注视频学习时间表征的方法,他们的研究成果发布在论文《VideoBERT:一种用于视频和语言表征学习的联合模型(VideoBERT)》与《用于时间表示学习的对比双向 Transformer(CBT)》中。据介绍,他们的目标是发现对应于更长时间尺度上的动作和事件的高层面语义特征。为了实现这一目标,他们借用了人类语言使用高级词汇来描述高层面的事物和事件的思路。在视频中,语音往往与视觉信号存在时间上的对应,而且可以通过现成的自动语音识别(ASR)系统提取出来,由此可作为自监督的一个自然来源。所以,谷歌这些研究者设计的模型的学习是跨模态的,因为其在训练过程中会联合使用视觉和音频(语音)模态的信号。
![]()
来自同一视频位置的图像帧和人类语音往往是语义对齐的。这种对齐并不是彻底详尽的,有时会充满噪声,在更大的数据集上进行预训练有望缓解这一问题。在左边的示例中,ASR 的输出是「这样一直压紧地卷,将空气从旁边挤出去,你也可以把它拉长一点点。」这里语音描述了动作,但没有描述目标事物是什么。在右边的示例中,ASR 的输出是「这里你必须耐心耐心耐心」,与视觉内容完全无关。
用于视频的BERT模型
表征学习的第一步是定义一个代理任务(proxy task),让模型可以通过长的无标注视频学习时间动态以及跨模态的语义对应。为此,研究者将 BERT 模型扩展到了视频领域。BERT 模型使用了 transformer 架构来编码长序列,并在包含大量文本的语料库上进行了预训练,已经在多种不同的自然语言处理任务上取得了当前最佳的表现。BERT 使用完形填空测试(cloze test)作为其代理任务。在该任务中,BERT 的目标是根据双向的上下文预测缺失的词,而不仅仅是预测某个序列的下一个词。
为了将 BERT 用于视频任务,研究者扩展了 BERT 的训练目标,组合使用同一位置的图像帧与 ASR 句子输出来组建跨模态的「句子」。其中图像帧根据视觉特征相似度被转换成了持续时间为 1.5 秒的视觉 token,然后再与 ASR 词 token 相连接。基于这些数据,研究者训练了 VideoBERT 模型来基于视觉-文本句子填补缺失的 token。研究者假设,通过在这种代理任务上进行预训练,模型可以学习推理更长程的时间动态(视觉完形填空)和高层面的语义(视觉-文本完形填空)。他们的实验结果支持这一假设。
![]()
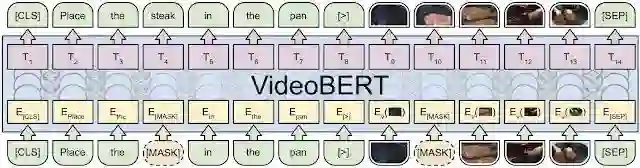
视频和文本被遮蔽 token 预测(完形填空)任务中的 ViderBERT 示意图。底部:来自视频同一位置的视觉和文本(ASR)token 被连接起来组成 VideoBERT 的输入。其中某些视觉和文本 token 被遮挡了。中部:VideoBERT 使用 Transformer 架构来联合编码双向的视觉-文本上下文。黄色框和粉色框分别对应于输入嵌入和输出嵌入。顶部:训练目标是恢复被掩盖位置的正确 token。
检查 VideoBERT模型
训练 VideoBERT 的数据是超过 100 万条教学视频,比如烹饪、园艺和车辆维修。训练完成后,可以在一些任务上检查 VideoBERT 学到了什么,以验证其输出能否准确地反映视频内容。举个例子,文本到视频预测可用于根据视频自动生成一组指令(比如食谱),得到反映每一步所描述内容的视频片段(token)。此外,视频到视频预测可用于基于初始视频 token 可视化未来的可能内容。
![]()
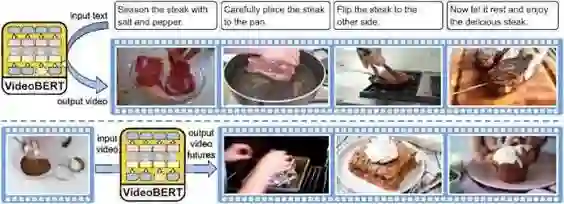
在烹饪视频上预训练的 VideoBERT 的定性结果。上:给定一些食谱文本,生成一系列视觉 token。下:给定一个视觉 token,展示了 VideoBERT 在不同的时间尺度上排名前三的未来 token。在这个案例中,该模型预测一碗面粉和可可粉可能进入烤箱烘烤,也可能变成布朗尼或纸杯蛋糕。视觉 token 的可视化使用了离特征空间中 token 最近的训练集的图像。
为了验证 VideoBERT 能否学习到视频和文本之间的语义对应关系,研究者在一个烹饪视频数据集上测试了其「zero-shot」分类准确度——这个数据集中的视频和标注都没有在预训练过程中使用过。为了执行分类,视频 token 与模板句子「now let me show you how to [MASK] the [MASK]」连接起来,预测的动词和名字被提取了出来。VideoBERT 模型的结果可媲美全监督基准方法的 top-5 准确度,这说明该模型有能力在「zero-shot」设置中取得有竞争力的表现。
使用对比双向 Transformer进行迁移学习
尽管 VideoBERT 在学习如何自动标注和预测视频内容方面表现出色,但研究者也注意到 VideoBERT 所使用的视觉 token 可能丢失细粒度的视觉信息,比如更小的目标和细微的动作。为了探究这一问题,研究者又提出了对比双向 Transformer(CBT)模型。该模型移除了 token 化步骤。然后研究者进一步通过在下游任务上的迁移学习评估了所学习到的表征的质量。CBT 应用了一种不同的损失函数——对比损失(contrastive loss),可用于最大化被掩盖位置与跨模态句子其余部分之间的互信息。研究者在不同的任务(比如动作分割、动作预测和视频描述)以及多个视频数据集上评估了学习到的表征。结果表明,CBT 方法在大多数基准上都显著优于之前最佳。可以观察到:(1)跨模态目标对迁移学习的表现很重要;(2)更大更多样化的预训练集能得到更好的表征;(3)与平均池化或 LSTM 等基准方法相比,CBT 模型在利用长时间上下文方面要好得多。
![]()
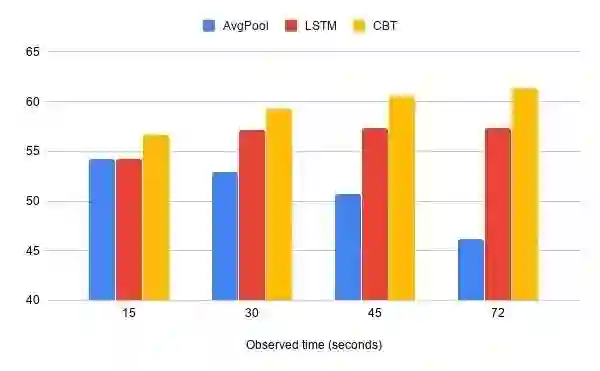
使用 CBT 方法在包含 200 个活动类别的未调整视频上的动作预测准确度。另外还报告了平均池化与 LSTM 的结果以作比较。所报告结果的观察时间为 15、30、45、72 秒。
总结和未来研究
通过这两项研究,BERT 模型在基于无标注视频学习视觉-语言和视觉表征方面的能力得到了证明。研究发现,新提出的模型 VideoBERT 和 CBT 不仅可用于 zero-shot 动作分类和食谱生成,而且所学习到的时间表征也能很好地迁移到多种下游任务,比如动作预测。未来的研究方向包括与长期的时间表征一起联合学习低层面的视觉特征,这能实现对视频上下文的更好的适应性。此外,研究者还计划对预训练视频集进行扩展,使其更大更多样化。
原文链接:https://ai.googleblog.com/2019/09/learning-cross-modal-temporal.html
-End-
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~
![]()
△长按添加极市小助手
![]()
△长按关注极市平台
觉得有用麻烦给个在看啦~ ![]()